 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePathwise Test-Time Correction for Autoregressive Long Video Generation
Feb 05, 2026Distilled autoregressive diffusion models facilitate real-time short video synthesis but suffer from severe error accumulation during long-sequence generation. While existing Test-Time Optimization (TTO) methods prove effective for images or short clips, we identify that they fail to mitigate drift in extended sequences due to unstable reward landscapes and the hypersensitivity of distilled parameters. To overcome these limitations, we introduce Test-Time Correction (TTC), a training-free alternative. Specifically, TTC utilizes the initial frame as a stable reference anchor to calibrate intermediate stochastic states along the sampling trajectory. Extensive experiments demonstrate that our method seamlessly integrates with various distilled models, extending generation lengths with negligible overhead while matching the quality of resource-intensive training-based methods on 30-second benchmarks.
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Dec 16, 2025This paper presents WorldPlay, a streaming video diffusion model that enables real-time, interactive world modeling with long-term geometric consistency, resolving the trade-off between speed and memory that limits current methods. WorldPlay draws power from three key innovations. 1) We use a Dual Action Representation to enable robust action control in response to the user's keyboard and mouse inputs. 2) To enforce long-term consistency, our Reconstituted Context Memory dynamically rebuilds context from past frames and uses temporal reframing to keep geometrically important but long-past frames accessible, effectively alleviating memory attenuation. 3) We also propose Context Forcing, a novel distillation method designed for memory-aware model. Aligning memory context between the teacher and student preserves the student's capacity to use long-range information, enabling real-time speeds while preventing error drift. Taken together, WorldPlay generates long-horizon streaming 720p video at 24 FPS with superior consistency, comparing favorably with existing techniques and showing strong generalization across diverse scenes. Project page and online demo can be found: https://3d-models.hunyuan.tencent.com/world/ and https://3d.hunyuan.tencent.com/sceneTo3D.
MoCA: Mixture-of-Components Attention for Scalable Compositional 3D Generation
Dec 08, 2025Compositionality is critical for 3D object and scene generation, but existing part-aware 3D generation methods suffer from poor scalability due to quadratic global attention costs when increasing the number of components. In this work, we present MoCA, a compositional 3D generative model with two key designs: (1) importance-based component routing that selects top-k relevant components for sparse global attention, and (2) unimportant components compression that preserve contextual priors of unselected components while reducing computational complexity of global attention. With these designs, MoCA enables efficient, fine-grained compositional 3D asset creation with scalable number of components. Extensive experiments show MoCA outperforms baselines on both compositional object and scene generation tasks. Project page: https://lizhiqi49.github.io/MoCA
HunyuanWorld 1.0: Generating Immersive, Explorable, and Interactive 3D Worlds from Words or Pixels
Jul 29, 2025



Creating immersive and playable 3D worlds from texts or images remains a fundamental challenge in computer vision and graphics. Existing world generation approaches typically fall into two categories: video-based methods that offer rich diversity but lack 3D consistency and rendering efficiency, and 3D-based methods that provide geometric consistency but struggle with limited training data and memory-inefficient representations. To address these limitations, we present HunyuanWorld 1.0, a novel framework that combines the best of both worlds for generating immersive, explorable, and interactive 3D scenes from text and image conditions. Our approach features three key advantages: 1) 360{\deg} immersive experiences via panoramic world proxies; 2) mesh export capabilities for seamless compatibility with existing computer graphics pipelines; 3) disentangled object representations for augmented interactivity. The core of our framework is a semantically layered 3D mesh representation that leverages panoramic images as 360{\deg} world proxies for semantic-aware world decomposition and reconstruction, enabling the generation of diverse 3D worlds. Extensive experiments demonstrate that our method achieves state-of-the-art performance in generating coherent, explorable, and interactive 3D worlds while enabling versatile applications in virtual reality, physical simulation, game development, and interactive content creation.
Voyager: Long-Range and World-Consistent Video Diffusion for Explorable 3D Scene Generation
Jun 04, 2025Real-world applications like video gaming and virtual reality often demand the ability to model 3D scenes that users can explore along custom camera trajectories. While significant progress has been made in generating 3D objects from text or images, creating long-range, 3D-consistent, explorable 3D scenes remains a complex and challenging problem. In this work, we present Voyager, a novel video diffusion framework that generates world-consistent 3D point-cloud sequences from a single image with user-defined camera path. Unlike existing approaches, Voyager achieves end-to-end scene generation and reconstruction with inherent consistency across frames, eliminating the need for 3D reconstruction pipelines (e.g., structure-from-motion or multi-view stereo). Our method integrates three key components: 1) World-Consistent Video Diffusion: A unified architecture that jointly generates aligned RGB and depth video sequences, conditioned on existing world observation to ensure global coherence 2) Long-Range World Exploration: An efficient world cache with point culling and an auto-regressive inference with smooth video sampling for iterative scene extension with context-aware consistency, and 3) Scalable Data Engine: A video reconstruction pipeline that automates camera pose estimation and metric depth prediction for arbitrary videos, enabling large-scale, diverse training data curation without manual 3D annotations. Collectively, these designs result in a clear improvement over existing methods in visual quality and geometric accuracy, with versatile applications.
Hunyuan3D 2.0: Scaling Diffusion Models for High Resolution Textured 3D Assets Generation
Jan 21, 2025



We present Hunyuan3D 2.0, an advanced large-scale 3D synthesis system for generating high-resolution textured 3D assets. This system includes two foundation components: a large-scale shape generation model -- Hunyuan3D-DiT, and a large-scale texture synthesis model -- Hunyuan3D-Paint. The shape generative model, built on a scalable flow-based diffusion transformer, aims to create geometry that properly aligns with a given condition image, laying a solid foundation for downstream applications. The texture synthesis model, benefiting from strong geometric and diffusion priors, produces high-resolution and vibrant texture maps for either generated or hand-crafted meshes. Furthermore, we build Hunyuan3D-Studio -- a versatile, user-friendly production platform that simplifies the re-creation process of 3D assets. It allows both professional and amateur users to manipulate or even animate their meshes efficiently. We systematically evaluate our models, showing that Hunyuan3D 2.0 outperforms previous state-of-the-art models, including the open-source models and closed-source models in geometry details, condition alignment, texture quality, and etc. Hunyuan3D 2.0 is publicly released in order to fill the gaps in the open-source 3D community for large-scale foundation generative models. The code and pre-trained weights of our models are available at: https://github.com/Tencent/Hunyuan3D-2
Large Point-to-Gaussian Model for Image-to-3D Generation
Aug 20, 2024


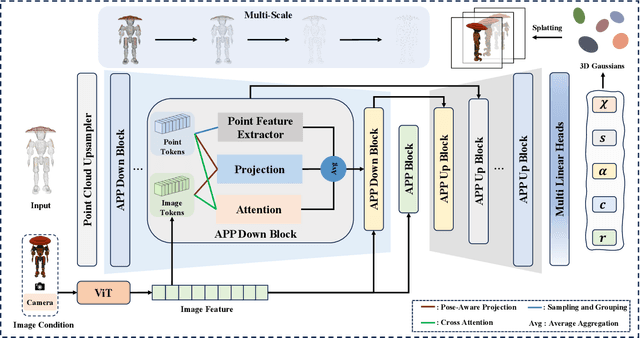
Recently, image-to-3D approaches have significantly advanced the generation quality and speed of 3D assets based on large reconstruction models, particularly 3D Gaussian reconstruction models. Existing large 3D Gaussian models directly map 2D image to 3D Gaussian parameters, while regressing 2D image to 3D Gaussian representations is challenging without 3D priors. In this paper, we propose a large Point-to-Gaussian model, that inputs the initial point cloud produced from large 3D diffusion model conditional on 2D image to generate the Gaussian parameters, for image-to-3D generation. The point cloud provides initial 3D geometry prior for Gaussian generation, thus significantly facilitating image-to-3D Generation. Moreover, we present the \textbf{A}ttention mechanism, \textbf{P}rojection mechanism, and \textbf{P}oint feature extractor, dubbed as \textbf{APP} block, for fusing the image features with point cloud features. The qualitative and quantitative experiments extensively demonstrate the effectiveness of the proposed approach on GSO and Objaverse datasets, and show the proposed method achieves state-of-the-art performance.
Collaborative Tracking Learning for Frame-Rate-Insensitive Multi-Object Tracking
Aug 11, 2023



Multi-object tracking (MOT) at low frame rates can reduce computational, storage and power overhead to better meet the constraints of edge devices. Many existing MOT methods suffer from significant performance degradation in low-frame-rate videos due to significant location and appearance changes between adjacent frames. To this end, we propose to explore collaborative tracking learning (ColTrack) for frame-rate-insensitive MOT in a query-based end-to-end manner. Multiple historical queries of the same target jointly track it with richer temporal descriptions. Meanwhile, we insert an information refinement module between every two temporal blocking decoders to better fuse temporal clues and refine features. Moreover, a tracking object consistency loss is proposed to guide the interaction between historical queries. Extensive experimental results demonstrate that in high-frame-rate videos, ColTrack obtains higher performance than state-of-the-art methods on large-scale datasets Dancetrack and BDD100K, and outperforms the existing end-to-end methods on MOT17. More importantly, ColTrack has a significant advantage over state-of-the-art methods in low-frame-rate videos, which allows it to obtain faster processing speeds by reducing frame-rate requirements while maintaining higher performance. Code will be released at https://github.com/yolomax/ColTrack