 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVD-HuGaS: Human Gaussians from a Single Image via 3D Human Multi-view Diffusion Prior
Mar 11, 2025



3D human reconstruction from a single image is a challenging problem and has been exclusively studied in the literature. Recently, some methods have resorted to diffusion models for guidance, optimizing a 3D representation via Score Distillation Sampling(SDS) or generating one back-view image for facilitating reconstruction. However, these methods tend to produce unsatisfactory artifacts (\textit{e.g.} flattened human structure or over-smoothing results caused by inconsistent priors from multiple views) and struggle with real-world generalization in the wild. In this work, we present \emph{MVD-HuGaS}, enabling free-view 3D human rendering from a single image via a multi-view human diffusion model. We first generate multi-view images from the single reference image with an enhanced multi-view diffusion model, which is well fine-tuned on high-quality 3D human datasets to incorporate 3D geometry priors and human structure priors. To infer accurate camera poses from the sparse generated multi-view images for reconstruction, an alignment module is introduced to facilitate joint optimization of 3D Gaussians and camera poses. Furthermore, we propose a depth-based Facial Distortion Mitigation module to refine the generated facial regions, thereby improving the overall fidelity of the reconstruction.Finally, leveraging the refined multi-view images, along with their accurate camera poses, MVD-HuGaS optimizes the 3D Gaussians of the target human for high-fidelity free-view renderings. Extensive experiments on Thuman2.0 and 2K2K datasets show that the proposed MVD-HuGaS achieves state-of-the-art performance on single-view 3D human rendering.
You See it, You Got it: Learning 3D Creation on Pose-Free Videos at Scale
Dec 09, 2024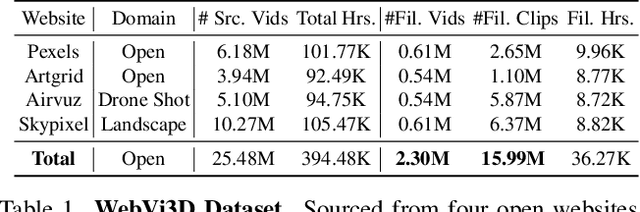
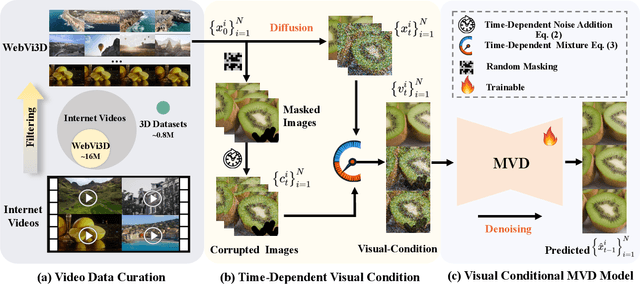
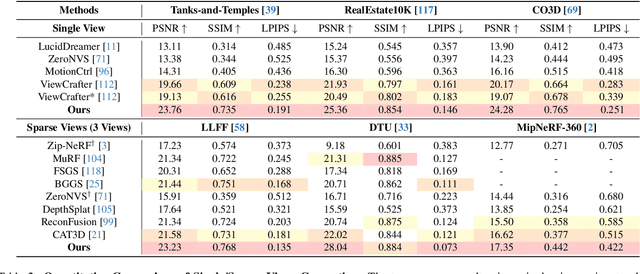

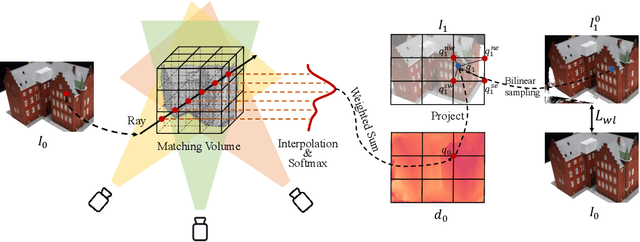
Recent 3D generation models typically rely on limited-scale 3D `gold-labels' or 2D diffusion priors for 3D content creation. However, their performance is upper-bounded by constrained 3D priors due to the lack of scalable learning paradigms. In this work, we present See3D, a visual-conditional multi-view diffusion model trained on large-scale Internet videos for open-world 3D creation. The model aims to Get 3D knowledge by solely Seeing the visual contents from the vast and rapidly growing video data -- You See it, You Got it. To achieve this, we first scale up the training data using a proposed data curation pipeline that automatically filters out multi-view inconsistencies and insufficient observations from source videos. This results in a high-quality, richly diverse, large-scale dataset of multi-view images, termed WebVi3D, containing 320M frames from 16M video clips. Nevertheless, learning generic 3D priors from videos without explicit 3D geometry or camera pose annotations is nontrivial, and annotating poses for web-scale videos is prohibitively expensive. To eliminate the need for pose conditions, we introduce an innovative visual-condition - a purely 2D-inductive visual signal generated by adding time-dependent noise to the masked video data. Finally, we introduce a novel visual-conditional 3D generation framework by integrating See3D into a warping-based pipeline for high-fidelity 3D generation. Our numerical and visual comparisons on single and sparse reconstruction benchmarks show that See3D, trained on cost-effective and scalable video data, achieves notable zero-shot and open-world generation capabilities, markedly outperforming models trained on costly and constrained 3D datasets. Please refer to our project page at: https://vision.baai.ac.cn/see3d
MVPGS: Excavating Multi-view Priors for Gaussian Splatting from Sparse Input Views
Sep 22, 2024
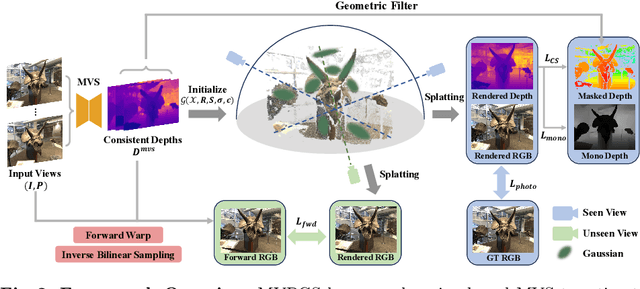
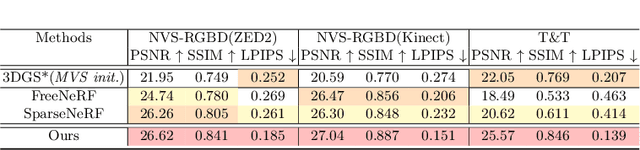
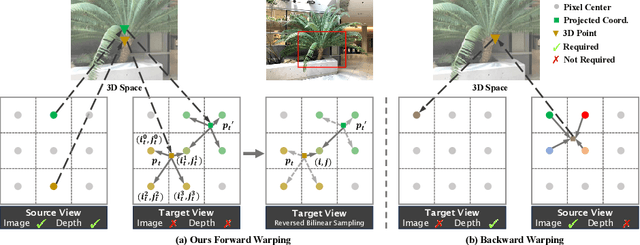
Recently, the Neural Radiance Field (NeRF) advancement has facilitated few-shot Novel View Synthesis (NVS), which is a significant challenge in 3D vision applications. Despite numerous attempts to reduce the dense input requirement in NeRF, it still suffers from time-consumed training and rendering processes. More recently, 3D Gaussian Splatting (3DGS) achieves real-time high-quality rendering with an explicit point-based representation. However, similar to NeRF, it tends to overfit the train views for lack of constraints. In this paper, we propose \textbf{MVPGS}, a few-shot NVS method that excavates the multi-view priors based on 3D Gaussian Splatting. We leverage the recent learning-based Multi-view Stereo (MVS) to enhance the quality of geometric initialization for 3DGS. To mitigate overfitting, we propose a forward-warping method for additional appearance constraints conforming to scenes based on the computed geometry. Furthermore, we introduce a view-consistent geometry constraint for Gaussian parameters to facilitate proper optimization convergence and utilize a monocular depth regularization as compensation. Experiments show that the proposed method achieves state-of-the-art performance with real-time rendering speed. Project page: https://zezeaaa.github.io/projects/MVPGS/
Surface-Centric Modeling for High-Fidelity Generalizable Neural Surface Reconstruction
Sep 05, 2024
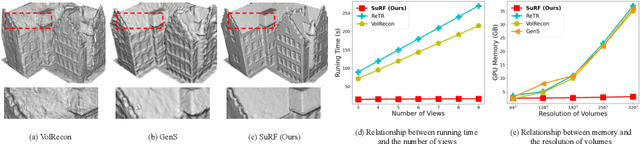
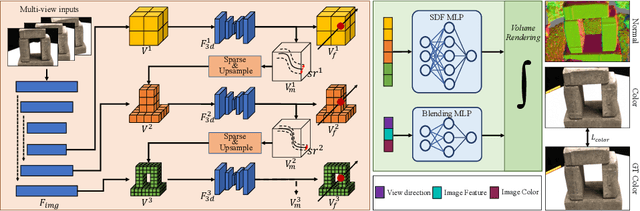
Reconstructing the high-fidelity surface from multi-view images, especially sparse images, is a critical and practical task that has attracted widespread attention in recent years. However, existing methods are impeded by the memory constraint or the requirement of ground-truth depths and cannot recover satisfactory geometric details. To this end, we propose SuRF, a new Surface-centric framework that incorporates a new Region sparsification based on a matching Field, achieving good trade-offs between performance, efficiency and scalability. To our knowledge, this is the first unsupervised method achieving end-to-end sparsification powered by the introduced matching field, which leverages the weight distribution to efficiently locate the boundary regions containing surface. Instead of predicting an SDF value for each voxel, we present a new region sparsification approach to sparse the volume by judging whether the voxel is inside the surface region. In this way, our model can exploit higher frequency features around the surface with less memory and computational consumption. Extensive experiments on multiple benchmarks containing complex large-scale scenes show that our reconstructions exhibit high-quality details and achieve new state-of-the-art performance, i.e., 46% improvements with 80% less memory consumption. Code is available at https://github.com/prstrive/SuRF.
Large Point-to-Gaussian Model for Image-to-3D Generation
Aug 20, 2024


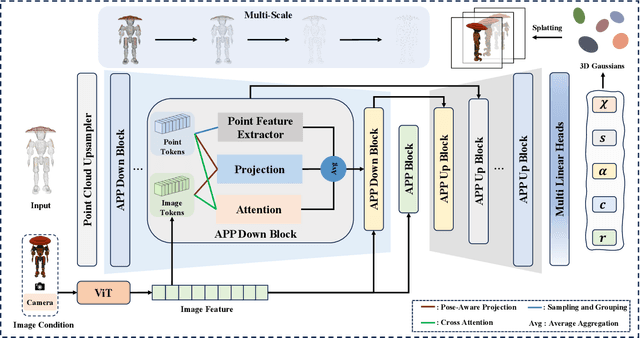
Recently, image-to-3D approaches have significantly advanced the generation quality and speed of 3D assets based on large reconstruction models, particularly 3D Gaussian reconstruction models. Existing large 3D Gaussian models directly map 2D image to 3D Gaussian parameters, while regressing 2D image to 3D Gaussian representations is challenging without 3D priors. In this paper, we propose a large Point-to-Gaussian model, that inputs the initial point cloud produced from large 3D diffusion model conditional on 2D image to generate the Gaussian parameters, for image-to-3D generation. The point cloud provides initial 3D geometry prior for Gaussian generation, thus significantly facilitating image-to-3D Generation. Moreover, we present the \textbf{A}ttention mechanism, \textbf{P}rojection mechanism, and \textbf{P}oint feature extractor, dubbed as \textbf{APP} block, for fusing the image features with point cloud features. The qualitative and quantitative experiments extensively demonstrate the effectiveness of the proposed approach on GSO and Objaverse datasets, and show the proposed method achieves state-of-the-art performance.