 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain of World: World Model Thinking in Latent Motion
Mar 03, 2026Vision-Language-Action (VLA) models are a promising path toward embodied intelligence, yet they often overlook the predictive and temporal-causal structure underlying visual dynamics. World-model VLAs address this by predicting future frames, but waste capacity reconstructing redundant backgrounds. Latent-action VLAs encode frame-to-frame transitions compactly, but lack temporally continuous dynamic modeling and world knowledge. To overcome these limitations, we introduce CoWVLA (Chain-of-World VLA), a new "Chain of World" paradigm that unifies world-model temporal reasoning with a disentangled latent motion representation. First, a pretrained video VAE serves as a latent motion extractor, explicitly factorizing video segments into structure and motion latents. Then, during pre-training, the VLA learns from an instruction and an initial frame to infer a continuous latent motion chain and predict the segment's terminal frame. Finally, during co-fine-tuning, this latent dynamic is aligned with discrete action prediction by jointly modeling sparse keyframes and action sequences in a unified autoregressive decoder. This design preserves the world-model benefits of temporal reasoning and world knowledge while retaining the compactness and interpretability of latent actions, enabling efficient visuomotor learning. Extensive experiments on robotic simulation benchmarks show that CoWVLA outperforms existing world-model and latent-action approaches and achieves moderate computational efficiency, highlighting its potential as a more effective VLA pretraining paradigm. The project website can be found at https://fx-hit.github.io/cowvla-io.
Driving in Spikes: An Entropy-Guided Object Detector for Spike Cameras
Nov 19, 2025Object detection in autonomous driving suffers from motion blur and saturation under fast motion and extreme lighting. Spike cameras, offer microsecond latency and ultra high dynamic range for object detection by using per pixel asynchronous integrate and fire. However, their sparse, discrete output cannot be processed by standard image-based detectors, posing a critical challenge for end to end spike stream detection. We propose EASD, an end to end spike camera detector with a dual branch design: a Temporal Based Texture plus Feature Fusion branch for global cross slice semantics, and an Entropy Selective Attention branch for object centric details. To close the data gap, we introduce DSEC Spike, the first driving oriented simulated spike detection benchmark.
PiCo: Jailbreaking Multimodal Large Language Models via $\textbf{Pi}$ctorial $\textbf{Co}$de Contextualization
Apr 02, 2025Multimodal Large Language Models (MLLMs), which integrate vision and other modalities into Large Language Models (LLMs), significantly enhance AI capabilities but also introduce new security vulnerabilities. By exploiting the vulnerabilities of the visual modality and the long-tail distribution characteristic of code training data, we present PiCo, a novel jailbreaking framework designed to progressively bypass multi-tiered defense mechanisms in advanced MLLMs. PiCo employs a tier-by-tier jailbreak strategy, using token-level typographic attacks to evade input filtering and embedding harmful intent within programming context instructions to bypass runtime monitoring. To comprehensively assess the impact of attacks, a new evaluation metric is further proposed to assess both the toxicity and helpfulness of model outputs post-attack. By embedding harmful intent within code-style visual instructions, PiCo achieves an average Attack Success Rate (ASR) of 84.13% on Gemini-Pro Vision and 52.66% on GPT-4, surpassing previous methods. Experimental results highlight the critical gaps in current defenses, underscoring the need for more robust strategies to secure advanced MLLMs.
You See it, You Got it: Learning 3D Creation on Pose-Free Videos at Scale
Dec 09, 2024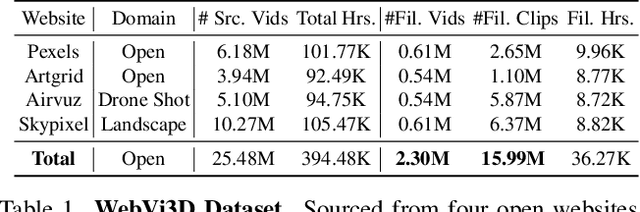
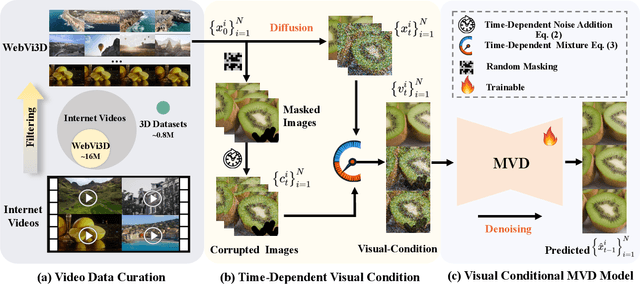
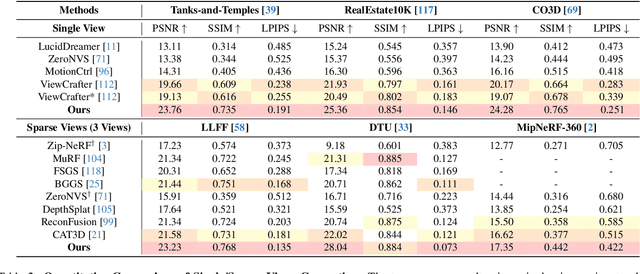

Recent 3D generation models typically rely on limited-scale 3D `gold-labels' or 2D diffusion priors for 3D content creation. However, their performance is upper-bounded by constrained 3D priors due to the lack of scalable learning paradigms. In this work, we present See3D, a visual-conditional multi-view diffusion model trained on large-scale Internet videos for open-world 3D creation. The model aims to Get 3D knowledge by solely Seeing the visual contents from the vast and rapidly growing video data -- You See it, You Got it. To achieve this, we first scale up the training data using a proposed data curation pipeline that automatically filters out multi-view inconsistencies and insufficient observations from source videos. This results in a high-quality, richly diverse, large-scale dataset of multi-view images, termed WebVi3D, containing 320M frames from 16M video clips. Nevertheless, learning generic 3D priors from videos without explicit 3D geometry or camera pose annotations is nontrivial, and annotating poses for web-scale videos is prohibitively expensive. To eliminate the need for pose conditions, we introduce an innovative visual-condition - a purely 2D-inductive visual signal generated by adding time-dependent noise to the masked video data. Finally, we introduce a novel visual-conditional 3D generation framework by integrating See3D into a warping-based pipeline for high-fidelity 3D generation. Our numerical and visual comparisons on single and sparse reconstruction benchmarks show that See3D, trained on cost-effective and scalable video data, achieves notable zero-shot and open-world generation capabilities, markedly outperforming models trained on costly and constrained 3D datasets. Please refer to our project page at: https://vision.baai.ac.cn/see3d
Tokenize Anything via Prompting
Dec 14, 2023We present a unified, promptable model capable of simultaneously segmenting, recognizing, and captioning anything. Unlike SAM, we aim to build a versatile region representation in the wild via visual prompting. To achieve this, we train a generalizable model with massive segmentation masks, e.g., SA-1B masks, and semantic priors from a pre-trained CLIP model with 5 billion parameters. Specifically, we construct a promptable image decoder by adding a semantic token to each mask token. The semantic token is responsible for learning the semantic priors in a predefined concept space. Through joint optimization of segmentation on mask tokens and concept prediction on semantic tokens, our model exhibits strong regional recognition and localization capabilities. For example, an additional 38M-parameter causal text decoder trained from scratch sets a new record with a CIDEr score of 150.7 on the Visual Genome region captioning task. We believe this model can be a versatile region-level image tokenizer, capable of encoding general-purpose region context for a broad range of perception tasks. Code and models are available at https://github.com/baaivision/tokenize-anything.
PU-EVA: An Edge Vector based Approximation Solution for Flexible-scale Point Cloud Upsampling
Apr 22, 2022


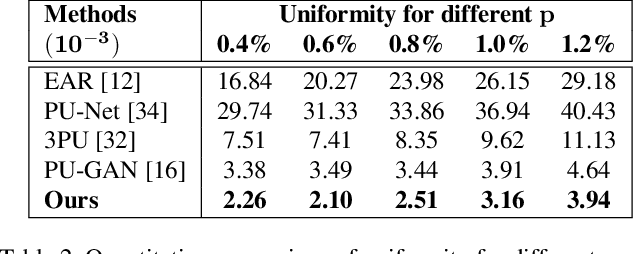
High-quality point clouds have practical significance for point-based rendering, semantic understanding, and surface reconstruction. Upsampling sparse, noisy and nonuniform point clouds for a denser and more regular approximation of target objects is a desirable but challenging task. Most existing methods duplicate point features for upsampling, constraining the upsampling scales at a fixed rate. In this work, the flexible upsampling rates are achieved via edge vector based affine combinations, and a novel design of Edge Vector based Approximation for Flexible-scale Point clouds Upsampling (PU-EVA) is proposed. The edge vector based approximation encodes the neighboring connectivity via affine combinations based on edge vectors, and restricts the approximation error within the second-order term of Taylor's Expansion. The EVA upsampling decouples the upsampling scales with network architecture, achieving the flexible upsampling rates in one-time training. Qualitative and quantitative evaluations demonstrate that the proposed PU-EVA outperforms the state-of-the-art in terms of proximity-to-surface, distribution uniformity, and geometric details preservation.
Point-BERT: Pre-training 3D Point Cloud Transformers with Masked Point Modeling
Nov 29, 2021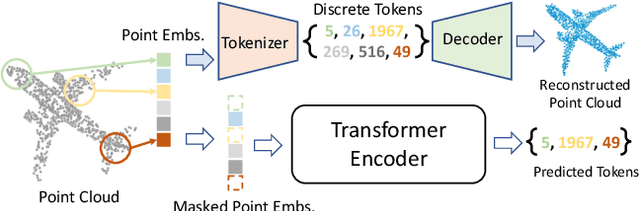
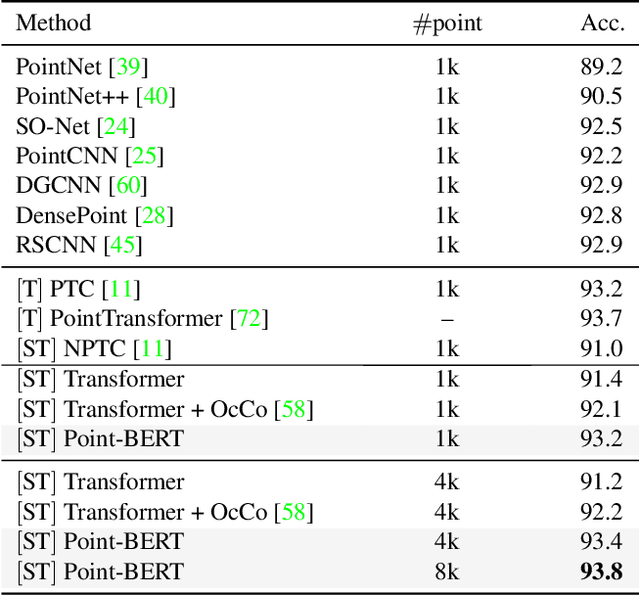
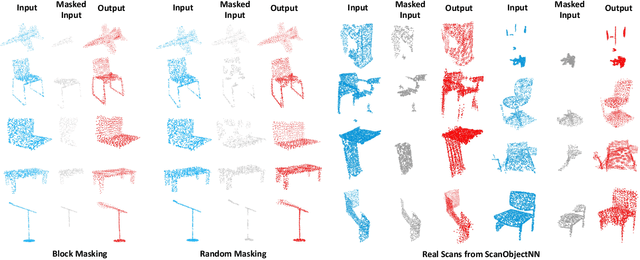
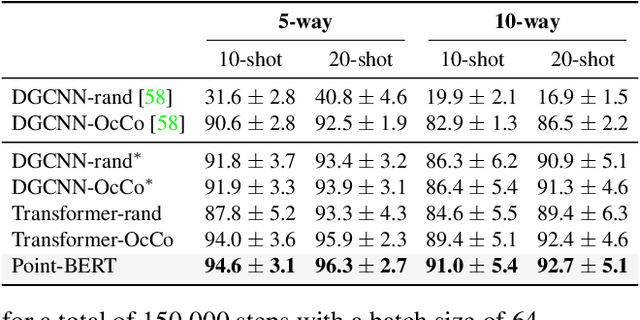
We present Point-BERT, a new paradigm for learning Transformers to generalize the concept of BERT to 3D point cloud. Inspired by BERT, we devise a Masked Point Modeling (MPM) task to pre-train point cloud Transformers. Specifically, we first divide a point cloud into several local point patches, and a point cloud Tokenizer with a discrete Variational AutoEncoder (dVAE) is designed to generate discrete point tokens containing meaningful local information. Then, we randomly mask out some patches of input point clouds and feed them into the backbone Transformers. The pre-training objective is to recover the original point tokens at the masked locations under the supervision of point tokens obtained by the Tokenizer. Extensive experiments demonstrate that the proposed BERT-style pre-training strategy significantly improves the performance of standard point cloud Transformers. Equipped with our pre-training strategy, we show that a pure Transformer architecture attains 93.8% accuracy on ModelNet40 and 83.1% accuracy on the hardest setting of ScanObjectNN, surpassing carefully designed point cloud models with much fewer hand-made designs. We also demonstrate that the representations learned by Point-BERT transfer well to new tasks and domains, where our models largely advance the state-of-the-art of few-shot point cloud classification task. The code and pre-trained models are available at https://github.com/lulutang0608/Point-BERT
Improving Semantic Analysis on Point Clouds via Auxiliary Supervision of Local Geometric Priors
Jan 14, 2020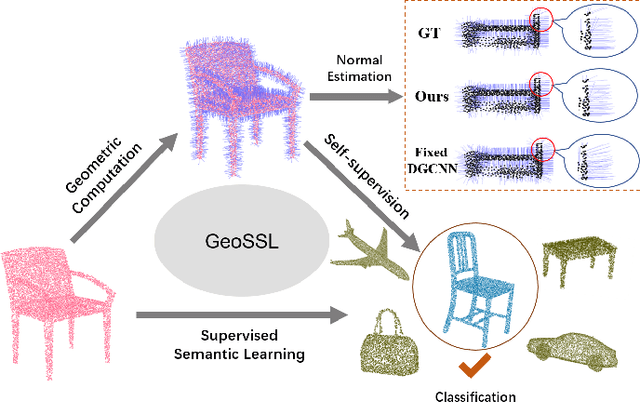
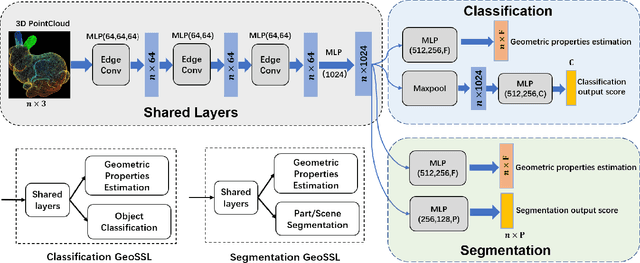
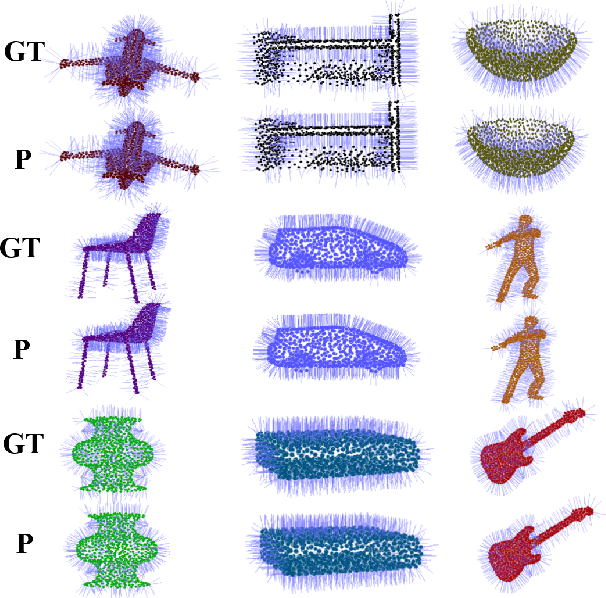
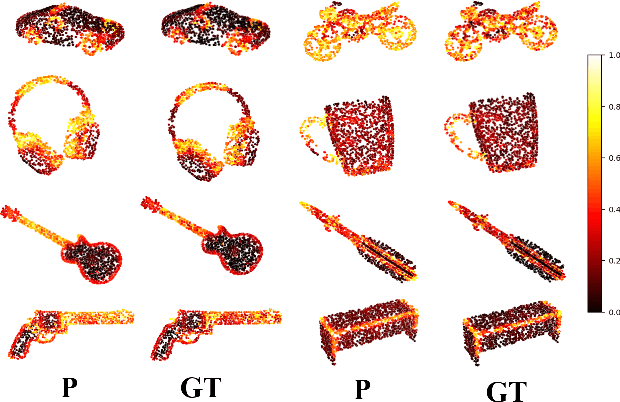
Existing deep learning algorithms for point cloud analysis mainly concern discovering semantic patterns from global configuration of local geometries in a supervised learning manner. However, very few explore geometric properties revealing local surface manifolds embedded in 3D Euclidean space to discriminate semantic classes or object parts as additional supervision signals. This paper is the first attempt to propose a unique multi-task geometric learning network to improve semantic analysis by auxiliary geometric learning with local shape properties, which can be either generated via physical computation from point clouds themselves as self-supervision signals or provided as privileged information. Owing to explicitly encoding local shape manifolds in favor of semantic analysis, the proposed geometric self-supervised and privileged learning algorithms can achieve superior performance to their backbone baselines and other state-of-the-art methods, which are verified in the experiments on the popular benchmarks.