 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVAR-3D: View-aware Auto-Regressive Model for Text-to-3D Generation via a 3D Tokenizer
Feb 14, 2026Recent advances in auto-regressive transformers have achieved remarkable success in generative modeling. However, text-to-3D generation remains challenging, primarily due to bottlenecks in learning discrete 3D representations. Specifically, existing approaches often suffer from information loss during encoding, causing representational distortion before the quantization process. This effect is further amplified by vector quantization, ultimately degrading the geometric coherence of text-conditioned 3D shapes. Moreover, the conventional two-stage training paradigm induces an objective mismatch between reconstruction and text-conditioned auto-regressive generation. To address these issues, we propose View-aware Auto-Regressive 3D (VAR-3D), which intergrates a view-aware 3D Vector Quantized-Variational AutoEncoder (VQ-VAE) to convert the complex geometric structure of 3D models into discrete tokens. Additionally, we introduce a rendering-supervised training strategy that couples discrete token prediction with visual reconstruction, encouraging the generative process to better preserve visual fidelity and structural consistency relative to the input text. Experiments demonstrate that VAR-3D significantly outperforms existing methods in both generation quality and text-3D alignment.
RMPL: Relation-aware Multi-task Progressive Learning with Stage-wise Training for Multimedia Event Extraction
Feb 14, 2026Multimedia Event Extraction (MEE) aims to identify events and their arguments from documents that contain both text and images. It requires grounding event semantics across different modalities. Progress in MEE is limited by the lack of annotated training data. M2E2 is the only established benchmark, but it provides annotations only for evaluation. This makes direct supervised training impractical. Existing methods mainly rely on cross-modal alignment or inference-time prompting with Vision--Language Models (VLMs). These approaches do not explicitly learn structured event representations and often produce weak argument grounding in multimodal settings. To address these limitations, we propose RMPL, a Relation-aware Multi-task Progressive Learning framework for MEE under low-resource conditions. RMPL incorporates heterogeneous supervision from unimodal event extraction and multimedia relation extraction with stage-wise training. The model is first trained with a unified schema to learn shared event-centric representations across modalities. It is then fine-tuned for event mention identification and argument role extraction using mixed textual and visual data. Experiments on the M2E2 benchmark with multiple VLMs show consistent improvements across different modality settings.
Towards Generalized and Training-Free Text-Guided Semantic Manipulation
Apr 24, 2025



Text-guided semantic manipulation refers to semantically editing an image generated from a source prompt to match a target prompt, enabling the desired semantic changes (e.g., addition, removal, and style transfer) while preserving irrelevant contents. With the powerful generative capabilities of the diffusion model, the task has shown the potential to generate high-fidelity visual content. Nevertheless, existing methods either typically require time-consuming fine-tuning (inefficient), fail to accomplish multiple semantic manipulations (poorly extensible), and/or lack support for different modality tasks (limited generalizability). Upon further investigation, we find that the geometric properties of noises in the diffusion model are strongly correlated with the semantic changes. Motivated by this, we propose a novel $\textit{GTF}$ for text-guided semantic manipulation, which has the following attractive capabilities: 1) $\textbf{Generalized}$: our $\textit{GTF}$ supports multiple semantic manipulations (e.g., addition, removal, and style transfer) and can be seamlessly integrated into all diffusion-based methods (i.e., Plug-and-play) across different modalities (i.e., modality-agnostic); and 2) $\textbf{Training-free}$: $\textit{GTF}$ produces high-fidelity results via simply controlling the geometric relationship between noises without tuning or optimization. Our extensive experiments demonstrate the efficacy of our approach, highlighting its potential to advance the state-of-the-art in semantics manipulation.
RePerformer: Immersive Human-centric Volumetric Videos from Playback to Photoreal Reperformance
Mar 15, 2025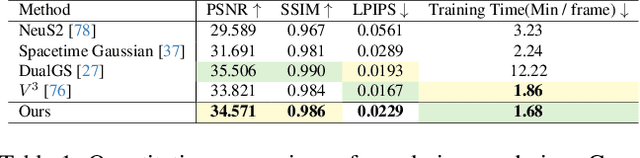
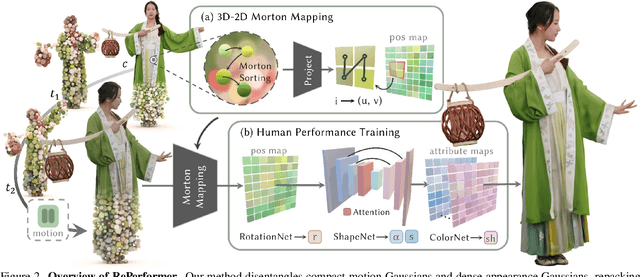
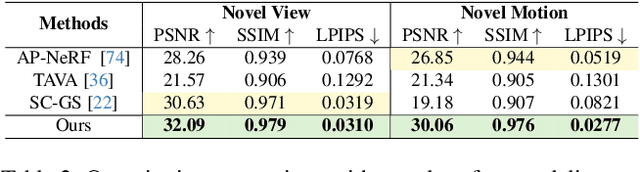
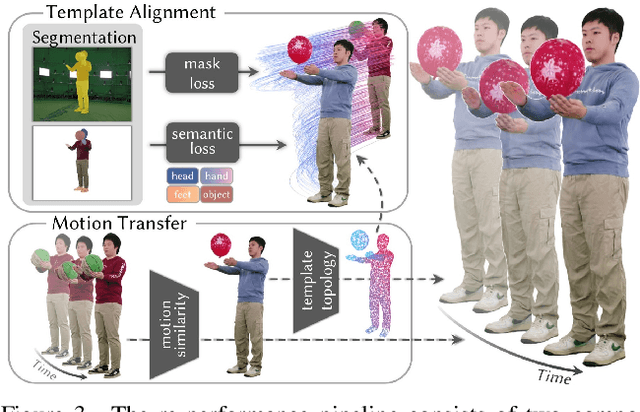
Human-centric volumetric videos offer immersive free-viewpoint experiences, yet existing methods focus either on replaying general dynamic scenes or animating human avatars, limiting their ability to re-perform general dynamic scenes. In this paper, we present RePerformer, a novel Gaussian-based representation that unifies playback and re-performance for high-fidelity human-centric volumetric videos. Specifically, we hierarchically disentangle the dynamic scenes into motion Gaussians and appearance Gaussians which are associated in the canonical space. We further employ a Morton-based parameterization to efficiently encode the appearance Gaussians into 2D position and attribute maps. For enhanced generalization, we adopt 2D CNNs to map position maps to attribute maps, which can be assembled into appearance Gaussians for high-fidelity rendering of the dynamic scenes. For re-performance, we develop a semantic-aware alignment module and apply deformation transfer on motion Gaussians, enabling photo-real rendering under novel motions. Extensive experiments validate the robustness and effectiveness of RePerformer, setting a new benchmark for playback-then-reperformance paradigm in human-centric volumetric videos.
BEAM: Bridging Physically-based Rendering and Gaussian Modeling for Relightable Volumetric Video
Feb 12, 2025Volumetric video enables immersive experiences by capturing dynamic 3D scenes, enabling diverse applications for virtual reality, education, and telepresence. However, traditional methods struggle with fixed lighting conditions, while neural approaches face trade-offs in efficiency, quality, or adaptability for relightable scenarios. To address these limitations, we present BEAM, a novel pipeline that bridges 4D Gaussian representations with physically-based rendering (PBR) to produce high-quality, relightable volumetric videos from multi-view RGB footage. BEAM recovers detailed geometry and PBR properties via a series of available Gaussian-based techniques. It first combines Gaussian-based performance tracking with geometry-aware rasterization in a coarse-to-fine optimization framework to recover spatially and temporally consistent geometries. We further enhance Gaussian attributes by incorporating PBR properties step by step. We generate roughness via a multi-view-conditioned diffusion model, and then derive AO and base color using a 2D-to-3D strategy, incorporating a tailored Gaussian-based ray tracer for efficient visibility computation. Once recovered, these dynamic, relightable assets integrate seamlessly into traditional CG pipelines, supporting real-time rendering with deferred shading and offline rendering with ray tracing. By offering realistic, lifelike visualizations under diverse lighting conditions, BEAM opens new possibilities for interactive entertainment, storytelling, and creative visualization.
Exploiting the Index Gradients for Optimization-Based Jailbreaking on Large Language Models
Dec 11, 2024



Despite the advancements in training Large Language Models (LLMs) with alignment techniques to enhance the safety of generated content, these models remain susceptible to jailbreak, an adversarial attack method that exposes security vulnerabilities in LLMs. Notably, the Greedy Coordinate Gradient (GCG) method has demonstrated the ability to automatically generate adversarial suffixes that jailbreak state-of-the-art LLMs. However, the optimization process involved in GCG is highly time-consuming, rendering the jailbreaking pipeline inefficient. In this paper, we investigate the process of GCG and identify an issue of Indirect Effect, the key bottleneck of the GCG optimization. To this end, we propose the Model Attack Gradient Index GCG (MAGIC), that addresses the Indirect Effect by exploiting the gradient information of the suffix tokens, thereby accelerating the procedure by having less computation and fewer iterations. Our experiments on AdvBench show that MAGIC achieves up to a 1.5x speedup, while maintaining Attack Success Rates (ASR) on par or even higher than other baselines. Our MAGIC achieved an ASR of 74% on the Llama-2 and an ASR of 54% when conducting transfer attacks on GPT-3.5. Code is available at https://github.com/jiah-li/magic.
Robust Dual Gaussian Splatting for Immersive Human-centric Volumetric Videos
Sep 12, 2024Volumetric video represents a transformative advancement in visual media, enabling users to freely navigate immersive virtual experiences and narrowing the gap between digital and real worlds. However, the need for extensive manual intervention to stabilize mesh sequences and the generation of excessively large assets in existing workflows impedes broader adoption. In this paper, we present a novel Gaussian-based approach, dubbed \textit{DualGS}, for real-time and high-fidelity playback of complex human performance with excellent compression ratios. Our key idea in DualGS is to separately represent motion and appearance using the corresponding skin and joint Gaussians. Such an explicit disentanglement can significantly reduce motion redundancy and enhance temporal coherence. We begin by initializing the DualGS and anchoring skin Gaussians to joint Gaussians at the first frame. Subsequently, we employ a coarse-to-fine training strategy for frame-by-frame human performance modeling. It includes a coarse alignment phase for overall motion prediction as well as a fine-grained optimization for robust tracking and high-fidelity rendering. To integrate volumetric video seamlessly into VR environments, we efficiently compress motion using entropy encoding and appearance using codec compression coupled with a persistent codebook. Our approach achieves a compression ratio of up to 120 times, only requiring approximately 350KB of storage per frame. We demonstrate the efficacy of our representation through photo-realistic, free-view experiences on VR headsets, enabling users to immersively watch musicians in performance and feel the rhythm of the notes at the performers' fingertips.
Evaluating Knowledge-based Cross-lingual Inconsistency in Large Language Models
Jul 01, 2024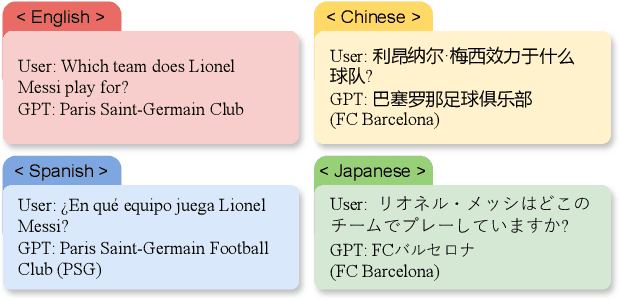
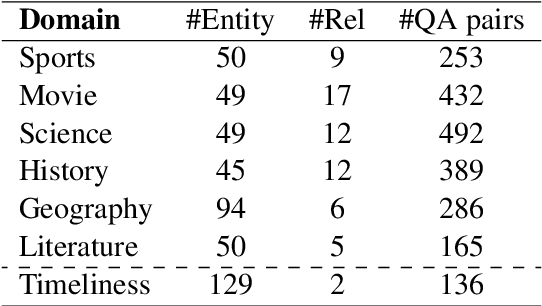

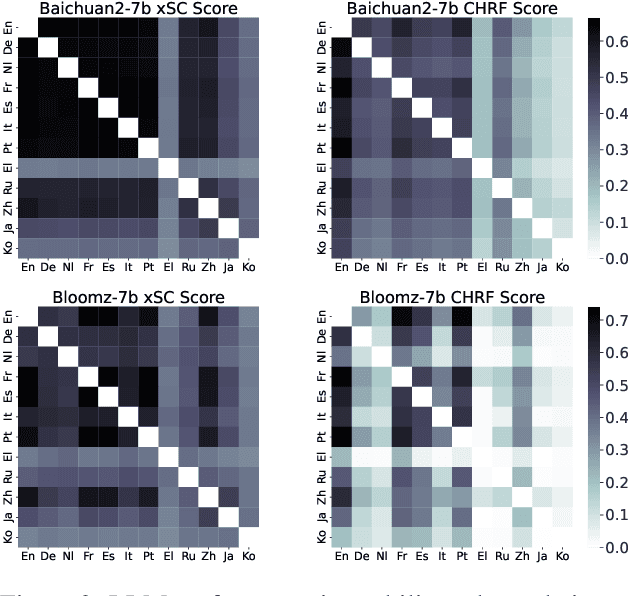
This paper investigates the cross-lingual inconsistencies observed in Large Language Models (LLMs), such as ChatGPT, Llama, and Baichuan, which have shown exceptional performance in various Natural Language Processing (NLP) tasks. Despite their successes, these models often exhibit significant inconsistencies when processing the same concepts across different languages. This study focuses on three primary questions: the existence of cross-lingual inconsistencies in LLMs, the specific aspects in which these inconsistencies manifest, and the correlation between cross-lingual consistency and multilingual capabilities of LLMs.To address these questions, we propose an innovative evaluation method for Cross-lingual Semantic Consistency (xSC) using the LaBSE model. We further introduce metrics for Cross-lingual Accuracy Consistency (xAC) and Cross-lingual Timeliness Consistency (xTC) to comprehensively assess the models' performance regarding semantic, accuracy, and timeliness inconsistencies. By harmonizing these metrics, we provide a holistic measurement of LLMs' cross-lingual consistency. Our findings aim to enhance the understanding and improvement of multilingual capabilities and interpretability in LLMs, contributing to the development of more robust and reliable multilingual language models.
UniVision: A Unified Framework for Vision-Centric 3D Perception
Jan 13, 2024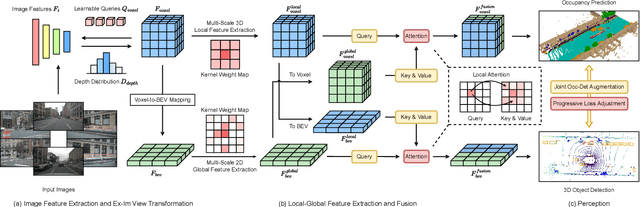
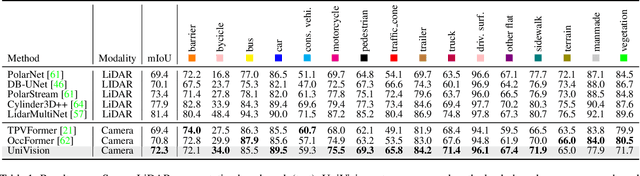
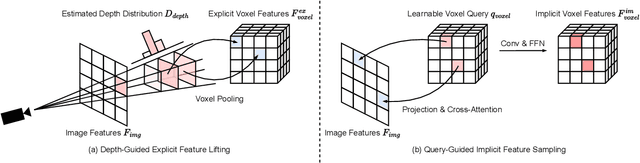
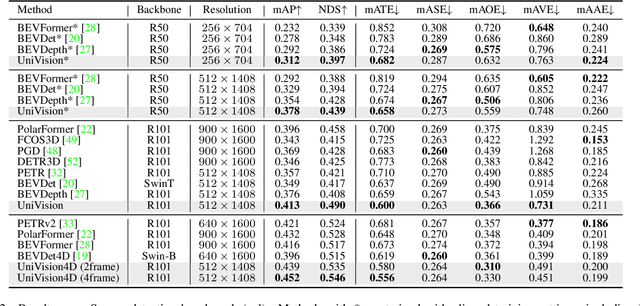
The past few years have witnessed the rapid development of vision-centric 3D perception in autonomous driving. Although the 3D perception models share many structural and conceptual similarities, there still exist gaps in their feature representations, data formats, and objectives, posing challenges for unified and efficient 3D perception framework design. In this paper, we present UniVision, a simple and efficient framework that unifies two major tasks in vision-centric 3D perception, \ie, occupancy prediction and object detection. Specifically, we propose an explicit-implicit view transform module for complementary 2D-3D feature transformation. We propose a local-global feature extraction and fusion module for efficient and adaptive voxel and BEV feature extraction, enhancement, and interaction. Further, we propose a joint occupancy-detection data augmentation strategy and a progressive loss weight adjustment strategy which enables the efficiency and stability of the multi-task framework training. We conduct extensive experiments for different perception tasks on four public benchmarks, including nuScenes LiDAR segmentation, nuScenes detection, OpenOccupancy, and Occ3D. UniVision achieves state-of-the-art results with +1.5 mIoU, +1.8 NDS, +1.5 mIoU, and +1.8 mIoU gains on each benchmark, respectively. We believe that the UniVision framework can serve as a high-performance baseline for the unified vision-centric 3D perception task. The code will be available at \url{https://github.com/Cc-Hy/UniVision}.
HiFi4G: High-Fidelity Human Performance Rendering via Compact Gaussian Splatting
Dec 07, 2023



We have recently seen tremendous progress in photo-real human modeling and rendering. Yet, efficiently rendering realistic human performance and integrating it into the rasterization pipeline remains challenging. In this paper, we present HiFi4G, an explicit and compact Gaussian-based approach for high-fidelity human performance rendering from dense footage. Our core intuition is to marry the 3D Gaussian representation with non-rigid tracking, achieving a compact and compression-friendly representation. We first propose a dual-graph mechanism to obtain motion priors, with a coarse deformation graph for effective initialization and a fine-grained Gaussian graph to enforce subsequent constraints. Then, we utilize a 4D Gaussian optimization scheme with adaptive spatial-temporal regularizers to effectively balance the non-rigid prior and Gaussian updating. We also present a companion compression scheme with residual compensation for immersive experiences on various platforms. It achieves a substantial compression rate of approximately 25 times, with less than 2MB of storage per frame. Extensive experiments demonstrate the effectiveness of our approach, which significantly outperforms existing approaches in terms of optimization speed, rendering quality, and storage overhead.