 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoreference-aware Double-channel Attention Network for Multi-party Dialogue Reading Comprehension
May 22, 2023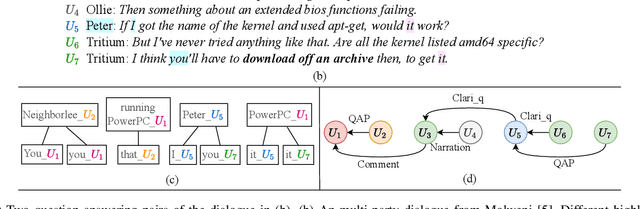
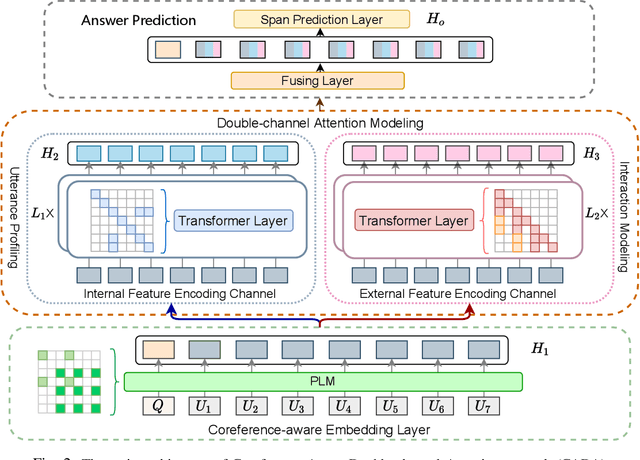

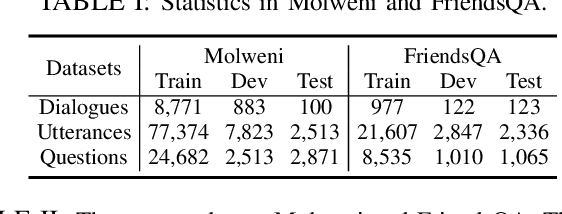
We tackle Multi-party Dialogue Reading Comprehension (abbr., MDRC). MDRC stands for an extractive reading comprehension task grounded on a batch of dialogues among multiple interlocutors. It is challenging due to the requirement of understanding cross-utterance contexts and relationships in a multi-turn multi-party conversation. Previous studies have made great efforts on the utterance profiling of a single interlocutor and graph-based interaction modeling. The corresponding solutions contribute to the answer-oriented reasoning on a series of well-organized and thread-aware conversational contexts. However, the current MDRC models still suffer from two bottlenecks. On the one hand, a pronoun like "it" most probably produces multi-skip reasoning throughout the utterances of different interlocutors. On the other hand, an MDRC encoder is potentially puzzled by fuzzy features, i.e., the mixture of inner linguistic features in utterances and external interactive features among utterances. To overcome the bottlenecks, we propose a coreference-aware attention modeling method to strengthen the reasoning ability. In addition, we construct a two-channel encoding network. It separately encodes utterance profiles and interactive relationships, so as to relieve the confusion among heterogeneous features. We experiment on the benchmark corpora Molweni and FriendsQA. Experimental results demonstrate that our approach yields substantial improvements on both corpora, compared to the fine-tuned BERT and ELECTRA baselines. The maximum performance gain is about 2.5\% F1-score. Besides, our MDRC models outperform the state-of-the-art in most cases.
LSTM-RPA: A Simple but Effective Long Sequence Prediction Algorithm for Music Popularity Prediction
Oct 27, 2021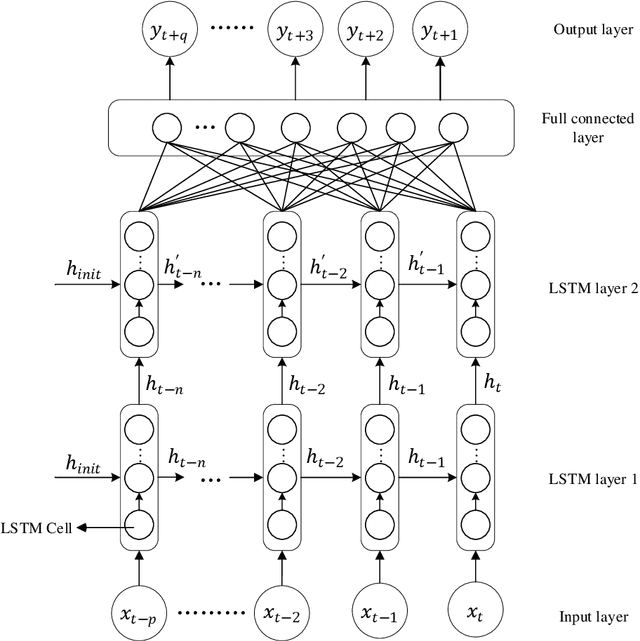
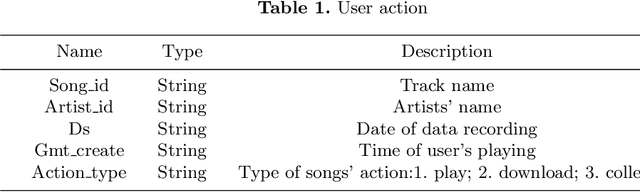
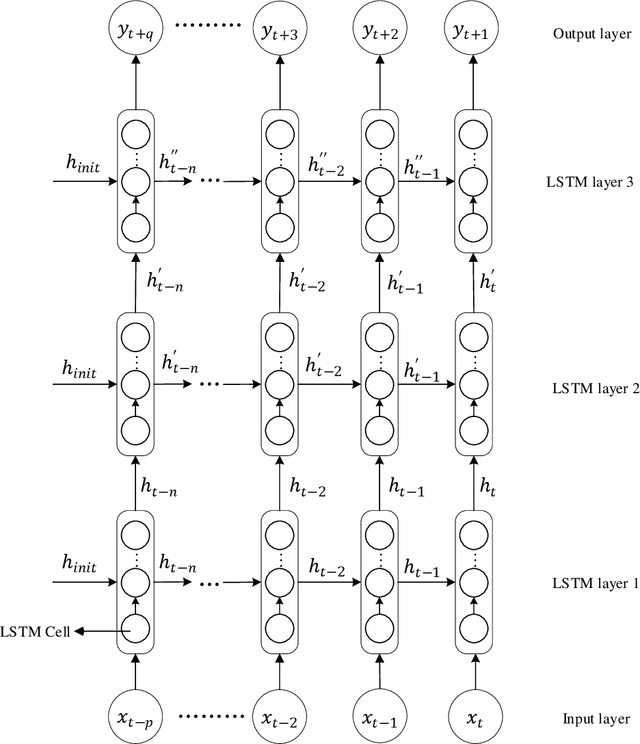

The big data about music history contains information about time and users' behavior. Researchers could predict the trend of popular songs accurately by analyzing this data. The traditional trend prediction models can better predict the short trend than the long trend. In this paper, we proposed the improved LSTM Rolling Prediction Algorithm (LSTM-RPA), which combines LSTM historical input with current prediction results as model input for next time prediction. Meanwhile, this algorithm converts the long trend prediction task into multiple short trend prediction tasks. The evaluation results show that the LSTM-RPA model increased F score by 13.03%, 16.74%, 11.91%, 18.52%, compared with LSTM, BiLSTM, GRU and RNN. And our method outperforms tradi-tional sequence models, which are ARIMA and SMA, by 10.67% and 3.43% improvement in F score.Code: https://github.com/maliaosaide/lstm-rpa