 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Multilingual Social Media Insights: Aspect-based Comment Analysis
May 29, 2025The inherent nature of social media posts, characterized by the freedom of language use with a disjointed array of diverse opinions and topics, poses significant challenges to downstream NLP tasks such as comment clustering, comment summarization, and social media opinion analysis. To address this, we propose a granular level of identifying and generating aspect terms from individual comments to guide model attention. Specifically, we leverage multilingual large language models with supervised fine-tuning for comment aspect term generation (CAT-G), further aligning the model's predictions with human expectations through DPO. We demonstrate the effectiveness of our method in enhancing the comprehension of social media discourse on two NLP tasks. Moreover, this paper contributes the first multilingual CAT-G test set on English, Chinese, Malay, and Bahasa Indonesian. As LLM capabilities vary among languages, this test set allows for a comparative analysis of performance across languages with varying levels of LLM proficiency.
AdaCoT: Rethinking Cross-Lingual Factual Reasoning through Adaptive Chain-of-Thought
Jan 27, 2025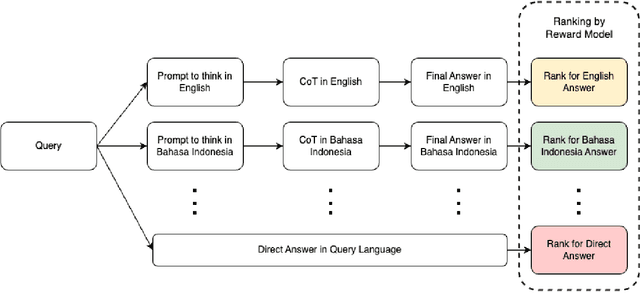
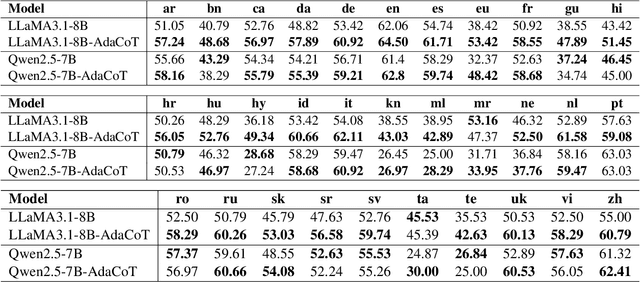

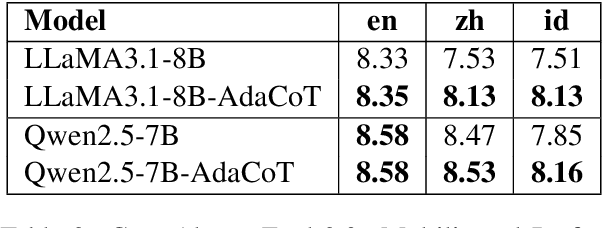
Large language models (LLMs) have shown impressive multilingual capabilities through pretraining on diverse corpora. While these models show strong reasoning abilities, their performance varies significantly across languages due to uneven training data distribution. Existing approaches using machine translation, and extensive multilingual pretraining and cross-lingual tuning face scalability challenges and often fail to capture nuanced reasoning processes across languages. In this paper, we introduce AdaCoT (Adaptive Chain-of-Thought), a framework that enhances multilingual reasoning by dynamically routing thought processes through intermediary "thinking languages" before generating target-language responses. AdaCoT leverages a language-agnostic core and incorporates an adaptive, reward-based mechanism for selecting optimal reasoning pathways without requiring additional pretraining. Our comprehensive evaluation across multiple benchmarks demonstrates substantial improvements in both factual reasoning quality and cross-lingual consistency, with particularly strong performance gains in low-resource language settings. The results suggest that adaptive reasoning paths can effectively bridge the performance gap between high and low-resource languages while maintaining cultural and linguistic nuances.
Evidence-based Interpretable Open-domain Fact-checking with Large Language Models
Dec 10, 2023Universal fact-checking systems for real-world claims face significant challenges in gathering valid and sufficient real-time evidence and making reasoned decisions. In this work, we introduce the Open-domain Explainable Fact-checking (OE-Fact) system for claim-checking in real-world scenarios. The OE-Fact system can leverage the powerful understanding and reasoning capabilities of large language models (LLMs) to validate claims and generate causal explanations for fact-checking decisions. To adapt the traditional three-module fact-checking framework to the open domain setting, we first retrieve claim-related information as relevant evidence from open websites. After that, we retain the evidence relevant to the claim through LLM and similarity calculation for subsequent verification. We evaluate the performance of our adapted three-module OE-Fact system on the Fact Extraction and Verification (FEVER) dataset. Experimental results show that our OE-Fact system outperforms general fact-checking baseline systems in both closed- and open-domain scenarios, ensuring stable and accurate verdicts while providing concise and convincing real-time explanations for fact-checking decisions.
UFO: Unified Fact Obtaining for Commonsense Question Answering
May 25, 2023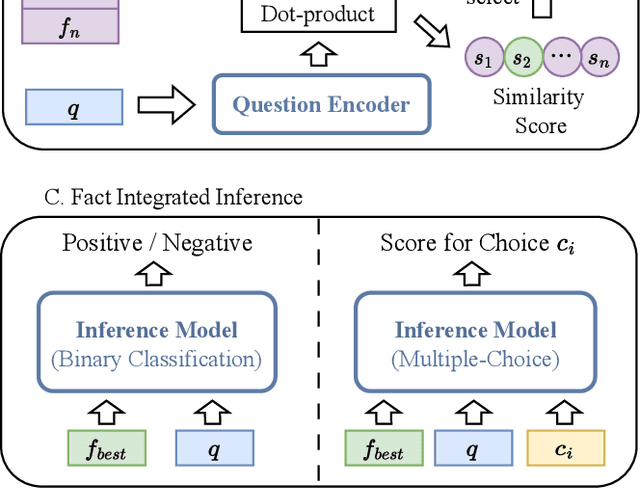


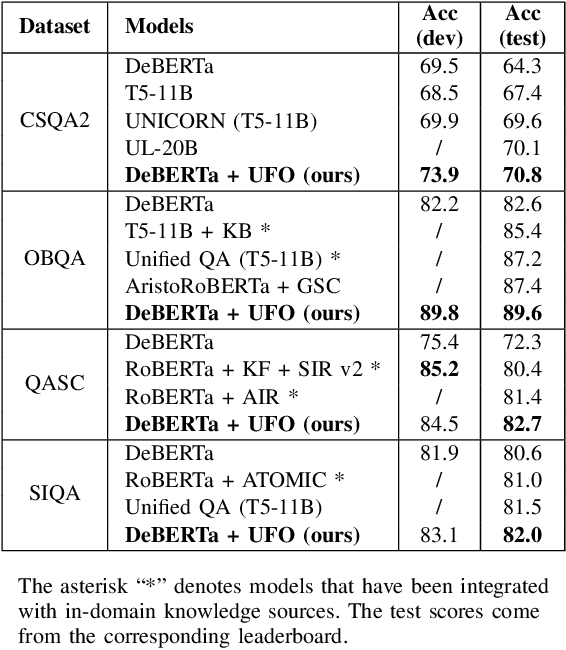
Leveraging external knowledge to enhance the reasoning ability is crucial for commonsense question answering. However, the existing knowledge bases heavily rely on manual annotation which unavoidably causes deficiency in coverage of world-wide commonsense knowledge. Accordingly, the knowledge bases fail to be flexible enough to support the reasoning over diverse questions. Recently, large-scale language models (LLMs) have dramatically improved the intelligence in capturing and leveraging knowledge, which opens up a new way to address the issue of eliciting knowledge from language models. We propose a Unified Facts Obtaining (UFO) approach. UFO turns LLMs into knowledge sources and produces relevant facts (knowledge statements) for the given question. We first develop a unified prompt consisting of demonstrations that cover different aspects of commonsense and different question styles. On this basis, we instruct the LLMs to generate question-related supporting facts for various commonsense questions via prompting. After facts generation, we apply a dense retrieval-based fact selection strategy to choose the best-matched fact. This kind of facts will be fed into the answer inference model along with the question. Notably, due to the design of unified prompts, UFO can support reasoning in various commonsense aspects (including general commonsense, scientific commonsense, and social commonsense). Extensive experiments on CommonsenseQA 2.0, OpenBookQA, QASC, and Social IQA benchmarks show that UFO significantly improves the performance of the inference model and outperforms manually constructed knowledge sources.
Coreference-aware Double-channel Attention Network for Multi-party Dialogue Reading Comprehension
May 22, 2023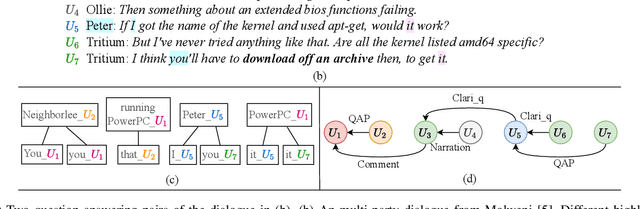
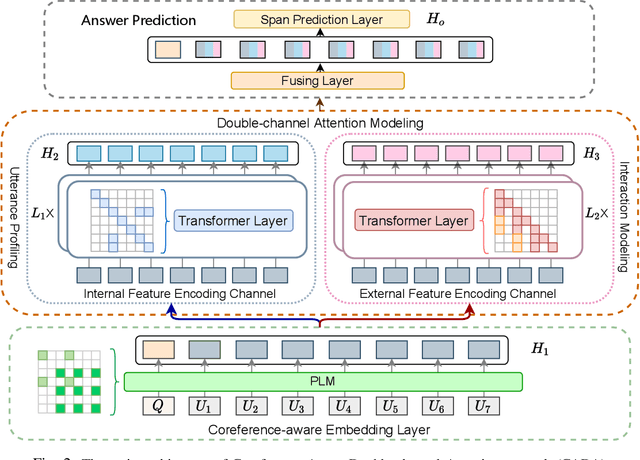

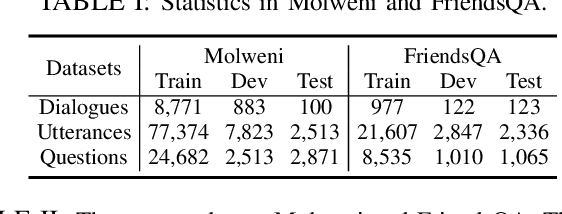
We tackle Multi-party Dialogue Reading Comprehension (abbr., MDRC). MDRC stands for an extractive reading comprehension task grounded on a batch of dialogues among multiple interlocutors. It is challenging due to the requirement of understanding cross-utterance contexts and relationships in a multi-turn multi-party conversation. Previous studies have made great efforts on the utterance profiling of a single interlocutor and graph-based interaction modeling. The corresponding solutions contribute to the answer-oriented reasoning on a series of well-organized and thread-aware conversational contexts. However, the current MDRC models still suffer from two bottlenecks. On the one hand, a pronoun like "it" most probably produces multi-skip reasoning throughout the utterances of different interlocutors. On the other hand, an MDRC encoder is potentially puzzled by fuzzy features, i.e., the mixture of inner linguistic features in utterances and external interactive features among utterances. To overcome the bottlenecks, we propose a coreference-aware attention modeling method to strengthen the reasoning ability. In addition, we construct a two-channel encoding network. It separately encodes utterance profiles and interactive relationships, so as to relieve the confusion among heterogeneous features. We experiment on the benchmark corpora Molweni and FriendsQA. Experimental results demonstrate that our approach yields substantial improvements on both corpora, compared to the fine-tuned BERT and ELECTRA baselines. The maximum performance gain is about 2.5\% F1-score. Besides, our MDRC models outperform the state-of-the-art in most cases.
KEPR: Knowledge Enhancement and Plausibility Ranking for Generative Commonsense Question Answering
May 15, 2023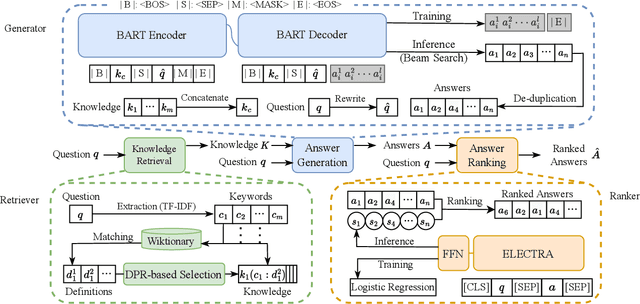
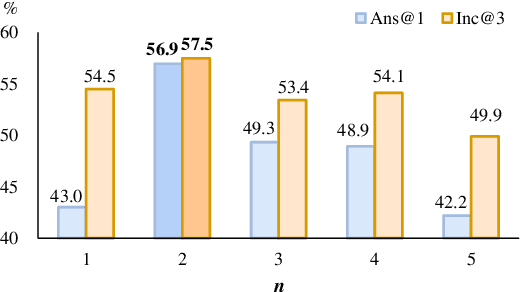
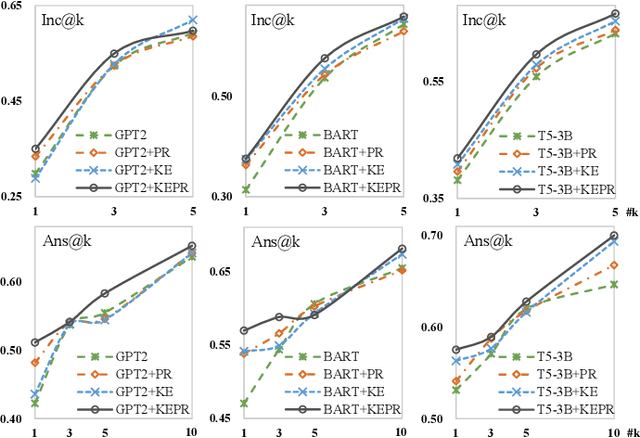
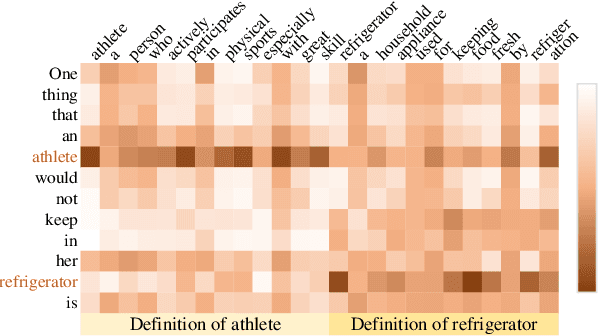
Generative commonsense question answering (GenCQA) is a task of automatically generating a list of answers given a question. The answer list is required to cover all reasonable answers. This presents the considerable challenges of producing diverse answers and ranking them properly. Incorporating a variety of closely-related background knowledge into the encoding of questions enables the generation of different answers. Meanwhile, learning to distinguish positive answers from negative ones potentially enhances the probabilistic estimation of plausibility, and accordingly, the plausibility-based ranking. Therefore, we propose a Knowledge Enhancement and Plausibility Ranking (KEPR) approach grounded on the Generate-Then-Rank pipeline architecture. Specifically, we expand questions in terms of Wiktionary commonsense knowledge of keywords, and reformulate them with normalized patterns. Dense passage retrieval is utilized for capturing relevant knowledge, and different PLM-based (BART, GPT2 and T5) networks are used for generating answers. On the other hand, we develop an ELECTRA-based answer ranking model, where logistic regression is conducted during training, with the aim of approximating different levels of plausibility in a polar classification scenario. Extensive experiments on the benchmark ProtoQA show that KEPR obtains substantial improvements, compared to the strong baselines. Within the experimental models, the T5-based GenCQA with KEPR obtains the best performance, which is up to 60.91% at the primary canonical metric Inc@3. It outperforms the existing GenCQA models on the current leaderboard of ProtoQA.
Modeling What-to-ask and How-to-ask for Answer-unaware Conversational Question Generation
May 04, 2023Conversational Question Generation (CQG) is a critical task for machines to assist humans in fulfilling their information needs through conversations. The task is generally cast into two different settings: answer-aware and answer-unaware. While the former facilitates the models by exposing the expected answer, the latter is more realistic and receiving growing attentions recently. What-to-ask and how-to-ask are the two main challenges in the answer-unaware setting. To address the first challenge, existing methods mainly select sequential sentences in context as the rationales. We argue that the conversation generated using such naive heuristics may not be natural enough as in reality, the interlocutors often talk about the relevant contents that are not necessarily sequential in context. Additionally, previous methods decide the type of question to be generated (boolean/span-based) implicitly. Modeling the question type explicitly is crucial as the answer, which hints the models to generate a boolean or span-based question, is unavailable. To this end, we present SG-CQG, a two-stage CQG framework. For the what-to-ask stage, a sentence is selected as the rationale from a semantic graph that we construct, and extract the answer span from it. For the how-to-ask stage, a classifier determines the target answer type of the question via two explicit control signals before generating and filtering. In addition, we propose Conv-Distinct, a novel evaluation metric for CQG, to evaluate the diversity of the generated conversation from a context. Compared with the existing answer-unaware CQG models, the proposed SG-CQG achieves state-of-the-art performance.
CoHS-CQG: Context and History Selection for Conversational Question Generation
Sep 14, 2022
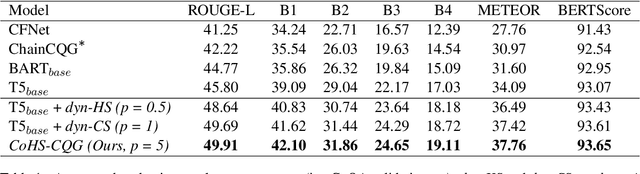
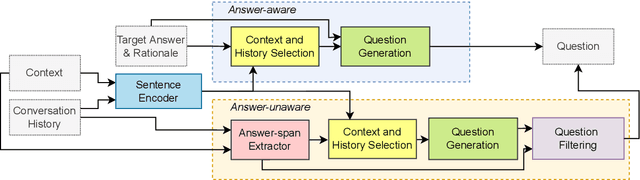
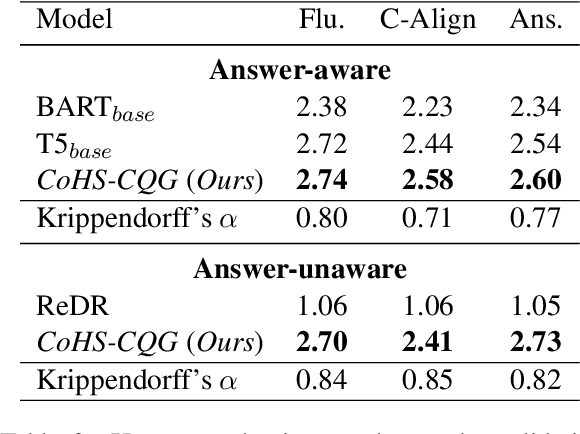
Conversational question generation (CQG) serves as a vital task for machines to assist humans, such as interactive reading comprehension, through conversations. Compared to traditional single-turn question generation (SQG), CQG is more challenging in the sense that the generated question is required not only to be meaningful, but also to align with the occurred conversation history. While previous studies mainly focus on how to model the flow and alignment of the conversation, there has been no thorough study to date on which parts of the context and history are necessary for the model. We argue that shortening the context and history is crucial as it can help the model to optimise more on the conversational alignment property. To this end, we propose CoHS-CQG, a two-stage CQG framework, which adopts a CoHS module to shorten the context and history of the input. In particular, CoHS selects contiguous sentences and history turns according to their relevance scores by a top-p strategy. Our model achieves state-of-the-art performances on CoQA in both the answer-aware and answer-unaware settings.
Improving Lexical Embeddings for Robust Question Answering
Feb 28, 2022
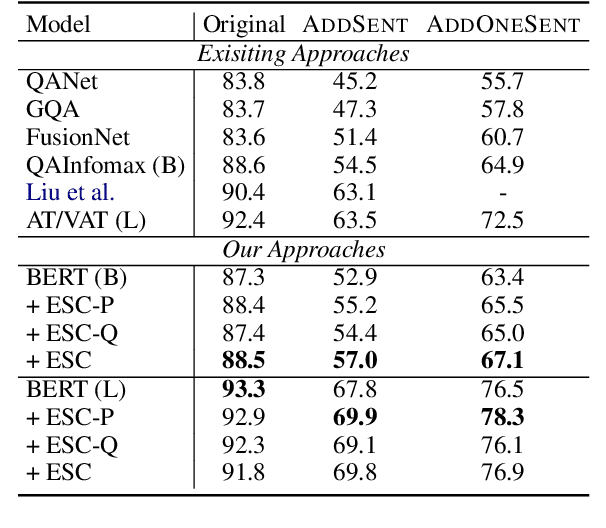
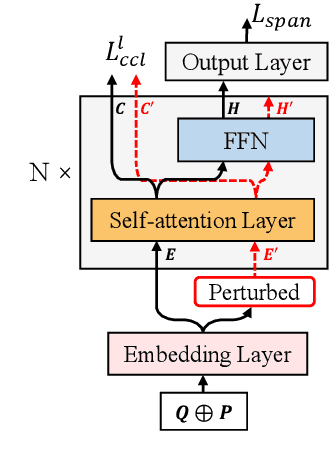
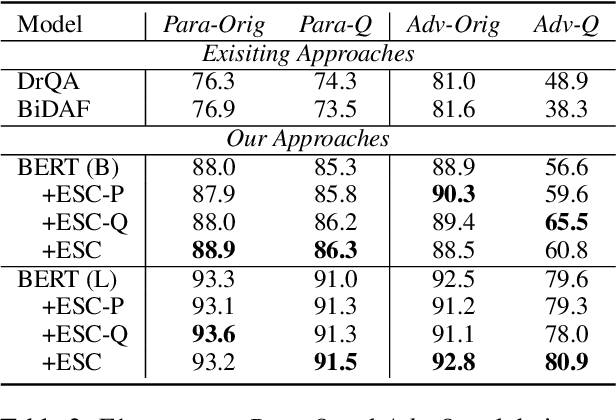
Recent techniques in Question Answering (QA) have gained remarkable performance improvement with some QA models even surpassed human performance. However, the ability of these models in truly understanding the language still remains dubious and the models are revealing limitations when facing adversarial examples. To strengthen the robustness of QA models and their generalization ability, we propose a representation Enhancement via Semantic and Context constraints (ESC) approach to improve the robustness of lexical embeddings. Specifically, we insert perturbations with semantic constraints and train enhanced contextual representations via a context-constraint loss to better distinguish the context clues for the correct answer. Experimental results show that our approach gains significant robustness improvement on four adversarial test sets.