 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKEPR: Knowledge Enhancement and Plausibility Ranking for Generative Commonsense Question Answering
Paper and Code
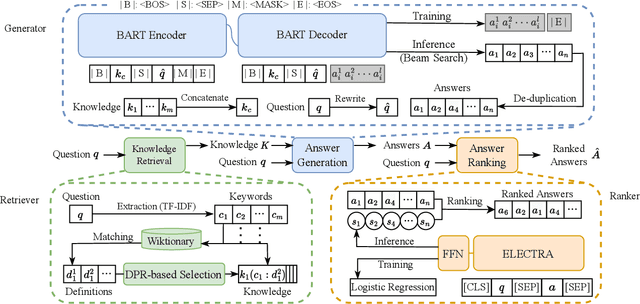
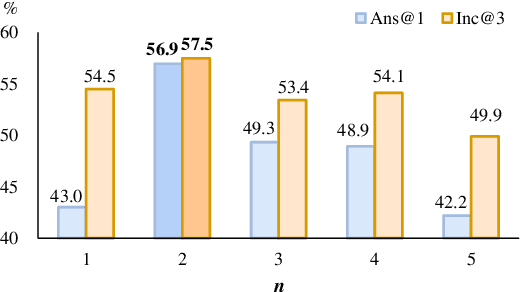
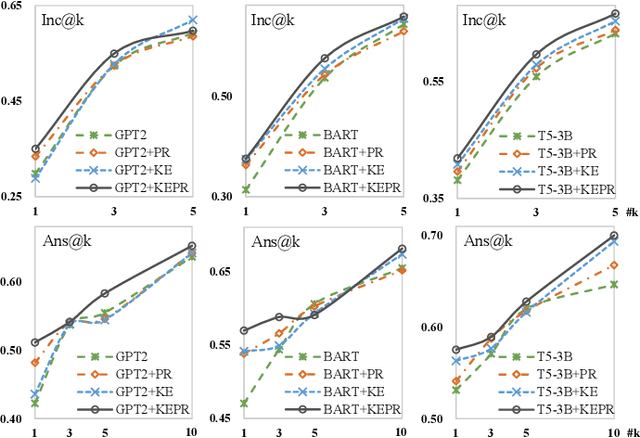
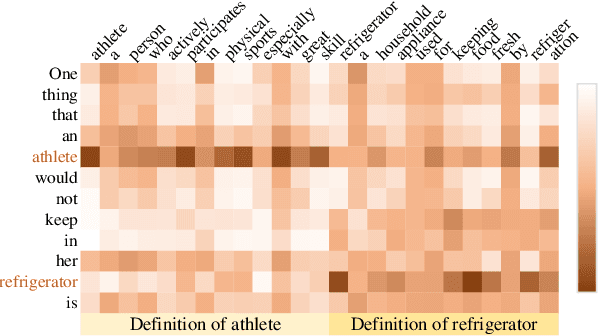
Generative commonsense question answering (GenCQA) is a task of automatically generating a list of answers given a question. The answer list is required to cover all reasonable answers. This presents the considerable challenges of producing diverse answers and ranking them properly. Incorporating a variety of closely-related background knowledge into the encoding of questions enables the generation of different answers. Meanwhile, learning to distinguish positive answers from negative ones potentially enhances the probabilistic estimation of plausibility, and accordingly, the plausibility-based ranking. Therefore, we propose a Knowledge Enhancement and Plausibility Ranking (KEPR) approach grounded on the Generate-Then-Rank pipeline architecture. Specifically, we expand questions in terms of Wiktionary commonsense knowledge of keywords, and reformulate them with normalized patterns. Dense passage retrieval is utilized for capturing relevant knowledge, and different PLM-based (BART, GPT2 and T5) networks are used for generating answers. On the other hand, we develop an ELECTRA-based answer ranking model, where logistic regression is conducted during training, with the aim of approximating different levels of plausibility in a polar classification scenario. Extensive experiments on the benchmark ProtoQA show that KEPR obtains substantial improvements, compared to the strong baselines. Within the experimental models, the T5-based GenCQA with KEPR obtains the best performance, which is up to 60.91% at the primary canonical metric Inc@3. It outperforms the existing GenCQA models on the current leaderboard of ProtoQA.