 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUFO: Unified Fact Obtaining for Commonsense Question Answering
May 25, 2023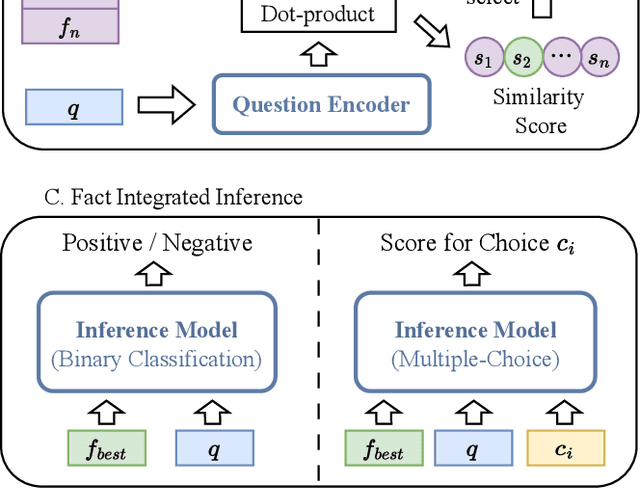


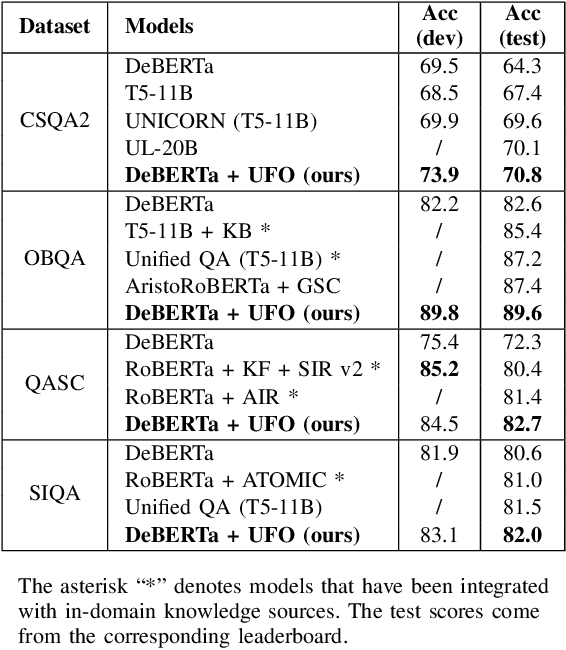
Leveraging external knowledge to enhance the reasoning ability is crucial for commonsense question answering. However, the existing knowledge bases heavily rely on manual annotation which unavoidably causes deficiency in coverage of world-wide commonsense knowledge. Accordingly, the knowledge bases fail to be flexible enough to support the reasoning over diverse questions. Recently, large-scale language models (LLMs) have dramatically improved the intelligence in capturing and leveraging knowledge, which opens up a new way to address the issue of eliciting knowledge from language models. We propose a Unified Facts Obtaining (UFO) approach. UFO turns LLMs into knowledge sources and produces relevant facts (knowledge statements) for the given question. We first develop a unified prompt consisting of demonstrations that cover different aspects of commonsense and different question styles. On this basis, we instruct the LLMs to generate question-related supporting facts for various commonsense questions via prompting. After facts generation, we apply a dense retrieval-based fact selection strategy to choose the best-matched fact. This kind of facts will be fed into the answer inference model along with the question. Notably, due to the design of unified prompts, UFO can support reasoning in various commonsense aspects (including general commonsense, scientific commonsense, and social commonsense). Extensive experiments on CommonsenseQA 2.0, OpenBookQA, QASC, and Social IQA benchmarks show that UFO significantly improves the performance of the inference model and outperforms manually constructed knowledge sources.
Coreference-aware Double-channel Attention Network for Multi-party Dialogue Reading Comprehension
May 22, 2023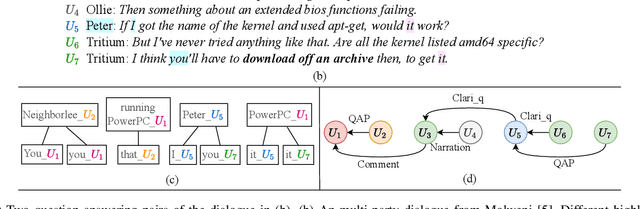
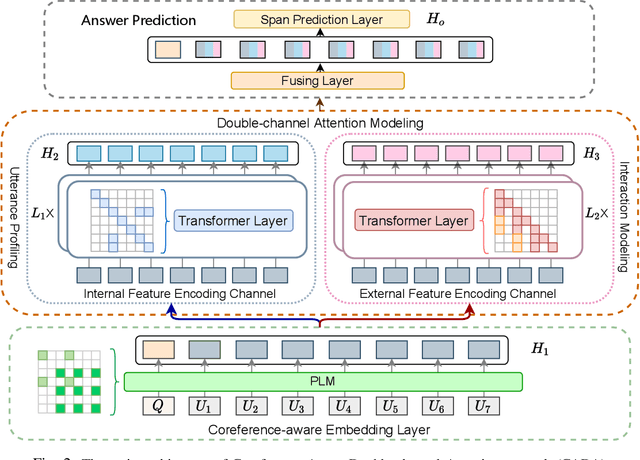

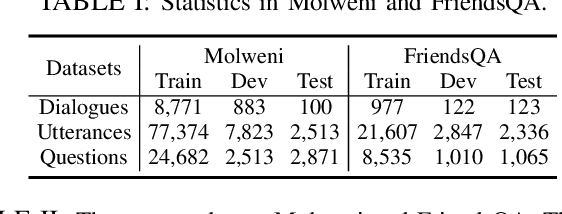
We tackle Multi-party Dialogue Reading Comprehension (abbr., MDRC). MDRC stands for an extractive reading comprehension task grounded on a batch of dialogues among multiple interlocutors. It is challenging due to the requirement of understanding cross-utterance contexts and relationships in a multi-turn multi-party conversation. Previous studies have made great efforts on the utterance profiling of a single interlocutor and graph-based interaction modeling. The corresponding solutions contribute to the answer-oriented reasoning on a series of well-organized and thread-aware conversational contexts. However, the current MDRC models still suffer from two bottlenecks. On the one hand, a pronoun like "it" most probably produces multi-skip reasoning throughout the utterances of different interlocutors. On the other hand, an MDRC encoder is potentially puzzled by fuzzy features, i.e., the mixture of inner linguistic features in utterances and external interactive features among utterances. To overcome the bottlenecks, we propose a coreference-aware attention modeling method to strengthen the reasoning ability. In addition, we construct a two-channel encoding network. It separately encodes utterance profiles and interactive relationships, so as to relieve the confusion among heterogeneous features. We experiment on the benchmark corpora Molweni and FriendsQA. Experimental results demonstrate that our approach yields substantial improvements on both corpora, compared to the fine-tuned BERT and ELECTRA baselines. The maximum performance gain is about 2.5\% F1-score. Besides, our MDRC models outperform the state-of-the-art in most cases.
KEPR: Knowledge Enhancement and Plausibility Ranking for Generative Commonsense Question Answering
May 15, 2023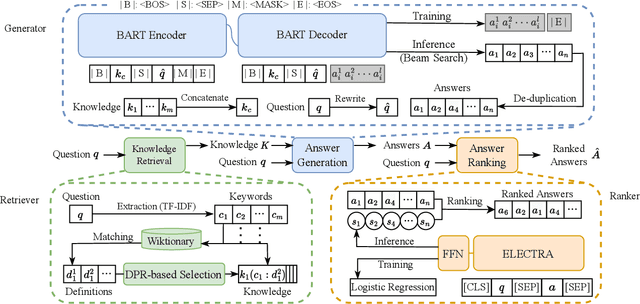
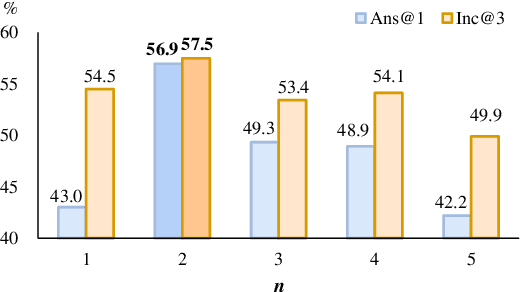
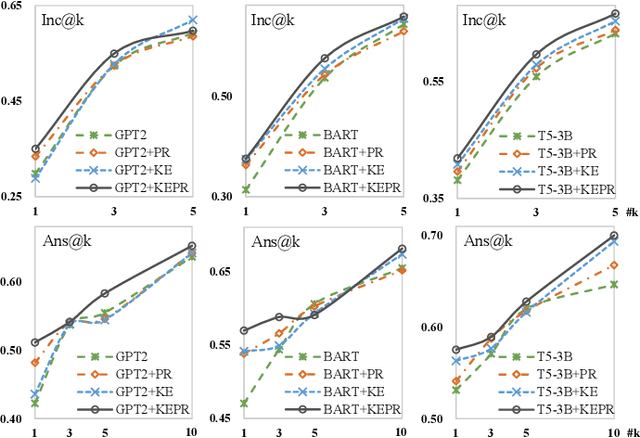
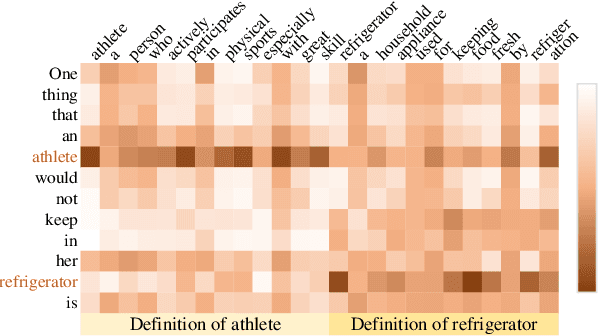
Generative commonsense question answering (GenCQA) is a task of automatically generating a list of answers given a question. The answer list is required to cover all reasonable answers. This presents the considerable challenges of producing diverse answers and ranking them properly. Incorporating a variety of closely-related background knowledge into the encoding of questions enables the generation of different answers. Meanwhile, learning to distinguish positive answers from negative ones potentially enhances the probabilistic estimation of plausibility, and accordingly, the plausibility-based ranking. Therefore, we propose a Knowledge Enhancement and Plausibility Ranking (KEPR) approach grounded on the Generate-Then-Rank pipeline architecture. Specifically, we expand questions in terms of Wiktionary commonsense knowledge of keywords, and reformulate them with normalized patterns. Dense passage retrieval is utilized for capturing relevant knowledge, and different PLM-based (BART, GPT2 and T5) networks are used for generating answers. On the other hand, we develop an ELECTRA-based answer ranking model, where logistic regression is conducted during training, with the aim of approximating different levels of plausibility in a polar classification scenario. Extensive experiments on the benchmark ProtoQA show that KEPR obtains substantial improvements, compared to the strong baselines. Within the experimental models, the T5-based GenCQA with KEPR obtains the best performance, which is up to 60.91% at the primary canonical metric Inc@3. It outperforms the existing GenCQA models on the current leaderboard of ProtoQA.