 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFollow-Your-Motion: Video Motion Transfer via Efficient Spatial-Temporal Decoupled Finetuning
Jun 05, 2025Recently, breakthroughs in the video diffusion transformer have shown remarkable capabilities in diverse motion generations. As for the motion-transfer task, current methods mainly use two-stage Low-Rank Adaptations (LoRAs) finetuning to obtain better performance. However, existing adaptation-based motion transfer still suffers from motion inconsistency and tuning inefficiency when applied to large video diffusion transformers. Naive two-stage LoRA tuning struggles to maintain motion consistency between generated and input videos due to the inherent spatial-temporal coupling in the 3D attention operator. Additionally, they require time-consuming fine-tuning processes in both stages. To tackle these issues, we propose Follow-Your-Motion, an efficient two-stage video motion transfer framework that finetunes a powerful video diffusion transformer to synthesize complex motion.Specifically, we propose a spatial-temporal decoupled LoRA to decouple the attention architecture for spatial appearance and temporal motion processing. During the second training stage, we design the sparse motion sampling and adaptive RoPE to accelerate the tuning speed. To address the lack of a benchmark for this field, we introduce MotionBench, a comprehensive benchmark comprising diverse motion, including creative camera motion, single object motion, multiple object motion, and complex human motion. We show extensive evaluations on MotionBench to verify the superiority of Follow-Your-Motion.
Towards Dataset Copyright Evasion Attack against Personalized Text-to-Image Diffusion Models
May 05, 2025Text-to-image (T2I) diffusion models have rapidly advanced, enabling high-quality image generation conditioned on textual prompts. However, the growing trend of fine-tuning pre-trained models for personalization raises serious concerns about unauthorized dataset usage. To combat this, dataset ownership verification (DOV) has emerged as a solution, embedding watermarks into the fine-tuning datasets using backdoor techniques. These watermarks remain inactive under benign samples but produce owner-specified outputs when triggered. Despite the promise of DOV for T2I diffusion models, its robustness against copyright evasion attacks (CEA) remains unexplored. In this paper, we explore how attackers can bypass these mechanisms through CEA, allowing models to circumvent watermarks even when trained on watermarked datasets. We propose the first copyright evasion attack (i.e., CEAT2I) specifically designed to undermine DOV in T2I diffusion models. Concretely, our CEAT2I comprises three stages: watermarked sample detection, trigger identification, and efficient watermark mitigation. A key insight driving our approach is that T2I models exhibit faster convergence on watermarked samples during the fine-tuning, evident through intermediate feature deviation. Leveraging this, CEAT2I can reliably detect the watermarked samples. Then, we iteratively ablate tokens from the prompts of detected watermarked samples and monitor shifts in intermediate features to pinpoint the exact trigger tokens. Finally, we adopt a closed-form concept erasure method to remove the injected watermark. Extensive experiments show that our CEAT2I effectively evades DOV mechanisms while preserving model performance.
Temporal Entailment Pretraining for Clinical Language Models over EHR Data
Apr 25, 2025Clinical language models have achieved strong performance on downstream tasks by pretraining on domain specific corpora such as discharge summaries and medical notes. However, most approaches treat the electronic health record as a static document, neglecting the temporally-evolving and causally entwined nature of patient trajectories. In this paper, we introduce a novel temporal entailment pretraining objective for language models in the clinical domain. Our method formulates EHR segments as temporally ordered sentence pairs and trains the model to determine whether a later state is entailed by, contradictory to, or neutral with respect to an earlier state. Through this temporally structured pretraining task, models learn to perform latent clinical reasoning over time, improving their ability to generalize across forecasting and diagnosis tasks. We pretrain on a large corpus derived from MIMIC IV and demonstrate state of the art results on temporal clinical QA, early warning prediction, and disease progression modeling.
Mitigating Timbre Leakage with Universal Semantic Mapping Residual Block for Voice Conversion
Apr 11, 2025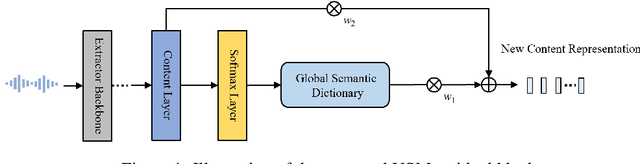
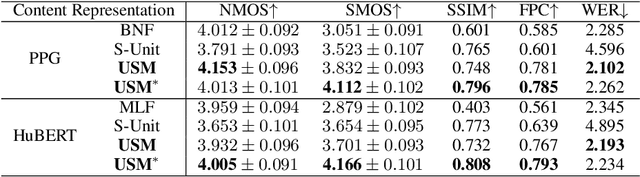
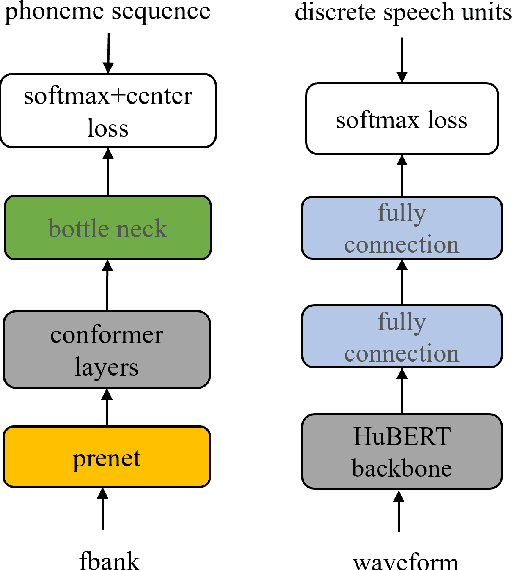
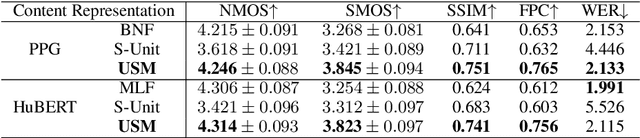
Voice conversion (VC) transforms source speech into a target voice by preserving the content. However, timbre information from the source speaker is inherently embedded in the content representations, causing significant timbre leakage and reducing similarity to the target speaker. To address this, we introduce a residual block to a content extractor. The residual block consists of two weighted branches: 1) universal semantic dictionary based Content Feature Re-expression (CFR) module, supplying timbre-free content representation. 2) skip connection to the original content layer, providing complementary fine-grained information. In the CFR module, each dictionary entry in the universal semantic dictionary represents a phoneme class, computed statistically using speech from multiple speakers, creating a stable, speaker-independent semantic set. We introduce a CFR method to obtain timbre-free content representations by expressing each content frame as a weighted linear combination of dictionary entries using corresponding phoneme posteriors as weights. Extensive experiments across various VC frameworks demonstrate that our approach effectively mitigates timbre leakage and significantly improves similarity to the target speaker.
System-2 Mathematical Reasoning via Enriched Instruction Tuning
Dec 24, 2024



Solving complex mathematical problems via system-2 reasoning is a natural human skill, yet it remains a significant challenge for current large language models (LLMs). We identify the scarcity of deliberate multi-step reasoning data as a primary limiting factor. To this end, we introduce Enriched Instruction Tuning (EIT), a method that enriches existing human-annotated mathematical datasets by synergizing human and AI feedback to create fine-grained reasoning trajectories. These datasets are then used to fine-tune open-source LLMs, enhancing their mathematical reasoning abilities without reliance on any symbolic verification program. Concretely, EIT is composed of two critical steps: Enriching with Reasoning Plan (ERP) and Enriching with Reasoning Step (ERS). The former generates a high-level plan that breaks down complex instructions into a sequence of simpler objectives, while ERS fills in reasoning contexts often overlooked by human annotators, creating a smoother reasoning trajectory for LLM fine-tuning. Unlike existing CoT prompting methods that generate reasoning chains only depending on LLM's internal knowledge, our method leverages human-annotated initial answers as ``meta-knowledge'' to help LLMs generate more detailed and precise reasoning processes, leading to a more trustworthy LLM expert for complex mathematical problems. In experiments, EIT achieves an accuracy of 84.1% on GSM8K and 32.5% on MATH, surpassing state-of-the-art fine-tuning and prompting methods, and even matching the performance of tool-augmented methods.
Embedding Self-Correction as an Inherent Ability in Large Language Models for Enhanced Mathematical Reasoning
Oct 14, 2024



Accurate mathematical reasoning with Large Language Models (LLMs) is crucial in revolutionizing domains that heavily rely on such reasoning. However, LLMs often encounter difficulties in certain aspects of mathematical reasoning, leading to flawed reasoning and erroneous results. To mitigate these issues, we introduce a novel mechanism, the Chain of Self-Correction (CoSC), specifically designed to embed self-correction as an inherent ability in LLMs, enabling them to validate and rectify their own results. The CoSC mechanism operates through a sequence of self-correction stages. In each stage, the LLMs generate a program to address a given problem, execute this program using program-based tools to obtain an output, subsequently verify this output. Based on the verification, the LLMs either proceed to the next correction stage or finalize the answer. This iterative self-correction process allows the LLMs to refine their reasoning steps and improve the accuracy of their mathematical reasoning. To enable the CoSC mechanism at a low cost, we employ a two-phase finetuning approach. In the first phase, the LLMs are trained with a relatively small volume of seeding data generated from GPT-4, establishing an initial CoSC capability. In the second phase, the CoSC capability is further enhanced by training with a larger volume of self-generated data using the trained model in the first phase, without relying on the paid GPT-4. Our comprehensive experiments demonstrate that CoSC significantly improves performance on traditional mathematical datasets among existing open-source LLMs. Notably, our CoSC-Code-34B model achieved a 53.5% score on MATH, the most challenging mathematical reasoning dataset in the public domain, surpassing the performance of well-established models such as ChatGPT, GPT-4, and even multi-modal LLMs like GPT-4V, Gemini-1.0 Pro, and Gemini-1.0 Ultra.
Nearest is Not Dearest: Towards Practical Defense against Quantization-conditioned Backdoor Attacks
May 21, 2024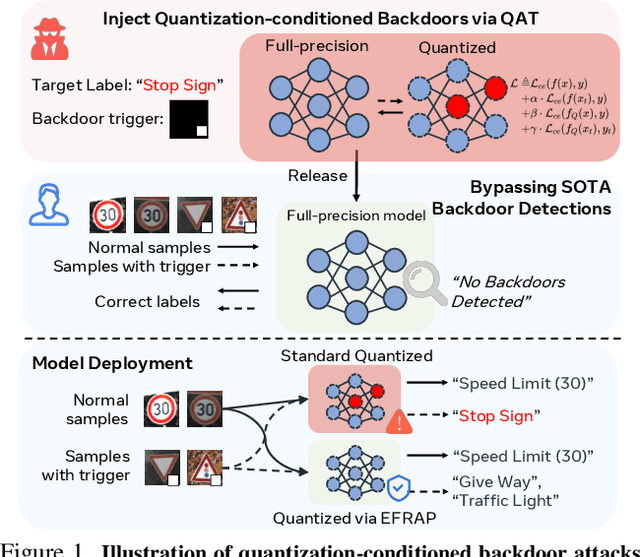
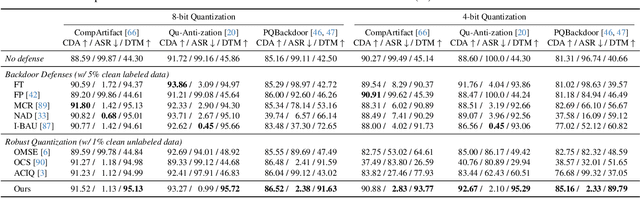
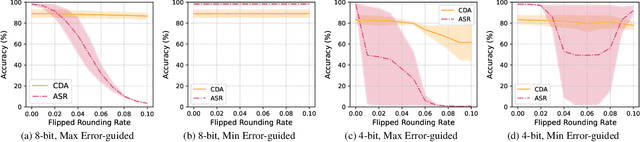
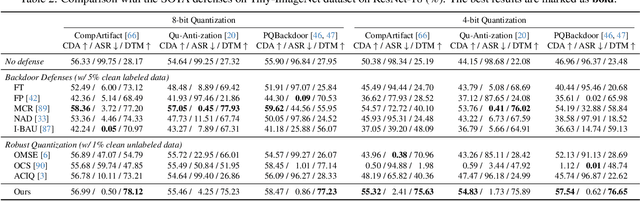
Model quantization is widely used to compress and accelerate deep neural networks. However, recent studies have revealed the feasibility of weaponizing model quantization via implanting quantization-conditioned backdoors (QCBs). These special backdoors stay dormant on released full-precision models but will come into effect after standard quantization. Due to the peculiarity of QCBs, existing defenses have minor effects on reducing their threats or are even infeasible. In this paper, we conduct the first in-depth analysis of QCBs. We reveal that the activation of existing QCBs primarily stems from the nearest rounding operation and is closely related to the norms of neuron-wise truncation errors (i.e., the difference between the continuous full-precision weights and its quantized version). Motivated by these insights, we propose Error-guided Flipped Rounding with Activation Preservation (EFRAP), an effective and practical defense against QCBs. Specifically, EFRAP learns a non-nearest rounding strategy with neuron-wise error norm and layer-wise activation preservation guidance, flipping the rounding strategies of neurons crucial for backdoor effects but with minimal impact on clean accuracy. Extensive evaluations on benchmark datasets demonstrate that our EFRAP can defeat state-of-the-art QCB attacks under various settings. Code is available at https://github.com/AntigoneRandy/QuantBackdoor_EFRAP.
Energy-Latency Manipulation of Multi-modal Large Language Models via Verbose Samples
Apr 25, 2024Despite the exceptional performance of multi-modal large language models (MLLMs), their deployment requires substantial computational resources. Once malicious users induce high energy consumption and latency time (energy-latency cost), it will exhaust computational resources and harm availability of service. In this paper, we investigate this vulnerability for MLLMs, particularly image-based and video-based ones, and aim to induce high energy-latency cost during inference by crafting an imperceptible perturbation. We find that high energy-latency cost can be manipulated by maximizing the length of generated sequences, which motivates us to propose verbose samples, including verbose images and videos. Concretely, two modality non-specific losses are proposed, including a loss to delay end-of-sequence (EOS) token and an uncertainty loss to increase the uncertainty over each generated token. In addition, improving diversity is important to encourage longer responses by increasing the complexity, which inspires the following modality specific loss. For verbose images, a token diversity loss is proposed to promote diverse hidden states. For verbose videos, a frame feature diversity loss is proposed to increase the feature diversity among frames. To balance these losses, we propose a temporal weight adjustment algorithm. Experiments demonstrate that our verbose samples can largely extend the length of generated sequences.
Follow-Your-Click: Open-domain Regional Image Animation via Short Prompts
Mar 13, 2024



Despite recent advances in image-to-video generation, better controllability and local animation are less explored. Most existing image-to-video methods are not locally aware and tend to move the entire scene. However, human artists may need to control the movement of different objects or regions. Additionally, current I2V methods require users not only to describe the target motion but also to provide redundant detailed descriptions of frame contents. These two issues hinder the practical utilization of current I2V tools. In this paper, we propose a practical framework, named Follow-Your-Click, to achieve image animation with a simple user click (for specifying what to move) and a short motion prompt (for specifying how to move). Technically, we propose the first-frame masking strategy, which significantly improves the video generation quality, and a motion-augmented module equipped with a short motion prompt dataset to improve the short prompt following abilities of our model. To further control the motion speed, we propose flow-based motion magnitude control to control the speed of target movement more precisely. Our framework has simpler yet precise user control and better generation performance than previous methods. Extensive experiments compared with 7 baselines, including both commercial tools and research methods on 8 metrics, suggest the superiority of our approach. Project Page: https://follow-your-click.github.io/
Inducing High Energy-Latency of Large Vision-Language Models with Verbose Images
Jan 20, 2024Large vision-language models (VLMs) such as GPT-4 have achieved exceptional performance across various multi-modal tasks. However, the deployment of VLMs necessitates substantial energy consumption and computational resources. Once attackers maliciously induce high energy consumption and latency time (energy-latency cost) during inference of VLMs, it will exhaust computational resources. In this paper, we explore this attack surface about availability of VLMs and aim to induce high energy-latency cost during inference of VLMs. We find that high energy-latency cost during inference of VLMs can be manipulated by maximizing the length of generated sequences. To this end, we propose verbose images, with the goal of crafting an imperceptible perturbation to induce VLMs to generate long sentences during inference. Concretely, we design three loss objectives. First, a loss is proposed to delay the occurrence of end-of-sequence (EOS) token, where EOS token is a signal for VLMs to stop generating further tokens. Moreover, an uncertainty loss and a token diversity loss are proposed to increase the uncertainty over each generated token and the diversity among all tokens of the whole generated sequence, respectively, which can break output dependency at token-level and sequence-level. Furthermore, a temporal weight adjustment algorithm is proposed, which can effectively balance these losses. Extensive experiments demonstrate that our verbose images can increase the length of generated sequences by 7.87 times and 8.56 times compared to original images on MS-COCO and ImageNet datasets, which presents potential challenges for various applications. Our code is available at https://github.com/KuofengGao/Verbose_Images.