 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSystem-2 Mathematical Reasoning via Enriched Instruction Tuning
Dec 24, 2024



Solving complex mathematical problems via system-2 reasoning is a natural human skill, yet it remains a significant challenge for current large language models (LLMs). We identify the scarcity of deliberate multi-step reasoning data as a primary limiting factor. To this end, we introduce Enriched Instruction Tuning (EIT), a method that enriches existing human-annotated mathematical datasets by synergizing human and AI feedback to create fine-grained reasoning trajectories. These datasets are then used to fine-tune open-source LLMs, enhancing their mathematical reasoning abilities without reliance on any symbolic verification program. Concretely, EIT is composed of two critical steps: Enriching with Reasoning Plan (ERP) and Enriching with Reasoning Step (ERS). The former generates a high-level plan that breaks down complex instructions into a sequence of simpler objectives, while ERS fills in reasoning contexts often overlooked by human annotators, creating a smoother reasoning trajectory for LLM fine-tuning. Unlike existing CoT prompting methods that generate reasoning chains only depending on LLM's internal knowledge, our method leverages human-annotated initial answers as ``meta-knowledge'' to help LLMs generate more detailed and precise reasoning processes, leading to a more trustworthy LLM expert for complex mathematical problems. In experiments, EIT achieves an accuracy of 84.1% on GSM8K and 32.5% on MATH, surpassing state-of-the-art fine-tuning and prompting methods, and even matching the performance of tool-augmented methods.
Embedding Self-Correction as an Inherent Ability in Large Language Models for Enhanced Mathematical Reasoning
Oct 14, 2024



Accurate mathematical reasoning with Large Language Models (LLMs) is crucial in revolutionizing domains that heavily rely on such reasoning. However, LLMs often encounter difficulties in certain aspects of mathematical reasoning, leading to flawed reasoning and erroneous results. To mitigate these issues, we introduce a novel mechanism, the Chain of Self-Correction (CoSC), specifically designed to embed self-correction as an inherent ability in LLMs, enabling them to validate and rectify their own results. The CoSC mechanism operates through a sequence of self-correction stages. In each stage, the LLMs generate a program to address a given problem, execute this program using program-based tools to obtain an output, subsequently verify this output. Based on the verification, the LLMs either proceed to the next correction stage or finalize the answer. This iterative self-correction process allows the LLMs to refine their reasoning steps and improve the accuracy of their mathematical reasoning. To enable the CoSC mechanism at a low cost, we employ a two-phase finetuning approach. In the first phase, the LLMs are trained with a relatively small volume of seeding data generated from GPT-4, establishing an initial CoSC capability. In the second phase, the CoSC capability is further enhanced by training with a larger volume of self-generated data using the trained model in the first phase, without relying on the paid GPT-4. Our comprehensive experiments demonstrate that CoSC significantly improves performance on traditional mathematical datasets among existing open-source LLMs. Notably, our CoSC-Code-34B model achieved a 53.5% score on MATH, the most challenging mathematical reasoning dataset in the public domain, surpassing the performance of well-established models such as ChatGPT, GPT-4, and even multi-modal LLMs like GPT-4V, Gemini-1.0 Pro, and Gemini-1.0 Ultra.
TransMatting: Tri-token Equipped Transformer Model for Image Matting
Mar 11, 2023



Image matting aims to predict alpha values of elaborate uncertainty areas of natural images, like hairs, smoke, and spider web. However, existing methods perform poorly when faced with highly transparent foreground objects due to the large area of uncertainty to predict and the small receptive field of convolutional networks. To address this issue, we propose a Transformer-based network (TransMatting) to model transparent objects with long-range features and collect a high-resolution matting dataset of transparent objects (Transparent-460) for performance evaluation. Specifically, to utilize semantic information in the trimap flexibly and effectively, we also redesign the trimap as three learnable tokens, named tri-token. Both Transformer and convolution matting models could benefit from our proposed tri-token design. By replacing the traditional trimap concatenation strategy with our tri-token, existing matting methods could achieve about 10% improvement in SAD and 20% in MSE. Equipped with the new tri-token design, our proposed TransMatting outperforms current state-of-the-art methods on several popular matting benchmarks and our newly collected Transparent-460.
TransMatting: Enhancing Transparent Objects Matting with Transformers
Aug 05, 2022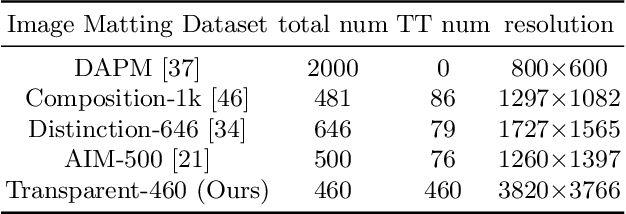
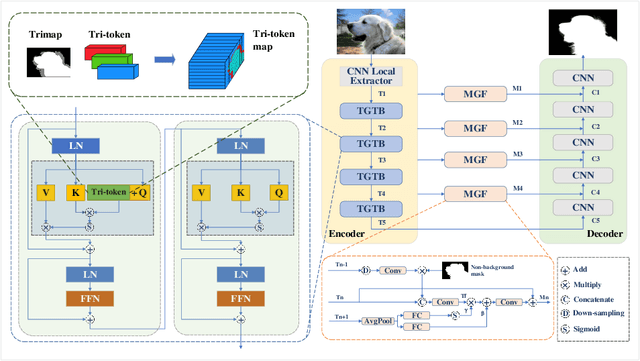
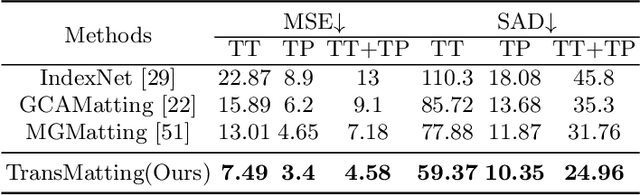

Image matting refers to predicting the alpha values of unknown foreground areas from natural images. Prior methods have focused on propagating alpha values from known to unknown regions. However, not all natural images have a specifically known foreground. Images of transparent objects, like glass, smoke, web, etc., have less or no known foreground. In this paper, we propose a Transformer-based network, TransMatting, to model transparent objects with a big receptive field. Specifically, we redesign the trimap as three learnable tri-tokens for introducing advanced semantic features into the self-attention mechanism. A small convolutional network is proposed to utilize the global feature and non-background mask to guide the multi-scale feature propagation from encoder to decoder for maintaining the contexture of transparent objects. In addition, we create a high-resolution matting dataset of transparent objects with small known foreground areas. Experiments on several matting benchmarks demonstrate the superiority of our proposed method over the current state-of-the-art methods.
NTIRE 2021 Multi-modal Aerial View Object Classification Challenge
Jul 02, 2021
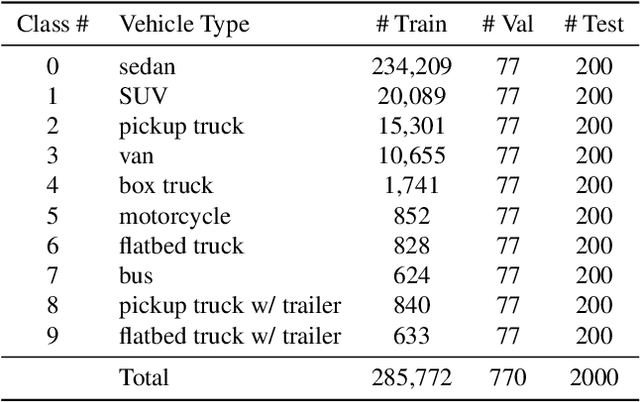
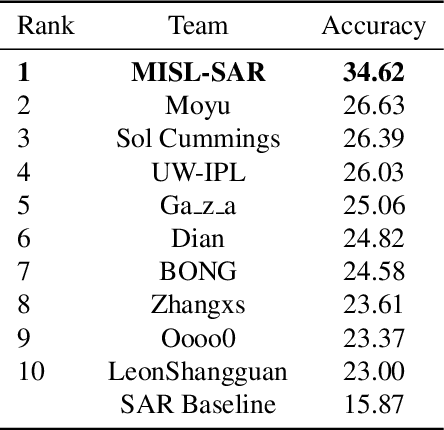
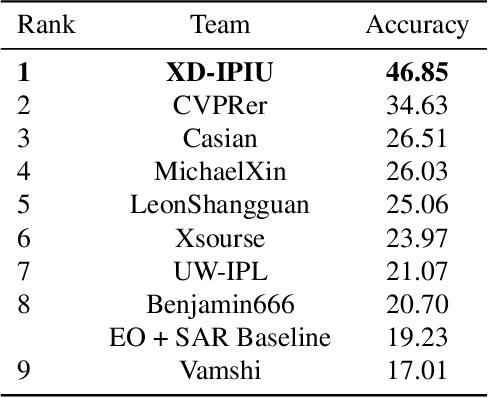
In this paper, we introduce the first Challenge on Multi-modal Aerial View Object Classification (MAVOC) in conjunction with the NTIRE 2021 workshop at CVPR. This challenge is composed of two different tracks using EO andSAR imagery. Both EO and SAR sensors possess different advantages and drawbacks. The purpose of this competition is to analyze how to use both sets of sensory information in complementary ways. We discuss the top methods submitted for this competition and evaluate their results on our blind test set. Our challenge results show significant improvement of more than 15% accuracy from our current baselines for each track of the competition
* 10 pages, 1 figure. Conference on Computer Vision and Pattern Recognition