 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergistic Deep Graph Clustering Network
Jun 22, 2024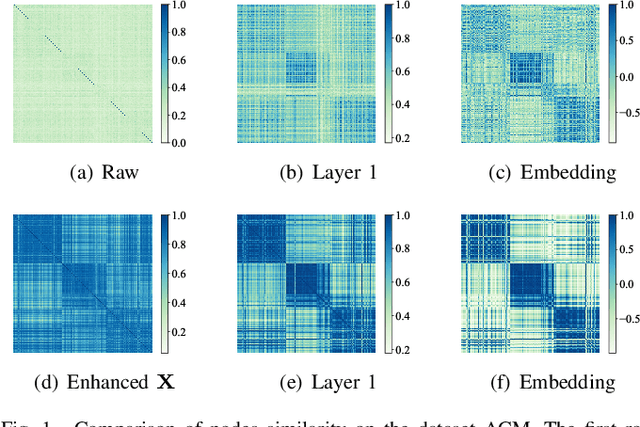
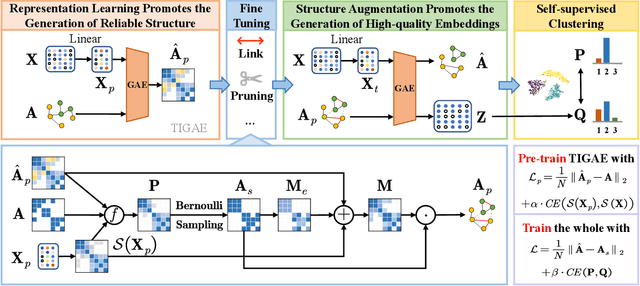
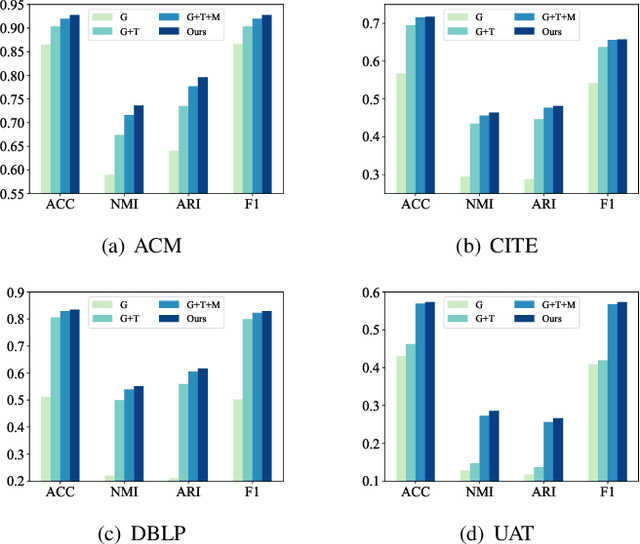
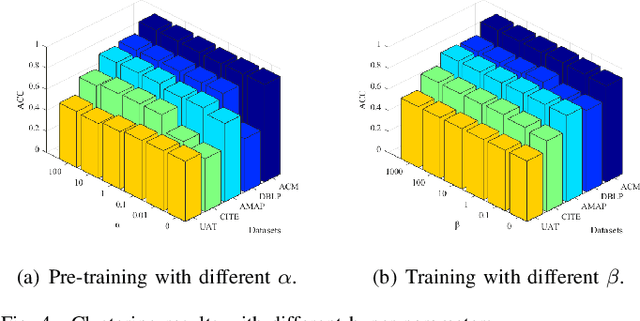
Employing graph neural networks (GNNs) to learn cohesive and discriminative node representations for clustering has shown promising results in deep graph clustering. However, existing methods disregard the reciprocal relationship between representation learning and structure augmentation. This study suggests that enhancing embedding and structure synergistically becomes imperative for GNNs to unleash their potential in deep graph clustering. A reliable structure promotes obtaining more cohesive node representations, while high-quality node representations can guide the augmentation of the structure, enhancing structural reliability in return. Moreover, the generalization ability of existing GNNs-based models is relatively poor. While they perform well on graphs with high homogeneity, they perform poorly on graphs with low homogeneity. To this end, we propose a graph clustering framework named Synergistic Deep Graph Clustering Network (SynC). In our approach, we design a Transform Input Graph Auto-Encoder (TIGAE) to obtain high-quality embeddings for guiding structure augmentation. Then, we re-capture neighborhood representations on the augmented graph to obtain clustering-friendly embeddings and conduct self-supervised clustering. Notably, representation learning and structure augmentation share weights, significantly reducing the number of model parameters. Additionally, we introduce a structure fine-tuning strategy to improve the model's generalization. Extensive experiments on benchmark datasets demonstrate the superiority and effectiveness of our method. The code is released on GitHub and Code Ocean.
TransMatting: Tri-token Equipped Transformer Model for Image Matting
Mar 11, 2023



Image matting aims to predict alpha values of elaborate uncertainty areas of natural images, like hairs, smoke, and spider web. However, existing methods perform poorly when faced with highly transparent foreground objects due to the large area of uncertainty to predict and the small receptive field of convolutional networks. To address this issue, we propose a Transformer-based network (TransMatting) to model transparent objects with long-range features and collect a high-resolution matting dataset of transparent objects (Transparent-460) for performance evaluation. Specifically, to utilize semantic information in the trimap flexibly and effectively, we also redesign the trimap as three learnable tokens, named tri-token. Both Transformer and convolution matting models could benefit from our proposed tri-token design. By replacing the traditional trimap concatenation strategy with our tri-token, existing matting methods could achieve about 10% improvement in SAD and 20% in MSE. Equipped with the new tri-token design, our proposed TransMatting outperforms current state-of-the-art methods on several popular matting benchmarks and our newly collected Transparent-460.
TransMatting: Enhancing Transparent Objects Matting with Transformers
Aug 05, 2022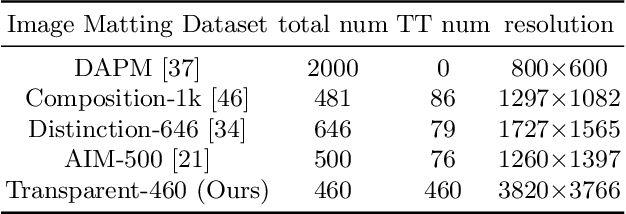
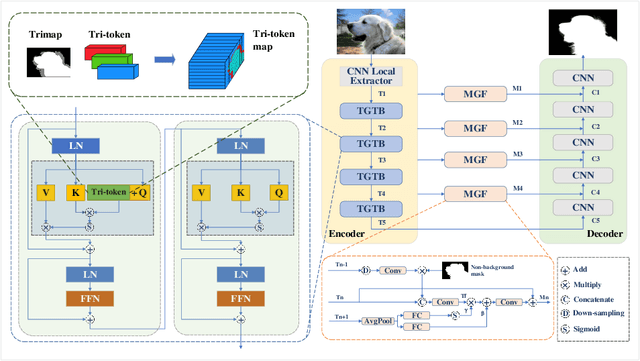
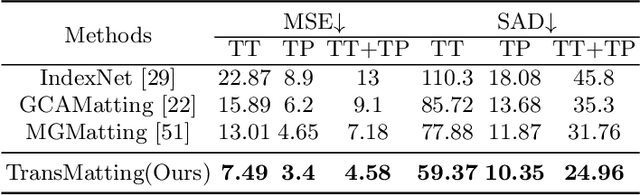

Image matting refers to predicting the alpha values of unknown foreground areas from natural images. Prior methods have focused on propagating alpha values from known to unknown regions. However, not all natural images have a specifically known foreground. Images of transparent objects, like glass, smoke, web, etc., have less or no known foreground. In this paper, we propose a Transformer-based network, TransMatting, to model transparent objects with a big receptive field. Specifically, we redesign the trimap as three learnable tri-tokens for introducing advanced semantic features into the self-attention mechanism. A small convolutional network is proposed to utilize the global feature and non-background mask to guide the multi-scale feature propagation from encoder to decoder for maintaining the contexture of transparent objects. In addition, we create a high-resolution matting dataset of transparent objects with small known foreground areas. Experiments on several matting benchmarks demonstrate the superiority of our proposed method over the current state-of-the-art methods.
When coding meets ranking: A joint framework based on local learning
Nov 02, 2016
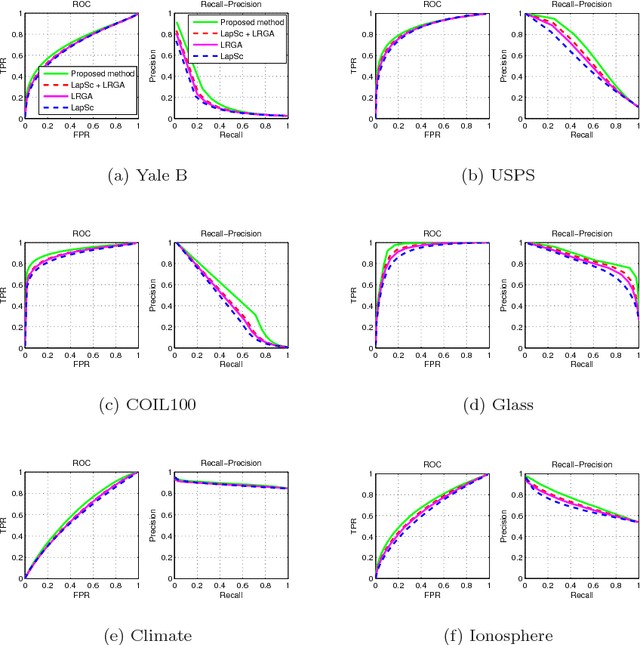
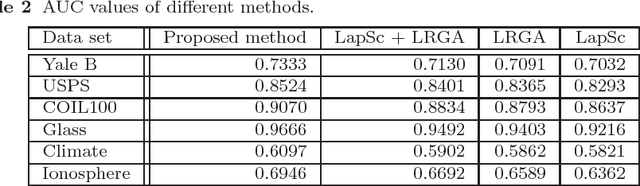
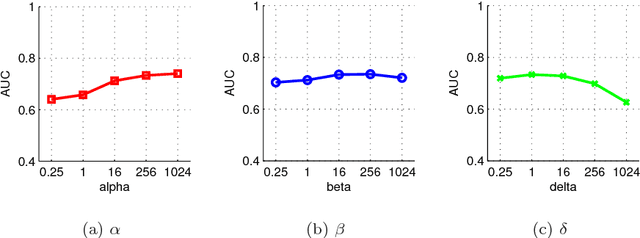
Sparse coding, which represents a data point as a sparse reconstruction code with regard to a dictionary, has been a popular data representation method. Meanwhile, in database retrieval problems, learning the ranking scores from data points plays an important role. Up to now, these two problems have always been considered separately, assuming that data coding and ranking are two independent and irrelevant problems. However, is there any internal relationship between sparse coding and ranking score learning? If yes, how to explore and make use of this internal relationship? In this paper, we try to answer these questions by developing the first joint sparse coding and ranking score learning algorithm. To explore the local distribution in the sparse code space, and also to bridge coding and ranking problems, we assume that in the neighborhood of each data point, the ranking scores can be approximated from the corresponding sparse codes by a local linear function. By considering the local approximation error of ranking scores, the reconstruction error and sparsity of sparse coding, and the query information provided by the user, we construct a unified objective function for learning of sparse codes, the dictionary and ranking scores. We further develop an iterative algorithm to solve this optimization problem.
Multi-tensor Completion for Estimating Missing Values in Video Data
Sep 01, 2014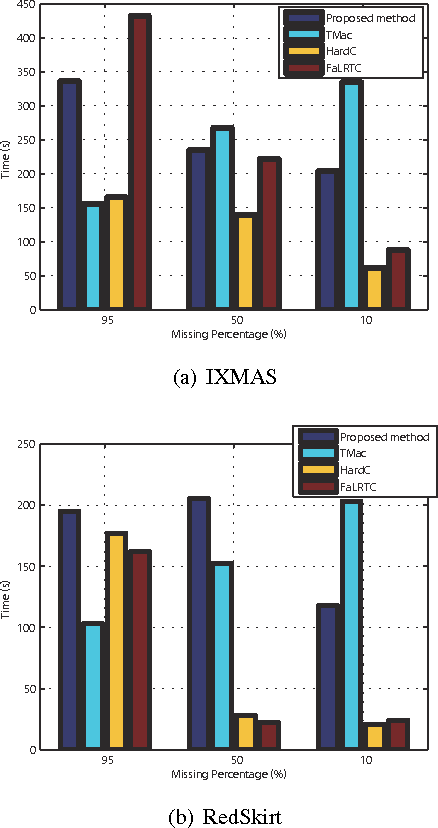
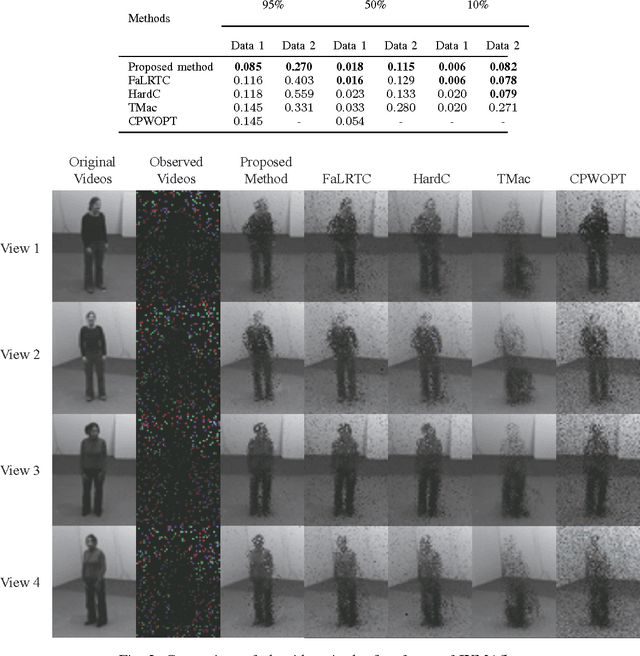
Many tensor-based data completion methods aim to solve image and video in-painting problems. But, all methods were only developed for a single dataset. In most of real applications, we can usually obtain more than one dataset to reflect one phenomenon, and all the datasets are mutually related in some sense. Thus one question raised whether such the relationship can improve the performance of data completion or not? In the paper, we proposed a novel and efficient method by exploiting the relationship among datasets for multi-video data completion. Numerical results show that the proposed method significantly improve the performance of video in-painting, particularly in the case of very high missing percentage.