 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEANCODE: Understanding Models Better for Code Simplification of Pre-trained Large Language Models
May 20, 2025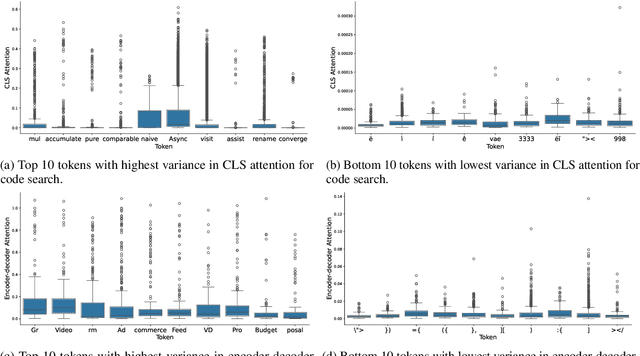
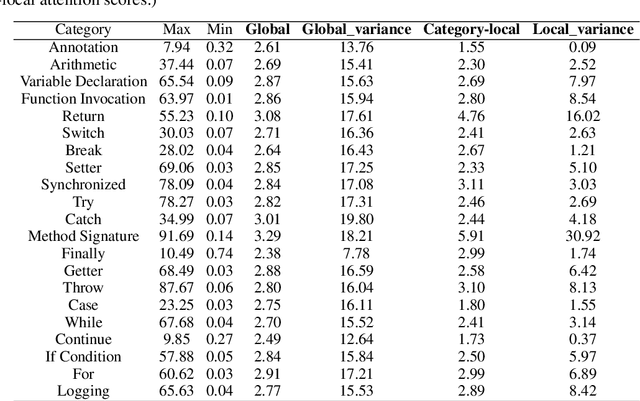
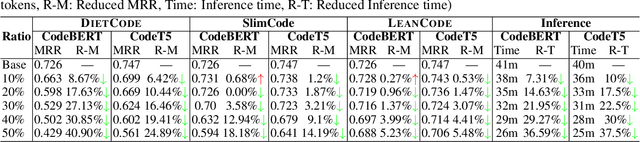

Large Language Models for code often entail significant computational complexity, which grows significantly with the length of the input code sequence. We propose LeanCode for code simplification to reduce training and prediction time, leveraging code contexts in utilizing attention scores to represent the tokens' importance. We advocate for the selective removal of tokens based on the average context-aware attention scores rather than average scores across all inputs. LeanCode uses the attention scores of `CLS' tokens within the encoder for classification tasks, such as code search. It also employs the encoder-decoder attention scores to determine token significance for sequence-to-sequence tasks like code summarization.Our evaluation shows LeanCode's superiority over the SOTAs DietCode and Slimcode, with improvements of 60% and 16% for code search, and 29% and 27% for code summarization, respectively.
Synergistic Deep Graph Clustering Network
Jun 22, 2024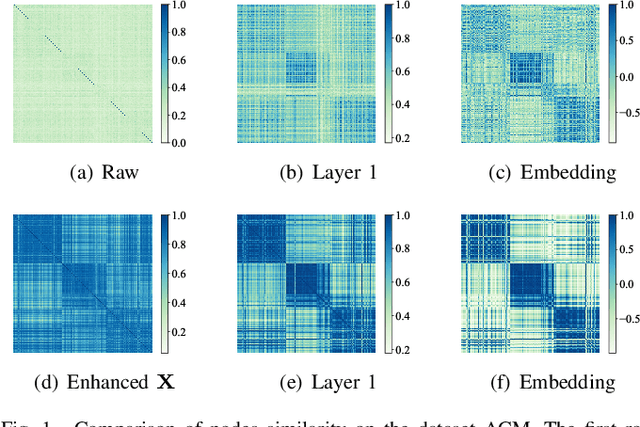
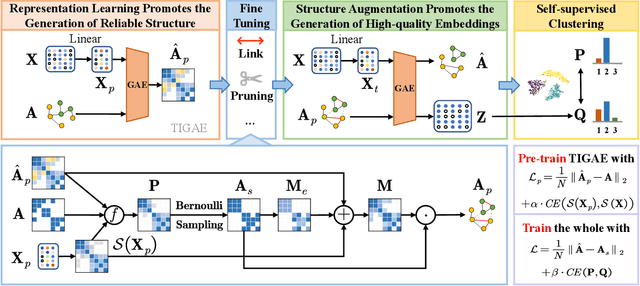
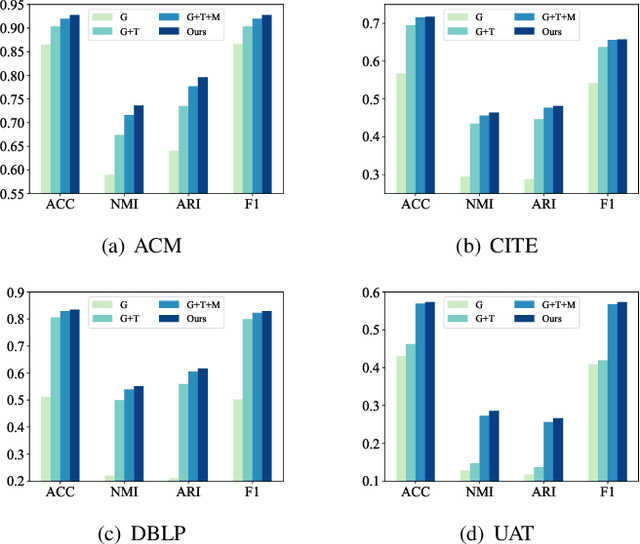
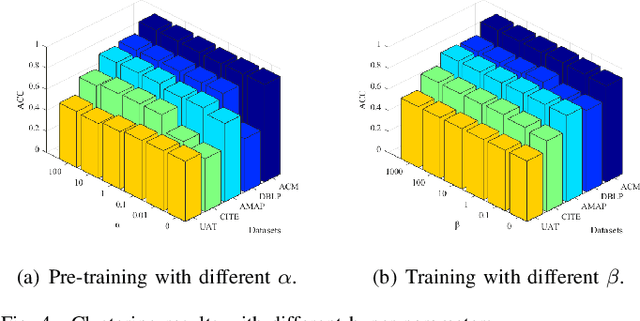
Employing graph neural networks (GNNs) to learn cohesive and discriminative node representations for clustering has shown promising results in deep graph clustering. However, existing methods disregard the reciprocal relationship between representation learning and structure augmentation. This study suggests that enhancing embedding and structure synergistically becomes imperative for GNNs to unleash their potential in deep graph clustering. A reliable structure promotes obtaining more cohesive node representations, while high-quality node representations can guide the augmentation of the structure, enhancing structural reliability in return. Moreover, the generalization ability of existing GNNs-based models is relatively poor. While they perform well on graphs with high homogeneity, they perform poorly on graphs with low homogeneity. To this end, we propose a graph clustering framework named Synergistic Deep Graph Clustering Network (SynC). In our approach, we design a Transform Input Graph Auto-Encoder (TIGAE) to obtain high-quality embeddings for guiding structure augmentation. Then, we re-capture neighborhood representations on the augmented graph to obtain clustering-friendly embeddings and conduct self-supervised clustering. Notably, representation learning and structure augmentation share weights, significantly reducing the number of model parameters. Additionally, we introduce a structure fine-tuning strategy to improve the model's generalization. Extensive experiments on benchmark datasets demonstrate the superiority and effectiveness of our method. The code is released on GitHub and Code Ocean.
PCIE_EgoHandPose Solution for EgoExo4D Hand Pose Challenge
Jun 18, 2024This report presents our team's 'PCIE_EgoHandPose' solution for the EgoExo4D Hand Pose Challenge at CVPR2024. The main goal of the challenge is to accurately estimate hand poses, which involve 21 3D joints, using an RGB egocentric video image provided for the task. This task is particularly challenging due to the subtle movements and occlusions. To handle the complexity of the task, we propose the Hand Pose Vision Transformer (HP-ViT). The HP-ViT comprises a ViT backbone and transformer head to estimate joint positions in 3D, utilizing MPJPE and RLE loss function. Our approach achieved the 1st position in the Hand Pose challenge with 25.51 MPJPE and 8.49 PA-MPJPE. Code is available at https://github.com/KanokphanL/PCIE_EgoHandPose
Domain Adversarial Active Learning for Domain Generalization Classification
Mar 10, 2024



Domain generalization models aim to learn cross-domain knowledge from source domain data, to improve performance on unknown target domains. Recent research has demonstrated that diverse and rich source domain samples can enhance domain generalization capability. This paper argues that the impact of each sample on the model's generalization ability varies. Despite its small scale, a high-quality dataset can still attain a certain level of generalization ability. Motivated by this, we propose a domain-adversarial active learning (DAAL) algorithm for classification tasks in domain generalization. First, we analyze that the objective of tasks is to maximize the inter-class distance within the same domain and minimize the intra-class distance across different domains. To achieve this objective, we design a domain adversarial selection method that prioritizes challenging samples. Second, we posit that even in a converged model, there are subsets of features that lack discriminatory power within each domain. We attempt to identify these feature subsets and optimize them by a constraint loss. We validate and analyze our DAAL algorithm on multiple domain generalization datasets, comparing it with various domain generalization algorithms and active learning algorithms. Our results demonstrate that the DAAL algorithm can achieve strong generalization ability with fewer data resources, thereby reducing data annotation costs in domain generalization tasks.
Incorporating Uncertain Segmentation Information into Chinese NER for Social Media Text
Apr 14, 2020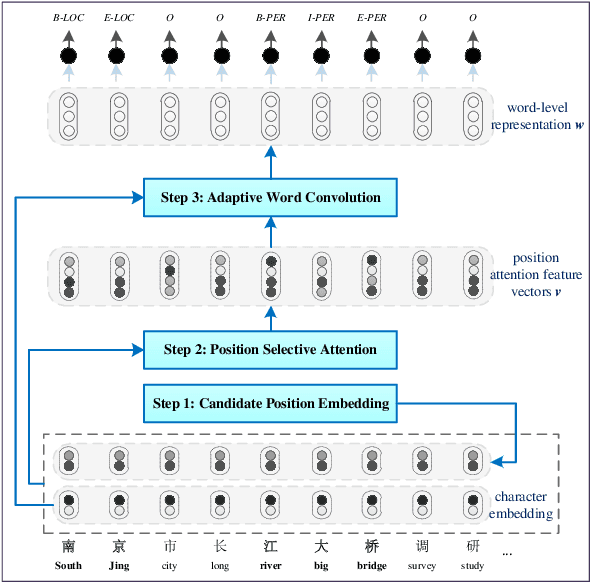
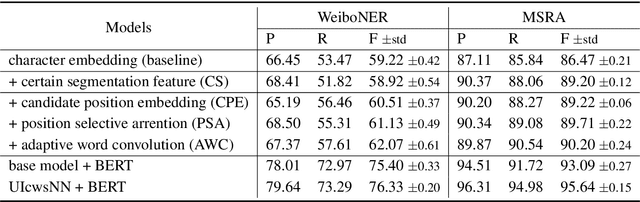
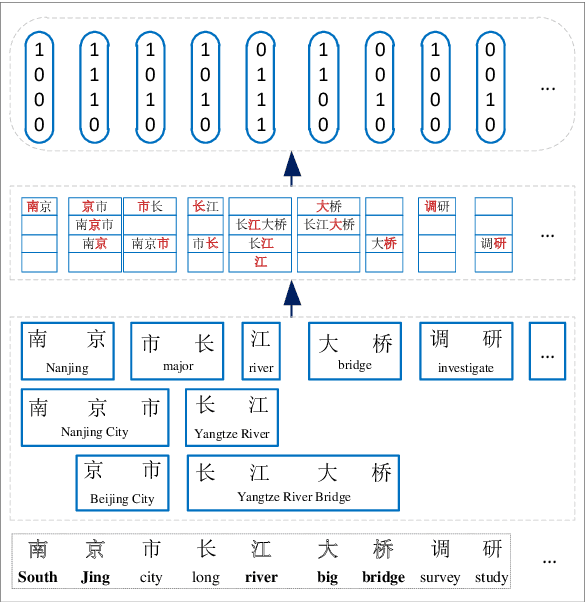
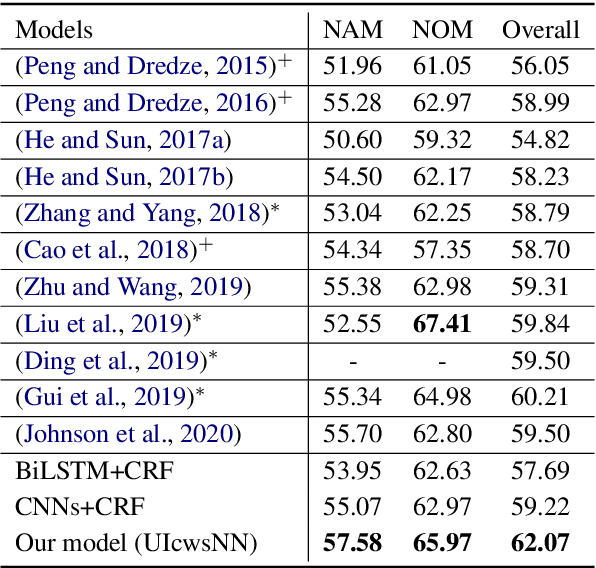
Chinese word segmentation is necessary to provide word-level information for Chinese named entity recognition (NER) systems. However, segmentation error propagation is a challenge for Chinese NER while processing colloquial data like social media text. In this paper, we propose a model (UIcwsNN) that specializes in identifying entities from Chinese social media text, especially by leveraging ambiguous information of word segmentation. Such uncertain information contains all the potential segmentation states of a sentence that provides a channel for the model to infer deep word-level characteristics. We propose a trilogy (i.e., candidate position embedding -> position selective attention -> adaptive word convolution) to encode uncertain word segmentation information and acquire appropriate word-level representation. Experiments results on the social media corpus show that our model alleviates the segmentation error cascading trouble effectively, and achieves a significant performance improvement of more than 2% over previous state-of-the-art methods.