 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Uncertain Segmentation Information into Chinese NER for Social Media Text
Paper and Code
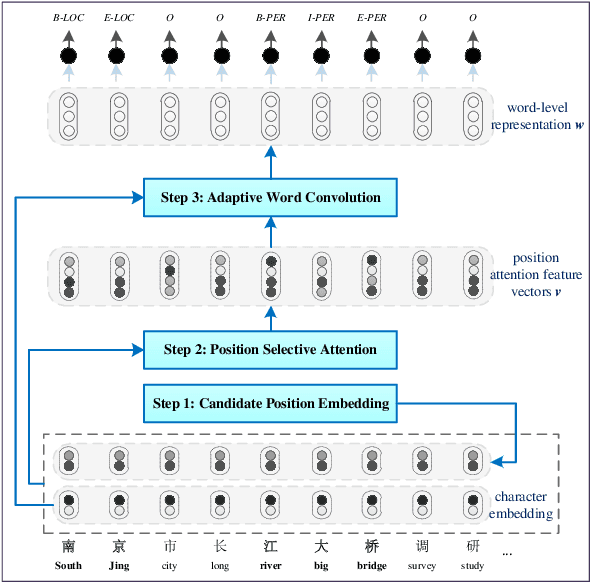
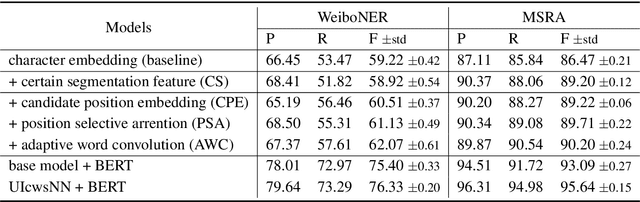
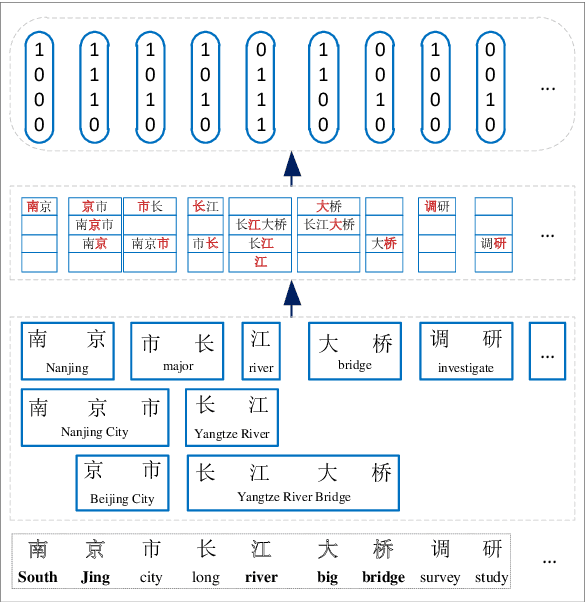
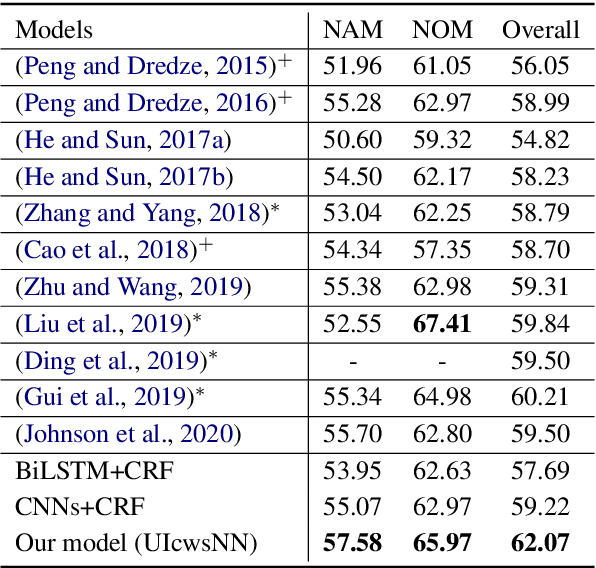
Chinese word segmentation is necessary to provide word-level information for Chinese named entity recognition (NER) systems. However, segmentation error propagation is a challenge for Chinese NER while processing colloquial data like social media text. In this paper, we propose a model (UIcwsNN) that specializes in identifying entities from Chinese social media text, especially by leveraging ambiguous information of word segmentation. Such uncertain information contains all the potential segmentation states of a sentence that provides a channel for the model to infer deep word-level characteristics. We propose a trilogy (i.e., candidate position embedding -> position selective attention -> adaptive word convolution) to encode uncertain word segmentation information and acquire appropriate word-level representation. Experiments results on the social media corpus show that our model alleviates the segmentation error cascading trouble effectively, and achieves a significant performance improvement of more than 2% over previous state-of-the-art methods.