 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncorporating Uncertain Segmentation Information into Chinese NER for Social Media Text
Apr 14, 2020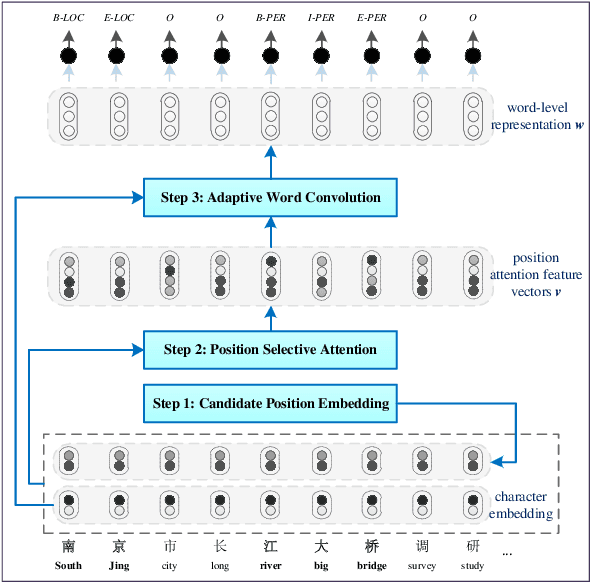
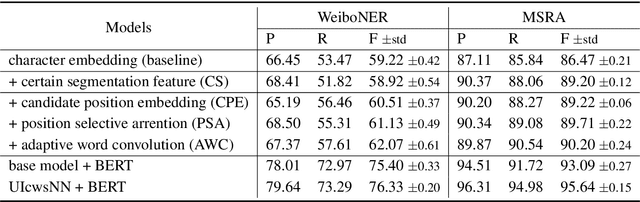
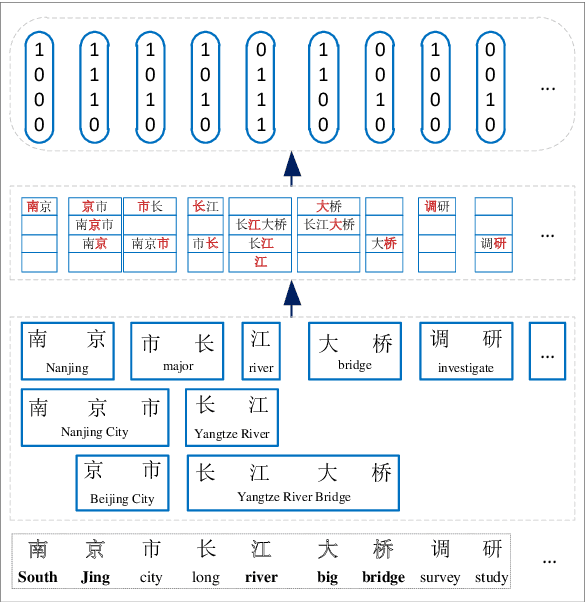
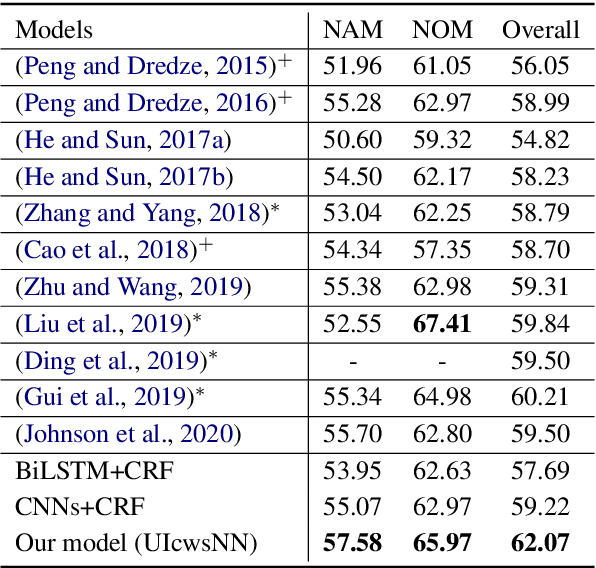
Chinese word segmentation is necessary to provide word-level information for Chinese named entity recognition (NER) systems. However, segmentation error propagation is a challenge for Chinese NER while processing colloquial data like social media text. In this paper, we propose a model (UIcwsNN) that specializes in identifying entities from Chinese social media text, especially by leveraging ambiguous information of word segmentation. Such uncertain information contains all the potential segmentation states of a sentence that provides a channel for the model to infer deep word-level characteristics. We propose a trilogy (i.e., candidate position embedding -> position selective attention -> adaptive word convolution) to encode uncertain word segmentation information and acquire appropriate word-level representation. Experiments results on the social media corpus show that our model alleviates the segmentation error cascading trouble effectively, and achieves a significant performance improvement of more than 2% over previous state-of-the-art methods.
Supervised Neural Models Revitalize the Open Relation Extraction
Aug 16, 2019



Open relation extraction (ORE) remains a challenge to obtain a semantic representation by discovering arbitrary relation tuples from the un-structured text. However, perhaps due to limited data, previous extractors use unsupervised or semi-supervised methods based on pattern matching, which heavily depend on manual work or syntactic parsers and are inefficient or error-cascading. Their development has encountered bottlenecks. Although a few people try to use neural network based models to improve the ORE task performance recently, it is always intractable for ORE to produce supervised systems based on various neural architectures. We analyze and review the neural ORE methods. Further, we construct a large-scale automatically tagging training set and design a tagging scheme to frame ORE as a supervised sequence tagging task. A hybrid neural sequence tagging model (NST) is proposed which combines BiLSTM, CNN and CRF to capture the contextual temporal information, local spatial information, and sentence level tag information of the sequence by using the word and part-of-speech embeddings. Experiments on multiple datasets show that our method is better than most of the existing pattern-based methods and other neural networks based models.
Knowledge Graph Error detection and Completion
Nov 06, 2018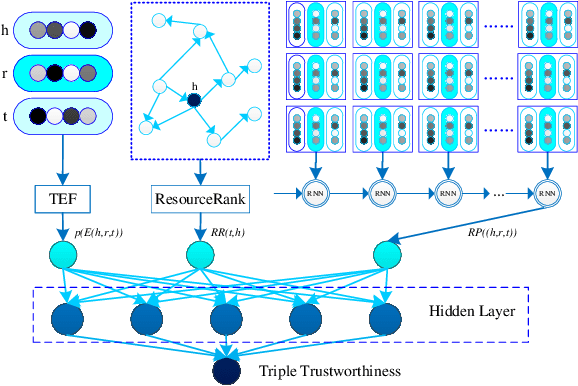

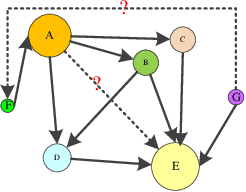
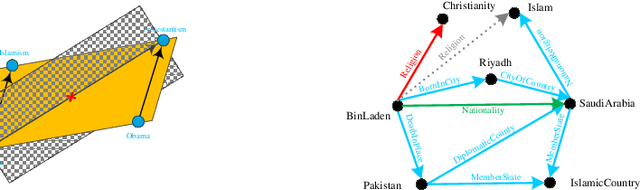
In the era of big data, people face enormous challenges in acquiring information and knowledge. A knowledge graph (KG) lays the foundation for the knowledge-based organization and intelligent application in the Internet age with its powerful semantic processing capabilities and open organization capabilities. In recent years, the research and applications of large-scale knowledge graph libraries have attracted increasing attention in academic and industrial circles. The knowledge graph aims to describe the various entities or concepts and their relationships existing in the objective world, which constitutes a huge semantic network map. It usually stores knowledge in the form of triples (head entity, relationship, tail entity), which can be simplified to $(h, r, t)$.