 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Neural Models Revitalize the Open Relation Extraction
Aug 16, 2019



Open relation extraction (ORE) remains a challenge to obtain a semantic representation by discovering arbitrary relation tuples from the un-structured text. However, perhaps due to limited data, previous extractors use unsupervised or semi-supervised methods based on pattern matching, which heavily depend on manual work or syntactic parsers and are inefficient or error-cascading. Their development has encountered bottlenecks. Although a few people try to use neural network based models to improve the ORE task performance recently, it is always intractable for ORE to produce supervised systems based on various neural architectures. We analyze and review the neural ORE methods. Further, we construct a large-scale automatically tagging training set and design a tagging scheme to frame ORE as a supervised sequence tagging task. A hybrid neural sequence tagging model (NST) is proposed which combines BiLSTM, CNN and CRF to capture the contextual temporal information, local spatial information, and sentence level tag information of the sequence by using the word and part-of-speech embeddings. Experiments on multiple datasets show that our method is better than most of the existing pattern-based methods and other neural networks based models.
Representation Learning Models for Entity Search
Jan 15, 2017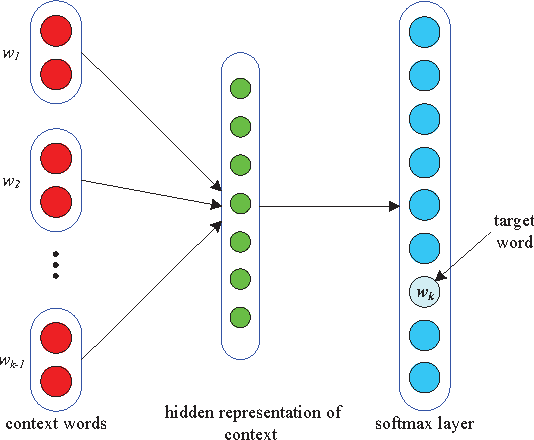


We focus on the problem of learning distributed representations for entity search queries, named entities, and their short descriptions. With our representation learning models, the entity search query, named entity and description can be represented as low-dimensional vectors. Our goal is to develop a simple but effective model that can make the distributed representations of query related entities similar to the query in the vector space. Hence, we propose three kinds of learning strategies, and the difference between them mainly lies in how to deal with the relationship between an entity and its description. We analyze the strengths and weaknesses of each learning strategy and validate our methods on public datasets which contain four kinds of named entities, i.e., movies, TV shows, restaurants and celebrities. The experimental results indicate that our proposed methods can adapt to different types of entity search queries, and outperform the current state-of-the-art methods based on keyword matching and vanilla word2vec models. Besides, the proposed methods can be trained fast and be easily extended to other similar tasks.