 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgriAgent: Contract-Driven Planning and Capability-Aware Tool Orchestration in Real-World Agriculture
Jan 13, 2026Intelligent agent systems in real-world agricultural scenarios must handle diverse tasks under multimodal inputs, ranging from lightweight information understanding to complex multi-step execution. However, most existing approaches rely on a unified execution paradigm, which struggles to accommodate large variations in task complexity and incomplete tool availability commonly observed in agricultural environments. To address this challenge, we propose AgriAgent, a two-level agent framework for real-world agriculture. AgriAgent adopts a hierarchical execution strategy based on task complexity: simple tasks are handled through direct reasoning by modality-specific agents, while complex tasks trigger a contract-driven planning mechanism that formulates tasks as capability requirements and performs capability-aware tool orchestration and dynamic tool generation, enabling multi-step and verifiable execution with failure recovery. Experimental results show that AgriAgent achieves higher execution success rates and robustness on complex tasks compared to existing tool-centric agent baselines that rely on unified execution paradigms. All code, data will be released at after our work be accepted to promote reproducible research.
Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition
Dec 17, 2025Recent visual generative models often struggle with consistency during image editing due to the entangled nature of raster images, where all visual content is fused into a single canvas. In contrast, professional design tools employ layered representations, allowing isolated edits while preserving consistency. Motivated by this, we propose \textbf{Qwen-Image-Layered}, an end-to-end diffusion model that decomposes a single RGB image into multiple semantically disentangled RGBA layers, enabling \textbf{inherent editability}, where each RGBA layer can be independently manipulated without affecting other content. To support variable-length decomposition, we introduce three key components: (1) an RGBA-VAE to unify the latent representations of RGB and RGBA images; (2) a VLD-MMDiT (Variable Layers Decomposition MMDiT) architecture capable of decomposing a variable number of image layers; and (3) a Multi-stage Training strategy to adapt a pretrained image generation model into a multilayer image decomposer. Furthermore, to address the scarcity of high-quality multilayer training images, we build a pipeline to extract and annotate multilayer images from Photoshop documents (PSD). Experiments demonstrate that our method significantly surpasses existing approaches in decomposition quality and establishes a new paradigm for consistent image editing. Our code and models are released on \href{https://github.com/QwenLM/Qwen-Image-Layered}{https://github.com/QwenLM/Qwen-Image-Layered}
AgriGPT-Omni: A Unified Speech-Vision-Text Framework for Multilingual Agricultural Intelligence
Dec 11, 2025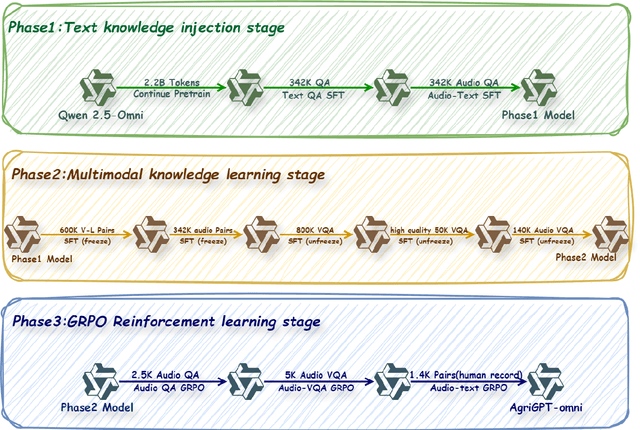
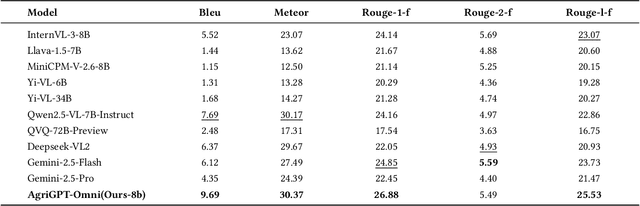
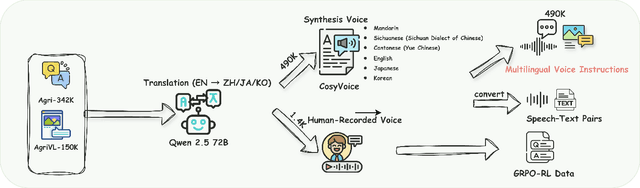
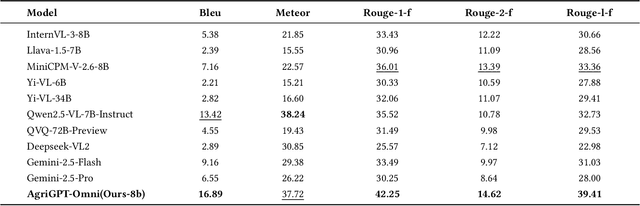
Despite rapid advances in multimodal large language models, agricultural applications remain constrained by the lack of multilingual speech data, unified multimodal architectures, and comprehensive evaluation benchmarks. To address these challenges, we present AgriGPT-Omni, an agricultural omni-framework that integrates speech, vision, and text in a unified framework. First, we construct a scalable data synthesis and collection pipeline that converts agricultural texts and images into training data, resulting in the largest agricultural speech dataset to date, including 492K synthetic and 1.4K real speech samples across six languages. Second, based on this, we train the first agricultural omni-model via a three-stage paradigm: textual knowledge injection, progressive multimodal alignment, and GRPO-based reinforcement learning, enabling unified reasoning across languages and modalities. Third, we propose AgriBench-Omni-2K, the first tri-modal benchmark for agriculture, covering diverse speech-vision-text tasks and multilingual slices, with standardized protocols and reproducible tools. Experiments show that AgriGPT-Omni significantly outperforms general-purpose baselines on multilingual and multimodal reasoning as well as real-world speech understanding. All models, data, benchmarks, and code will be released to promote reproducible research, inclusive agricultural intelligence, and sustainable AI development for low-resource regions.
AgriGPT: a Large Language Model Ecosystem for Agriculture
Aug 12, 2025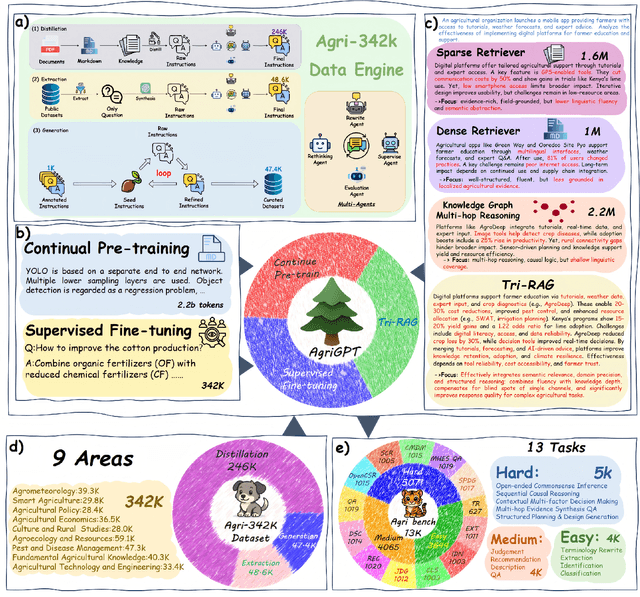
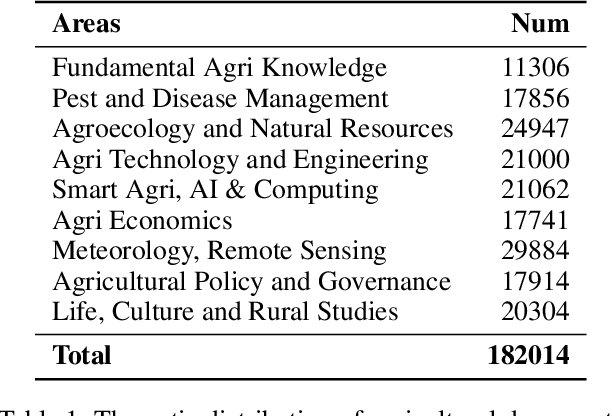
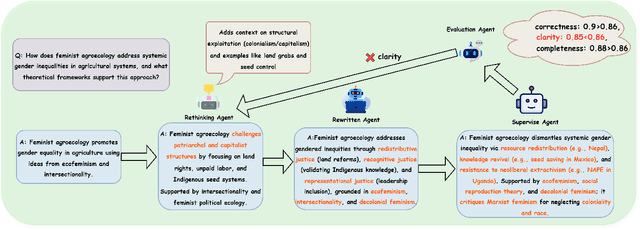
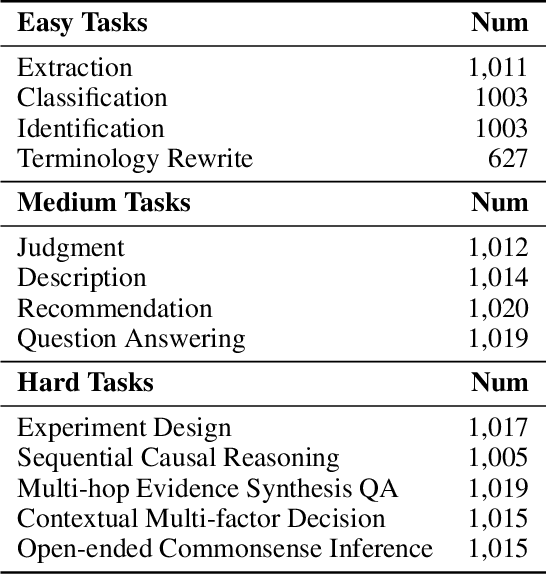
Despite the rapid progress of Large Language Models (LLMs), their application in agriculture remains limited due to the lack of domain-specific models, curated datasets, and robust evaluation frameworks. To address these challenges, we propose AgriGPT, a domain-specialized LLM ecosystem for agricultural usage. At its core, we design a multi-agent scalable data engine that systematically compiles credible data sources into Agri-342K, a high-quality, standardized question-answer (QA) dataset. Trained on this dataset, AgriGPT supports a broad range of agricultural stakeholders, from practitioners to policy-makers. To enhance factual grounding, we employ Tri-RAG, a three-channel Retrieval-Augmented Generation framework combining dense retrieval, sparse retrieval, and multi-hop knowledge graph reasoning, thereby improving the LLM's reasoning reliability. For comprehensive evaluation, we introduce AgriBench-13K, a benchmark suite comprising 13 tasks with varying types and complexities. Experiments demonstrate that AgriGPT significantly outperforms general-purpose LLMs on both domain adaptation and reasoning. Beyond the model itself, AgriGPT represents a modular and extensible LLM ecosystem for agriculture, comprising structured data construction, retrieval-enhanced generation, and domain-specific evaluation. This work provides a generalizable framework for developing scientific and industry-specialized LLMs. All models, datasets, and code will be released to empower agricultural communities, especially in underserved regions, and to promote open, impactful research.
Touch-Augmented Gaussian Splatting for Enhanced 3D Scene Reconstruction
Aug 11, 2025This paper presents a multimodal framework that integrates touch signals (contact points and surface normals) into 3D Gaussian Splatting (3DGS). Our approach enhances scene reconstruction, particularly under challenging conditions like low lighting, limited camera viewpoints, and occlusions. Different from the visual-only method, the proposed approach incorporates spatially selective touch measurements to refine both the geometry and appearance of the 3D Gaussian representation. To guide the touch exploration, we introduce a two-stage sampling scheme that initially probes sparse regions and then concentrates on high-uncertainty boundaries identified from the reconstructed mesh. A geometric loss is proposed to ensure surface smoothness, resulting in improved geometry. Experimental results across diverse scenarios show consistent improvements in geometric accuracy. In the most challenging case with severe occlusion, the Chamfer Distance is reduced by over 15x, demonstrating the effectiveness of integrating touch cues into 3D Gaussian Splatting. Furthermore, our approach maintains a fully online pipeline, underscoring its feasibility in visually degraded environments.
Manager: Aggregating Insights from Unimodal Experts in Two-Tower VLMs and MLLMs
Jun 13, 2025Two-Tower Vision--Language Models (VLMs) have demonstrated strong performance across various downstream VL tasks. While BridgeTower further enhances performance by building bridges between encoders, it \textit{(i)} suffers from ineffective layer-by-layer utilization of unimodal representations, \textit{(ii)} restricts the flexible exploitation of different levels of unimodal semantic knowledge, and \textit{(iii)} is limited to the evaluation on traditional low-resolution datasets only with the Two-Tower VLM architecture. In this work, we propose Manager, a lightweight, efficient and effective plugin that adaptively aggregates insights from different levels of pre-trained unimodal experts to facilitate more comprehensive VL alignment and fusion. First, under the Two-Tower VLM architecture, we introduce ManagerTower, a novel VLM that introduces the manager in each cross-modal layer. Whether with or without VL pre-training, ManagerTower outperforms previous strong baselines and achieves superior performance on 4 downstream VL tasks. Moreover, we extend our exploration to the latest Multimodal Large Language Model (MLLM) architecture. We demonstrate that LLaVA-OV-Manager significantly boosts the zero-shot performance of LLaVA-OV across different categories of capabilities, images, and resolutions on 20 downstream datasets, whether the multi-grid algorithm is enabled or not. In-depth analysis reveals that both our manager and the multi-grid algorithm can be viewed as a plugin that improves the visual representation by capturing more diverse visual details from two orthogonal perspectives (depth and width). Their synergy can mitigate the semantic ambiguity caused by the multi-grid algorithm and further improve performance. Code and models are available at https://github.com/LooperXX/ManagerTower.
Visual Thoughts: A Unified Perspective of Understanding Multimodal Chain-of-Thought
May 21, 2025Large Vision-Language Models (LVLMs) have achieved significant success in multimodal tasks, with multimodal chain-of-thought (MCoT) further enhancing performance and interpretability. Recent MCoT methods fall into two categories: (i) Textual-MCoT (T-MCoT), which takes multimodal input and produces textual output; and (ii) Interleaved-MCoT (I-MCoT), which generates interleaved image-text outputs. Despite advances in both approaches, the mechanisms driving these improvements are not fully understood. To fill this gap, we first reveal that MCoT boosts LVLMs by incorporating visual thoughts, which convey image information to the reasoning process regardless of the MCoT format, depending only on clarity and conciseness of expression. Furthermore, to explore visual thoughts systematically, we define four distinct forms of visual thought expressions and analyze them comprehensively. Our findings demonstrate that these forms differ in clarity and conciseness, yielding varying levels of MCoT improvement. Additionally, we explore the internal nature of visual thoughts, finding that visual thoughts serve as intermediaries between the input image and reasoning to deeper transformer layers, enabling more advanced visual information transmission. We hope that the visual thoughts can inspire further breakthroughs for future MCoT research.
DeepNuParc: A Novel Deep Clustering Framework for Fine-scale Parcellation of Brain Nuclei Using Diffusion MRI Tractography
Mar 10, 2025



Brain nuclei are clusters of anatomically distinct neurons that serve as important hubs for processing and relaying information in various neural circuits. Fine-scale parcellation of the brain nuclei is vital for a comprehensive understanding of its anatomico-functional correlations. Diffusion MRI tractography is an advanced imaging technique that can estimate the brain's white matter structural connectivity to potentially reveal the topography of the nuclei of interest for studying its subdivisions. In this work, we present a deep clustering pipeline, namely DeepNuParc, to perform automated, fine-scale parcellation of brain nuclei using diffusion MRI tractography. First, we incorporate a newly proposed deep learning approach to enable accurate segmentation of the nuclei of interest directly on the dMRI data. Next, we design a novel streamline clustering-based structural connectivity feature for a robust representation of voxels within the nuclei. Finally, we improve the popular joint dimensionality reduction and k-means clustering approach to enable nuclei parcellation at a finer scale. We demonstrate DeepNuParc on two important brain structures, i.e. the amygdala and the thalamus, that are known to have multiple anatomically and functionally distinct nuclei subdivisions. Experimental results show that DeepNuParc enables consistent parcellation of the nuclei into multiple parcels across multiple subjects and achieves good correspondence with the widely used coarse-scale atlases. Our codes are available at https://github.com/HarlandZZC/deep_nuclei_parcellation.
Enhanced SPS Velocity-adaptive Scheme: Access Fairness in 5G NR V2I Networks
Jan 16, 2025



Vehicle-to-Infrastructure (V2I) technology enables information exchange between vehicles and road infrastructure. Specifically, when a vehicle approaches a roadside unit (RSU), it can exchange information with the RSU to obtain accurate data that assists in driving. With the release of the 3rd Generation Partnership Project (3GPP) Release 16, which includes the 5G New Radio (NR) Vehicle-to-Everything (V2X) standards, vehicles typically adopt mode-2 communication using sensing-based semi-persistent scheduling (SPS) for resource allocation. In this approach, vehicles identify candidate resources within a selection window and exclude ineligible resources based on information from a sensing window. However, vehicles often drive at different speeds, resulting in varying amounts of data transmission with RSUs as they pass by, which leads to unfair access. Therefore, it is essential to design an access scheme that accounts for different vehicle speeds to achieve fair access across the network. This paper formulates an optimization problem for vehicular networks and proposes a multi-objective optimization scheme to address it by adjusting the selection window in the SPS mechanism of 5G NR V2I mode-2. Simulation results demonstrate the effectiveness of the proposed scheme
Can Large Language Models Understand You Better? An MBTI Personality Detection Dataset Aligned with Population Traits
Dec 17, 2024
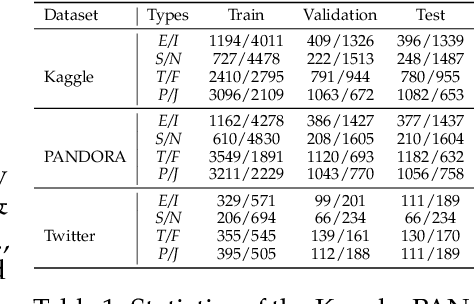
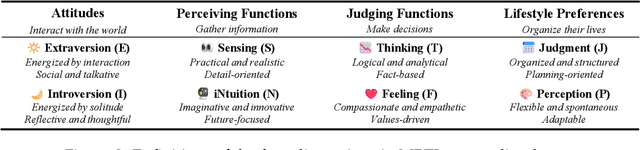
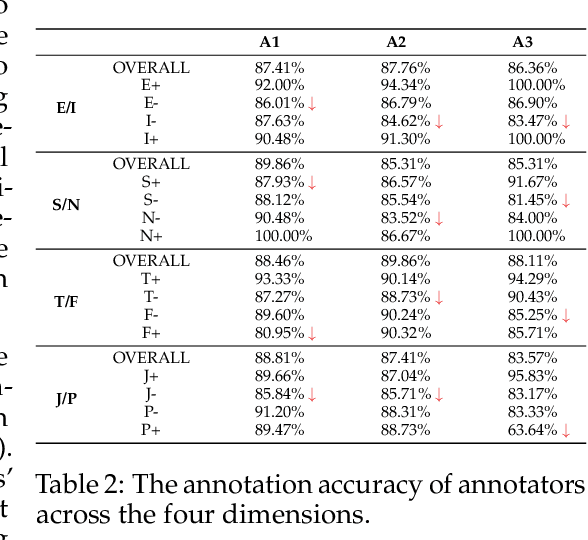
The Myers-Briggs Type Indicator (MBTI) is one of the most influential personality theories reflecting individual differences in thinking, feeling, and behaving. MBTI personality detection has garnered considerable research interest and has evolved significantly over the years. However, this task tends to be overly optimistic, as it currently does not align well with the natural distribution of population personality traits. Specifically, (1) the self-reported labels in existing datasets result in incorrect labeling issues, and (2) the hard labels fail to capture the full range of population personality distributions. In this paper, we optimize the task by constructing MBTIBench, the first manually annotated high-quality MBTI personality detection dataset with soft labels, under the guidance of psychologists. As for the first challenge, MBTIBench effectively solves the incorrect labeling issues, which account for 29.58% of the data. As for the second challenge, we estimate soft labels by deriving the polarity tendency of samples. The obtained soft labels confirm that there are more people with non-extreme personality traits. Experimental results not only highlight the polarized predictions and biases in LLMs as key directions for future research, but also confirm that soft labels can provide more benefits to other psychological tasks than hard labels. The code and data are available at https://github.com/Personality-NLP/MbtiBench.