 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQFormer: Towards Unified LiDAR Panoptic Segmentation with Decoupled Queries
Aug 28, 2024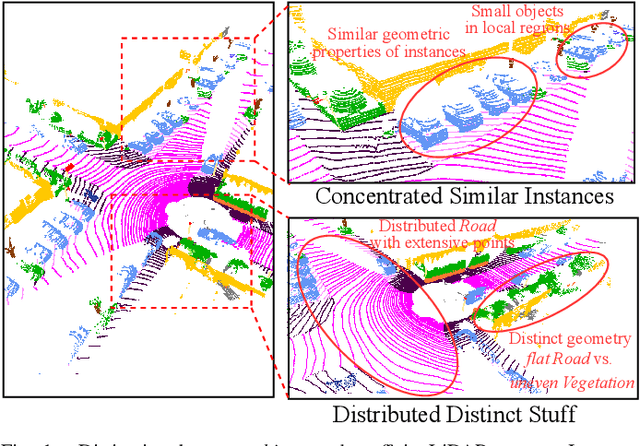
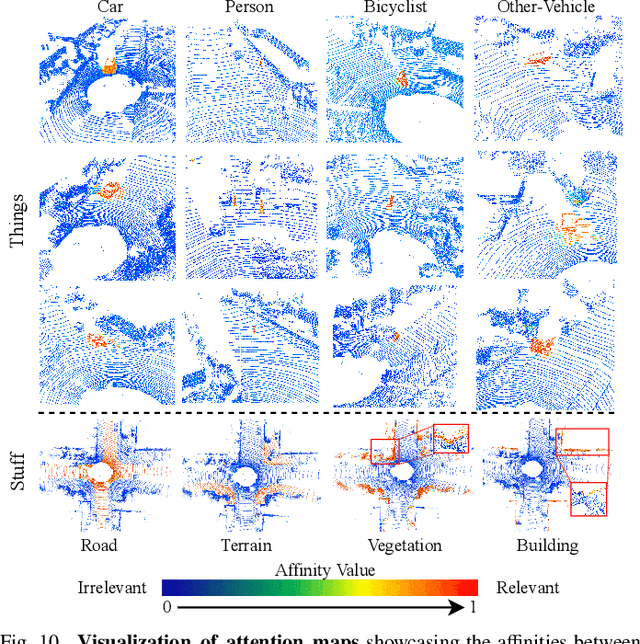
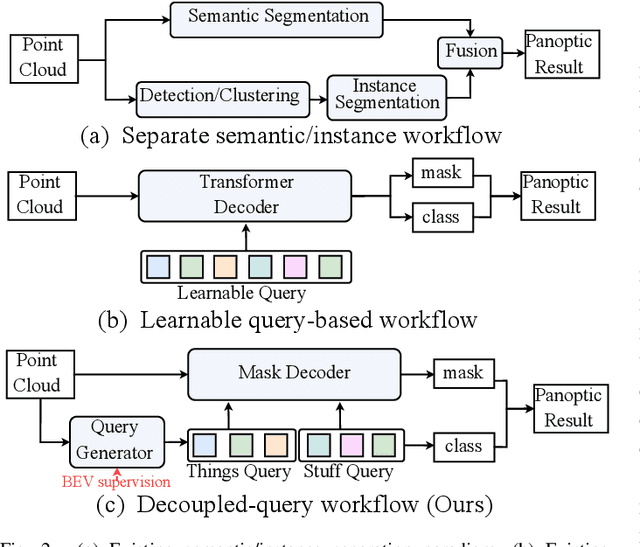
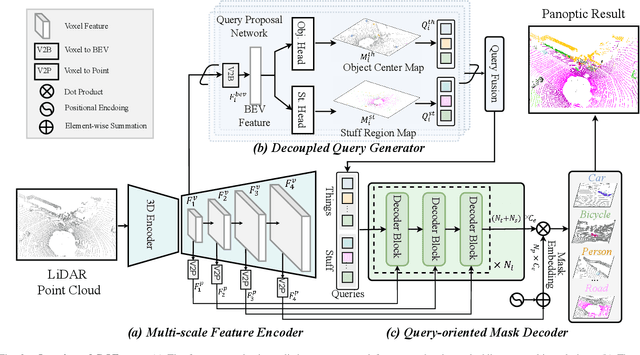
LiDAR panoptic segmentation, which jointly performs instance and semantic segmentation for things and stuff classes, plays a fundamental role in LiDAR perception tasks. While most existing methods explicitly separate these two segmentation tasks and utilize different branches (i.e., semantic and instance branches), some recent methods have embraced the query-based paradigm to unify LiDAR panoptic segmentation. However, the distinct spatial distribution and inherent characteristics of objects(things) and their surroundings(stuff) in 3D scenes lead to challenges, including the mutual competition of things/stuff and the ambiguity of classification/segmentation. In this paper, we propose decoupling things/stuff queries according to their intrinsic properties for individual decoding and disentangling classification/segmentation to mitigate ambiguity. To this end, we propose a novel framework dubbed DQFormer to implement semantic and instance segmentation in a unified workflow. Specifically, we design a decoupled query generator to propose informative queries with semantics by localizing things/stuff positions and fusing multi-level BEV embeddings. Moreover, a query-oriented mask decoder is introduced to decode corresponding segmentation masks by performing masked cross-attention between queries and mask embeddings. Finally, the decoded masks are combined with the semantics of the queries to produce panoptic results. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the superiority of our DQFormer framework.
Camera-based 3D Semantic Scene Completion with Sparse Guidance Network
Dec 10, 2023



Semantic scene completion (SSC) aims to predict the semantic occupancy of each voxel in the entire 3D scene from limited observations, which is an emerging and critical task for autonomous driving. Recently, many studies have turned to camera-based SSC solutions due to the richer visual cues and cost-effectiveness of cameras. However, existing methods usually rely on sophisticated and heavy 3D models to directly process the lifted 3D features that are not discriminative enough for clear segmentation boundaries. In this paper, we adopt the dense-sparse-dense design and propose an end-to-end camera-based SSC framework, termed SGN, to diffuse semantics from the semantic- and occupancy-aware seed voxels to the whole scene based on geometry prior and occupancy information. By designing hybrid guidance (sparse semantic and geometry guidance) and effective voxel aggregation for spatial occupancy and geometry priors, we enhance the feature separation between different categories and expedite the convergence of semantic diffusion. Extensive experimental results on the SemanticKITTI dataset demonstrate the superiority of our SGN over existing state-of-the-art methods.