 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDQFormer: Towards Unified LiDAR Panoptic Segmentation with Decoupled Queries
Aug 28, 2024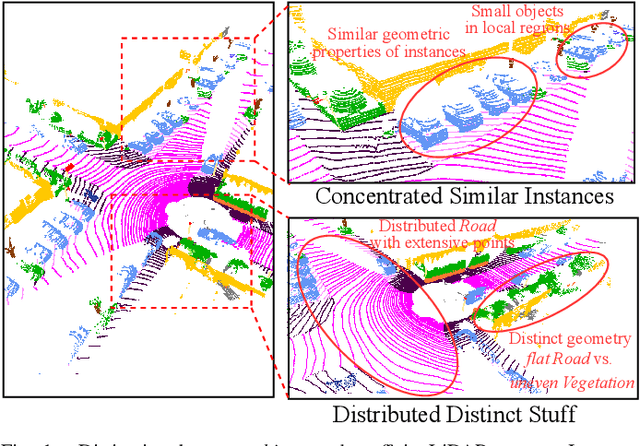
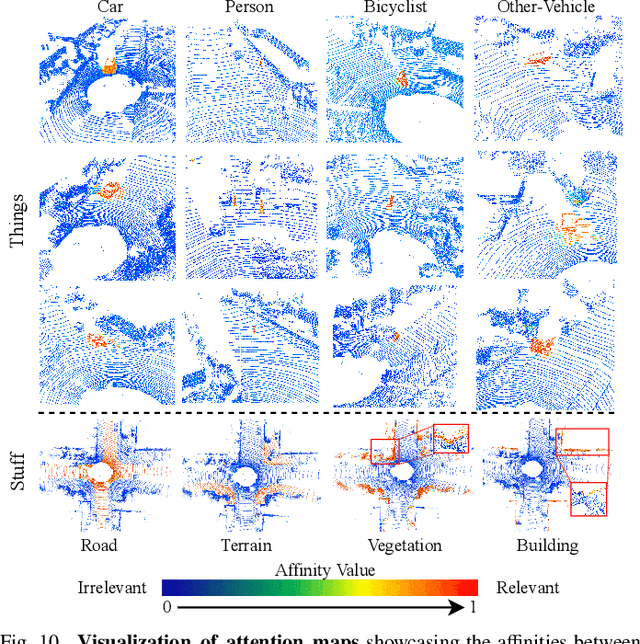
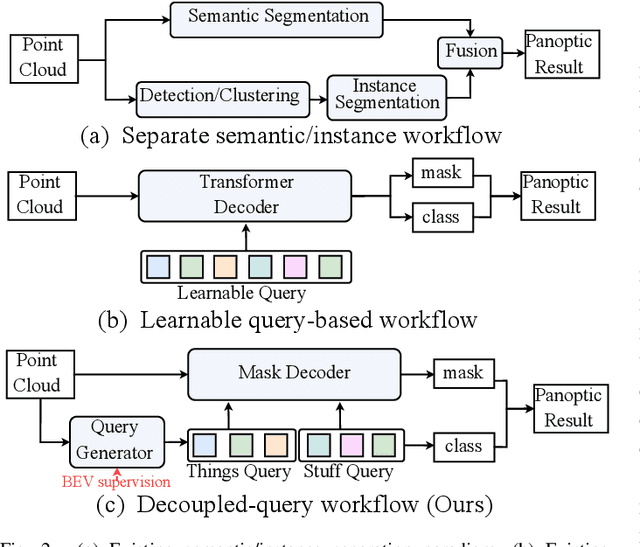
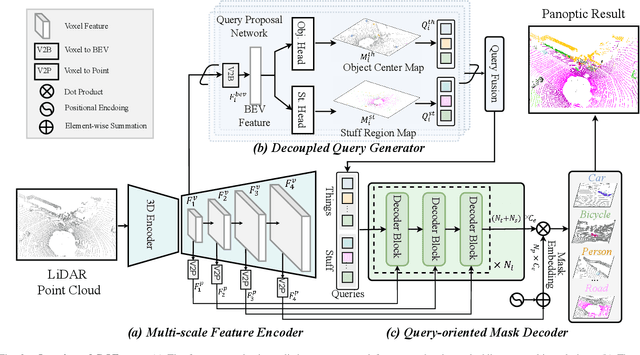
LiDAR panoptic segmentation, which jointly performs instance and semantic segmentation for things and stuff classes, plays a fundamental role in LiDAR perception tasks. While most existing methods explicitly separate these two segmentation tasks and utilize different branches (i.e., semantic and instance branches), some recent methods have embraced the query-based paradigm to unify LiDAR panoptic segmentation. However, the distinct spatial distribution and inherent characteristics of objects(things) and their surroundings(stuff) in 3D scenes lead to challenges, including the mutual competition of things/stuff and the ambiguity of classification/segmentation. In this paper, we propose decoupling things/stuff queries according to their intrinsic properties for individual decoding and disentangling classification/segmentation to mitigate ambiguity. To this end, we propose a novel framework dubbed DQFormer to implement semantic and instance segmentation in a unified workflow. Specifically, we design a decoupled query generator to propose informative queries with semantics by localizing things/stuff positions and fusing multi-level BEV embeddings. Moreover, a query-oriented mask decoder is introduced to decode corresponding segmentation masks by performing masked cross-attention between queries and mask embeddings. Finally, the decoded masks are combined with the semantics of the queries to produce panoptic results. Extensive experiments on nuScenes and SemanticKITTI datasets demonstrate the superiority of our DQFormer framework.
Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
Aug 26, 2024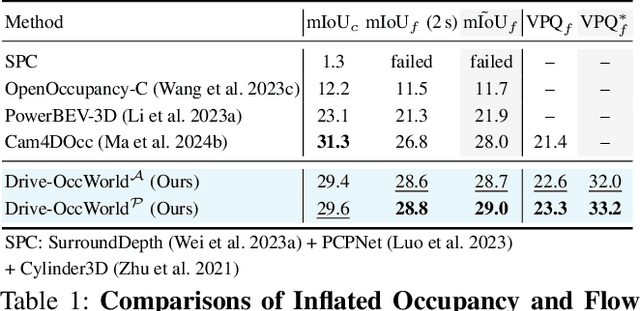
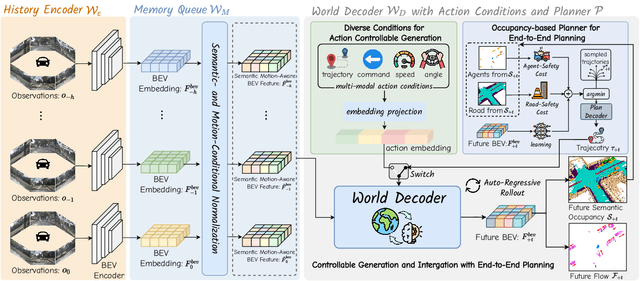
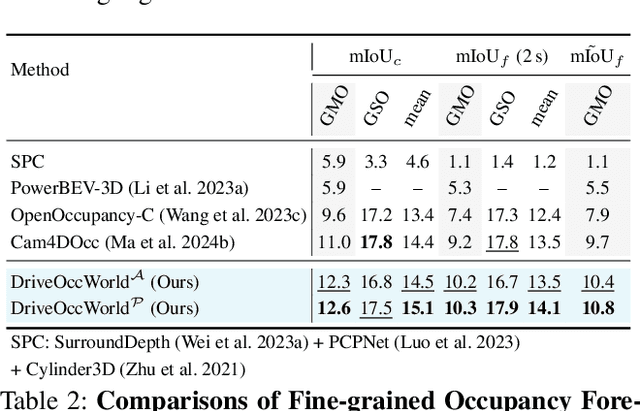
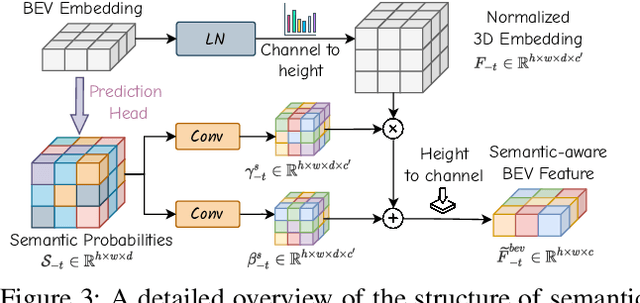
World models envision potential future states based on various ego actions. They embed extensive knowledge about the driving environment, facilitating safe and scalable autonomous driving. Most existing methods primarily focus on either data generation or the pretraining paradigms of world models. Unlike the aforementioned prior works, we propose Drive-OccWorld, which adapts a vision-centric 4D forecasting world model to end-to-end planning for autonomous driving. Specifically, we first introduce a semantic and motion-conditional normalization in the memory module, which accumulates semantic and dynamic information from historical BEV embeddings. These BEV features are then conveyed to the world decoder for future occupancy and flow forecasting, considering both geometry and spatiotemporal modeling. Additionally, we propose injecting flexible action conditions, such as velocity, steering angle, trajectory, and commands, into the world model to enable controllable generation and facilitate a broader range of downstream applications. Furthermore, we explore integrating the generative capabilities of the 4D world model with end-to-end planning, enabling continuous forecasting of future states and the selection of optimal trajectories using an occupancy-based cost function. Extensive experiments on the nuScenes dataset demonstrate that our method can generate plausible and controllable 4D occupancy, opening new avenues for driving world generation and end-to-end planning.