 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNEWTON: Agentic Planning for Physically Grounded Video Generation
May 19, 2026Video generation models produce visually compelling results but systematically violate physical commonsense -- on VideoPhy-2, the best model achieves only 32.6% joint accuracy. We identify a specification bottleneck: text prompts are lossy compression of the physical world, omitting the parameters that fully determine dynamics, and no amount of model scaling can recover what was never specified. From this diagnosis we derive three properties that physics conditioning must satisfy -- sufficiency, dynamism, and verifiability -- and show that no existing approach satisfies all three. We present NEWTON, in which video generation is demoted from the system output to one action inside an agent's toolbox: a learned planner orchestrates physics-aware tools (keyframe generation, scientific computation, prompt refinement) to construct rich conditioning, and a verifier closes the loop for iterative re-planning. The planner is the sole trainable component, optimized on-policy via Flow-GRPO inside the live multi-turn loop. On VideoPhy-2, NEWTON improves joint accuracy from 21.4% to 29.7% on LTX-Video and from 30.7% to 37.4% on Veo-3.1, without modifying either generator. Our project page: https://Newton026.github.io/newton
Think Before You Move: Latent Motion Reasoning for Text-to-Motion Generation
Dec 30, 2025Current state-of-the-art paradigms predominantly treat Text-to-Motion (T2M) generation as a direct translation problem, mapping symbolic language directly to continuous poses. While effective for simple actions, this System 1 approach faces a fundamental theoretical bottleneck we identify as the Semantic-Kinematic Impedance Mismatch: the inherent difficulty of grounding semantically dense, discrete linguistic intent into kinematically dense, high-frequency motion data in a single shot. In this paper, we argue that the solution lies in an architectural shift towards Latent System 2 Reasoning. Drawing inspiration from Hierarchical Motor Control in cognitive science, we propose Latent Motion Reasoning (LMR) that reformulates generation as a two-stage Think-then-Act decision process. Central to LMR is a novel Dual-Granularity Tokenizer that disentangles motion into two distinct manifolds: a compressed, semantically rich Reasoning Latent for planning global topology, and a high-frequency Execution Latent for preserving physical fidelity. By forcing the model to autoregressively reason (plan the coarse trajectory) before it moves (instantiates the frames), we effectively bridge the ineffability gap between language and physics. We demonstrate LMR's versatility by implementing it for two representative baselines: T2M-GPT (discrete) and MotionStreamer (continuous). Extensive experiments show that LMR yields non-trivial improvements in both semantic alignment and physical plausibility, validating that the optimal substrate for motion planning is not natural language, but a learned, motion-aligned concept space. Codes and demos can be found in \hyperlink{https://chenhaoqcdyq.github.io/LMR/}{https://chenhaoqcdyq.github.io/LMR/}
Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
Aug 26, 2024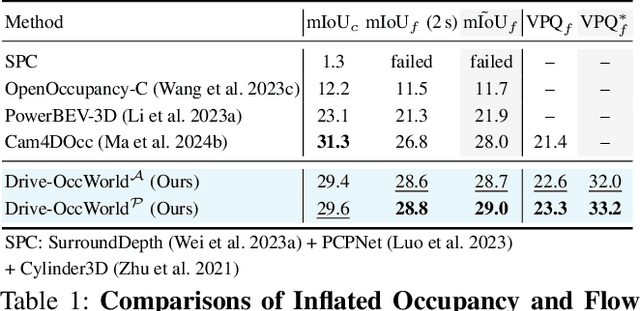
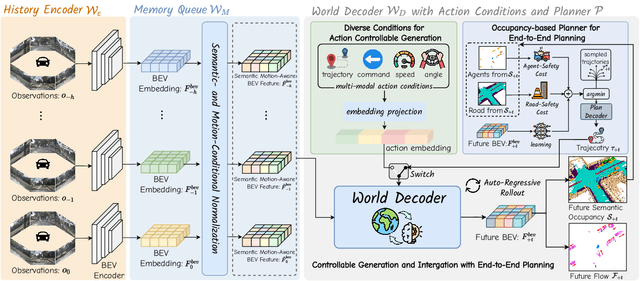
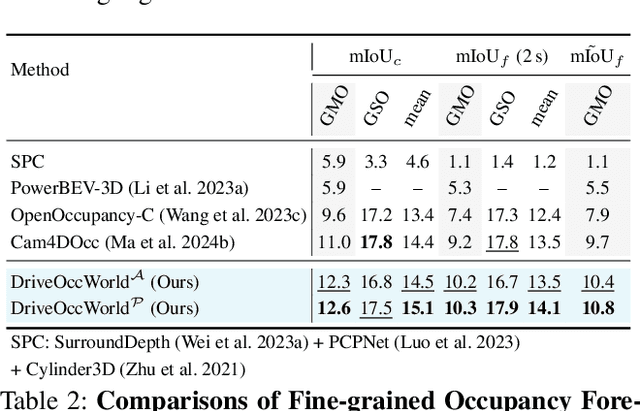
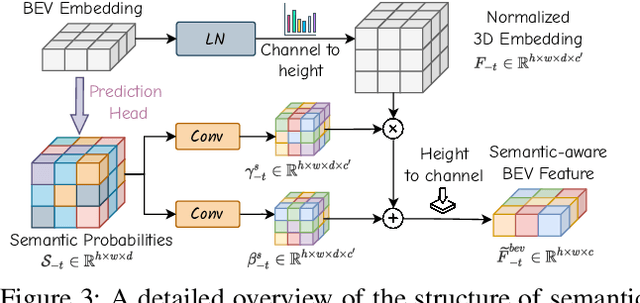
World models envision potential future states based on various ego actions. They embed extensive knowledge about the driving environment, facilitating safe and scalable autonomous driving. Most existing methods primarily focus on either data generation or the pretraining paradigms of world models. Unlike the aforementioned prior works, we propose Drive-OccWorld, which adapts a vision-centric 4D forecasting world model to end-to-end planning for autonomous driving. Specifically, we first introduce a semantic and motion-conditional normalization in the memory module, which accumulates semantic and dynamic information from historical BEV embeddings. These BEV features are then conveyed to the world decoder for future occupancy and flow forecasting, considering both geometry and spatiotemporal modeling. Additionally, we propose injecting flexible action conditions, such as velocity, steering angle, trajectory, and commands, into the world model to enable controllable generation and facilitate a broader range of downstream applications. Furthermore, we explore integrating the generative capabilities of the 4D world model with end-to-end planning, enabling continuous forecasting of future states and the selection of optimal trajectories using an occupancy-based cost function. Extensive experiments on the nuScenes dataset demonstrate that our method can generate plausible and controllable 4D occupancy, opening new avenues for driving world generation and end-to-end planning.
Open-Vocabulary SAM3D: Understand Any 3D Scene
May 24, 2024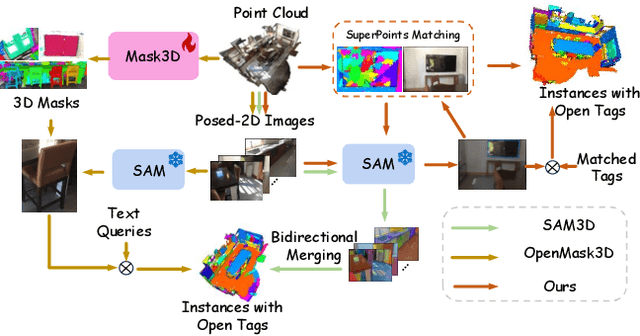
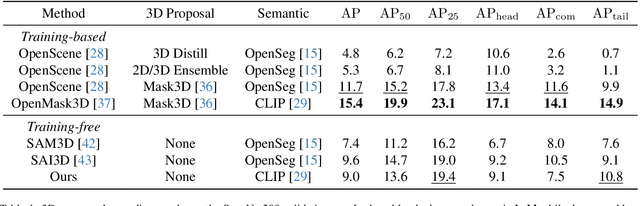
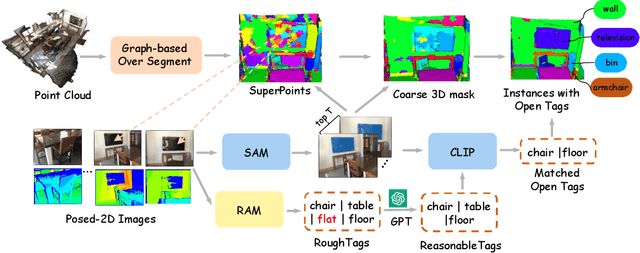

Open-vocabulary 3D scene understanding presents a significant challenge in the field. Recent advancements have sought to transfer knowledge embedded in vision language models from the 2D domain to 3D domain. However, these approaches often require learning prior knowledge from specific 3D scene datasets, which limits their applicability in open-world scenarios. The Segment Anything Model (SAM) has demonstrated remarkable zero-shot segmentation capabilities, prompting us to investigate its potential for comprehending 3D scenes without the need for training. In this paper, we introduce OV-SAM3D, a universal framework for open-vocabulary 3D scene understanding. This framework is designed to perform understanding tasks for any 3D scene without requiring prior knowledge of the scene. Specifically, our method is composed of two key sub-modules: First, we initiate the process by generating superpoints as the initial 3D prompts and refine these prompts using segment masks derived from SAM. Moreover, we then integrate a specially designed overlapping score table with open tags from the Recognize Anything Model (RAM) to produce final 3D instances with open-world label. Empirical evaluations conducted on the ScanNet200 and nuScenes datasets demonstrate that our approach surpasses existing open-vocabulary methods in unknown open-world environments.
TryOn-Adapter: Efficient Fine-Grained Clothing Identity Adaptation for High-Fidelity Virtual Try-On
Apr 01, 2024



Virtual try-on focuses on adjusting the given clothes to fit a specific person seamlessly while avoiding any distortion of the patterns and textures of the garment. However, the clothing identity uncontrollability and training inefficiency of existing diffusion-based methods, which struggle to maintain the identity even with full parameter training, are significant limitations that hinder the widespread applications. In this work, we propose an effective and efficient framework, termed TryOn-Adapter. Specifically, we first decouple clothing identity into fine-grained factors: style for color and category information, texture for high-frequency details, and structure for smooth spatial adaptive transformation. Our approach utilizes a pre-trained exemplar-based diffusion model as the fundamental network, whose parameters are frozen except for the attention layers. We then customize three lightweight modules (Style Preserving, Texture Highlighting, and Structure Adapting) incorporated with fine-tuning techniques to enable precise and efficient identity control. Meanwhile, we introduce the training-free T-RePaint strategy to further enhance clothing identity preservation while maintaining the realistic try-on effect during the inference. Our experiments demonstrate that our approach achieves state-of-the-art performance on two widely-used benchmarks. Additionally, compared with recent full-tuning diffusion-based methods, we only use about half of their tunable parameters during training. The code will be made publicly available at https://github.com/jiazheng-xing/TryOn-Adapter.
SDSTrack: Self-Distillation Symmetric Adapter Learning for Multi-Modal Visual Object Tracking
Mar 28, 2024


Multimodal Visual Object Tracking (VOT) has recently gained significant attention due to its robustness. Early research focused on fully fine-tuning RGB-based trackers, which was inefficient and lacked generalized representation due to the scarcity of multimodal data. Therefore, recent studies have utilized prompt tuning to transfer pre-trained RGB-based trackers to multimodal data. However, the modality gap limits pre-trained knowledge recall, and the dominance of the RGB modality persists, preventing the full utilization of information from other modalities. To address these issues, we propose a novel symmetric multimodal tracking framework called SDSTrack. We introduce lightweight adaptation for efficient fine-tuning, which directly transfers the feature extraction ability from RGB to other domains with a small number of trainable parameters and integrates multimodal features in a balanced, symmetric manner. Furthermore, we design a complementary masked patch distillation strategy to enhance the robustness of trackers in complex environments, such as extreme weather, poor imaging, and sensor failure. Extensive experiments demonstrate that SDSTrack outperforms state-of-the-art methods in various multimodal tracking scenarios, including RGB+Depth, RGB+Thermal, and RGB+Event tracking, and exhibits impressive results in extreme conditions. Our source code is available at https://github.com/hoqolo/SDSTrack.