 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Seeing to Experiencing: Scaling Navigation Foundation Models with Reinforcement Learning
Jul 29, 2025Navigation foundation models trained on massive webscale data enable agents to generalize across diverse environments and embodiments. However, these models trained solely on offline data, often lack the capacity to reason about the consequences of their actions or adapt through counterfactual understanding. They thus face significant limitations in the real-world urban navigation where interactive and safe behaviors, such as avoiding obstacles and moving pedestrians, are critical. To tackle these challenges, we introduce the Seeing-to-Experiencing framework to scale the capability of navigation foundation models with reinforcement learning. S2E combines the strengths of pre-training on videos and post-training through RL. It maintains the generalizability acquired from large-scale real-world videos while enhancing its interactivity through RL in simulation environments. Specifically, we introduce two innovations: an Anchor-Guided Distribution Matching strategy, which stabilizes learning and models diverse motion patterns through anchor-based supervision; and a Residual-Attention Module, which obtains reactive behaviors from simulation environments without erasing the model's pretrained knowledge. Moreover, we establish a comprehensive end-to-end evaluation benchmark, NavBench-GS, built on photorealistic 3DGS reconstructions of real-world scenes that incorporate physical interactions. It can systematically assess the generalizability and safety of navigation foundation models. Extensive experiments show that S2E mitigates the diminishing returns often seen when scaling with offline data alone. We perform a thorough analysis of the benefits of Reinforcement Learning compared to Supervised Fine-Tuning in the context of post-training for robot learning. Our findings emphasize the crucial role of integrating interactive online experiences to effectively scale foundation models in Robotics.
X-Scene: Large-Scale Driving Scene Generation with High Fidelity and Flexible Controllability
Jun 16, 2025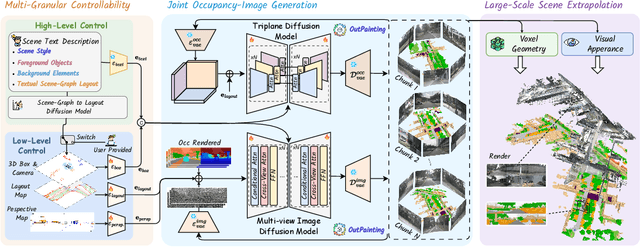

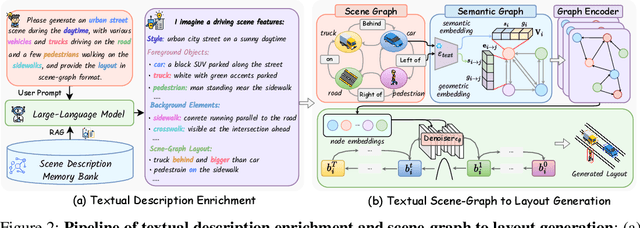
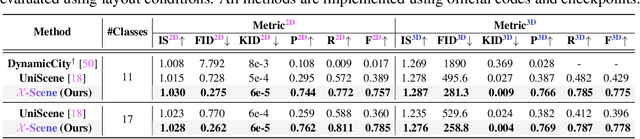
Diffusion models are advancing autonomous driving by enabling realistic data synthesis, predictive end-to-end planning, and closed-loop simulation, with a primary focus on temporally consistent generation. However, the generation of large-scale 3D scenes that require spatial coherence remains underexplored. In this paper, we propose X-Scene, a novel framework for large-scale driving scene generation that achieves both geometric intricacy and appearance fidelity, while offering flexible controllability. Specifically, X-Scene supports multi-granular control, including low-level conditions such as user-provided or text-driven layout for detailed scene composition and high-level semantic guidance such as user-intent and LLM-enriched text prompts for efficient customization. To enhance geometrical and visual fidelity, we introduce a unified pipeline that sequentially generates 3D semantic occupancy and the corresponding multiview images, while ensuring alignment between modalities. Additionally, we extend the generated local region into a large-scale scene through consistency-aware scene outpainting, which extrapolates new occupancy and images conditioned on the previously generated area, enhancing spatial continuity and preserving visual coherence. The resulting scenes are lifted into high-quality 3DGS representations, supporting diverse applications such as scene exploration. Comprehensive experiments demonstrate that X-Scene significantly advances controllability and fidelity for large-scale driving scene generation, empowering data generation and simulation for autonomous driving.
L2COcc: Lightweight Camera-Centric Semantic Scene Completion via Distillation of LiDAR Model
Mar 16, 2025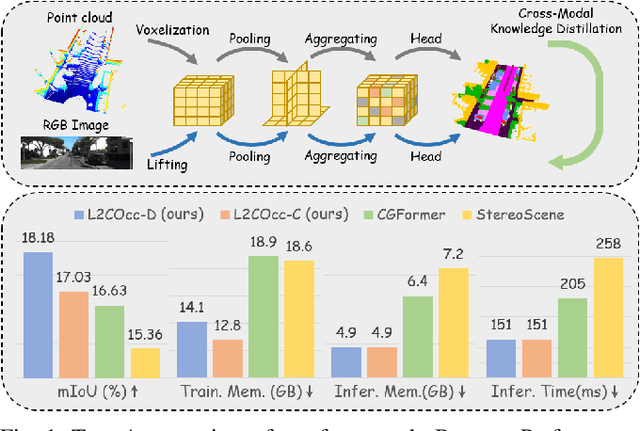
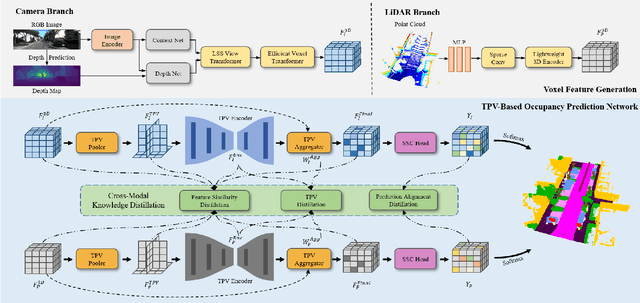
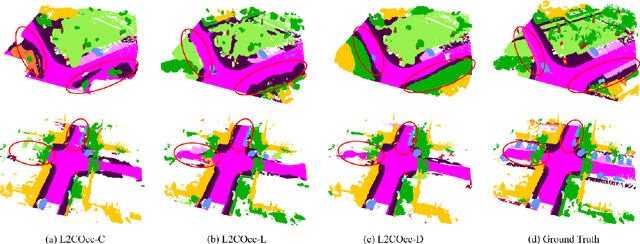
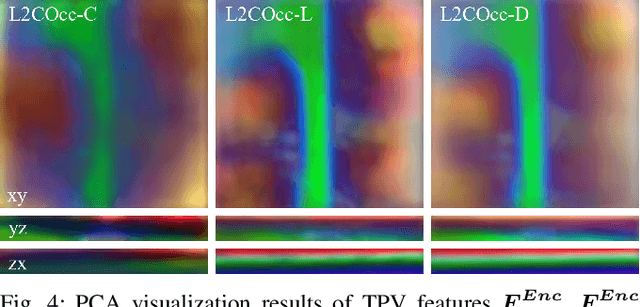
Semantic Scene Completion (SSC) constitutes a pivotal element in autonomous driving perception systems, tasked with inferring the 3D semantic occupancy of a scene from sensory data. To improve accuracy, prior research has implemented various computationally demanding and memory-intensive 3D operations, imposing significant computational requirements on the platform during training and testing. This paper proposes L2COcc, a lightweight camera-centric SSC framework that also accommodates LiDAR inputs. With our proposed efficient voxel transformer (EVT) and cross-modal knowledge modules, including feature similarity distillation (FSD), TPV distillation (TPVD) and prediction alignment distillation (PAD), our method substantially reduce computational burden while maintaining high accuracy. The experimental evaluations demonstrate that our proposed method surpasses the current state-of-the-art vision-based SSC methods regarding accuracy on both the SemanticKITTI and SSCBench-KITTI-360 benchmarks, respectively. Additionally, our method is more lightweight, exhibiting a reduction in both memory consumption and inference time by over 23% compared to the current state-of-the-arts method. Code is available at our project page:https://studyingfufu.github.io/L2COcc/.
LeapVAD: A Leap in Autonomous Driving via Cognitive Perception and Dual-Process Thinking
Jan 14, 2025While autonomous driving technology has made remarkable strides, data-driven approaches still struggle with complex scenarios due to their limited reasoning capabilities. Meanwhile, knowledge-driven autonomous driving systems have evolved considerably with the popularization of visual language models. In this paper, we propose LeapVAD, a novel method based on cognitive perception and dual-process thinking. Our approach implements a human-attentional mechanism to identify and focus on critical traffic elements that influence driving decisions. By characterizing these objects through comprehensive attributes - including appearance, motion patterns, and associated risks - LeapVAD achieves more effective environmental representation and streamlines the decision-making process. Furthermore, LeapVAD incorporates an innovative dual-process decision-making module miming the human-driving learning process. The system consists of an Analytic Process (System-II) that accumulates driving experience through logical reasoning and a Heuristic Process (System-I) that refines this knowledge via fine-tuning and few-shot learning. LeapVAD also includes reflective mechanisms and a growing memory bank, enabling it to learn from past mistakes and continuously improve its performance in a closed-loop environment. To enhance efficiency, we develop a scene encoder network that generates compact scene representations for rapid retrieval of relevant driving experiences. Extensive evaluations conducted on two leading autonomous driving simulators, CARLA and DriveArena, demonstrate that LeapVAD achieves superior performance compared to camera-only approaches despite limited training data. Comprehensive ablation studies further emphasize its effectiveness in continuous learning and domain adaptation. Project page: https://pjlab-adg.github.io/LeapVAD/.
Monocular Event-Inertial Odometry with Adaptive decay-based Time Surface and Polarity-aware Tracking
Sep 21, 2024Event cameras have garnered considerable attention due to their advantages over traditional cameras in low power consumption, high dynamic range, and no motion blur. This paper proposes a monocular event-inertial odometry incorporating an adaptive decay kernel-based time surface with polarity-aware tracking. We utilize an adaptive decay-based Time Surface to extract texture information from asynchronous events, which adapts to the dynamic characteristics of the event stream and enhances the representation of environmental textures. However, polarity-weighted time surfaces suffer from event polarity shifts during changes in motion direction. To mitigate its adverse effects on feature tracking, we optimize the feature tracking by incorporating an additional polarity-inverted time surface to enhance the robustness. Comparative analysis with visual-inertial and event-inertial odometry methods shows that our approach outperforms state-of-the-art techniques, with competitive results across various datasets.
DreamForge: Motion-Aware Autoregressive Video Generation for Multi-View Driving Scenes
Sep 06, 2024



Recent advances in diffusion models have significantly enhanced the cotrollable generation of streetscapes for and facilitated downstream perception and planning tasks. However, challenges such as maintaining temporal coherence, generating long videos, and accurately modeling driving scenes persist. Accordingly, we propose DreamForge, an advanced diffusion-based autoregressive video generation model designed for the long-term generation of 3D-controllable and extensible video. In terms of controllability, our DreamForge supports flexible conditions such as text descriptions, camera poses, 3D bounding boxes, and road layouts, while also providing perspective guidance to produce driving scenes that are both geometrically and contextually accurate. For consistency, we ensure inter-view consistency through cross-view attention and temporal coherence via an autoregressive architecture enhanced with motion cues. Codes will be available at https://github.com/PJLab-ADG/DriveArena.
Driving in the Occupancy World: Vision-Centric 4D Occupancy Forecasting and Planning via World Models for Autonomous Driving
Aug 26, 2024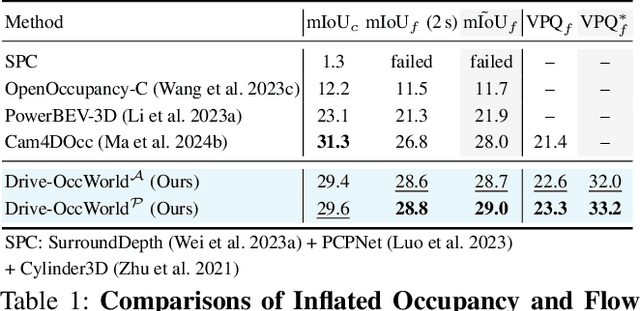
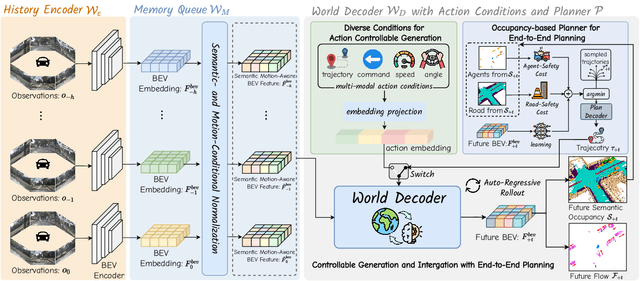
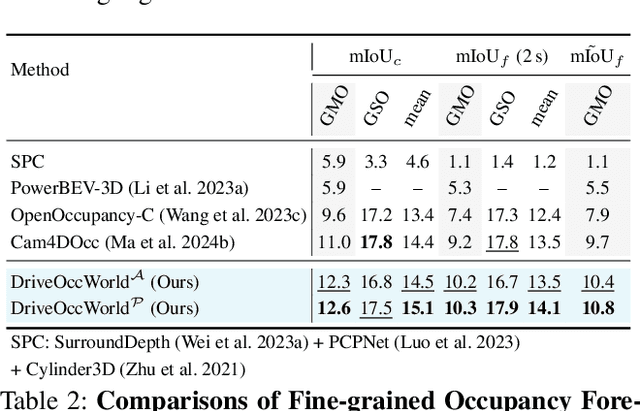
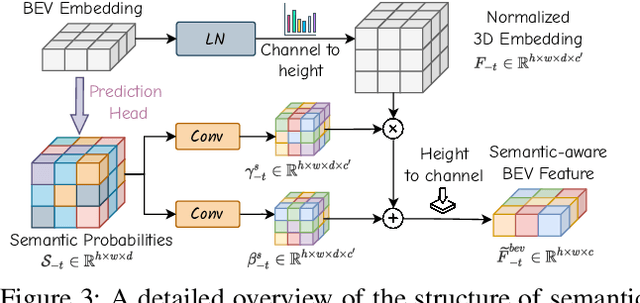
World models envision potential future states based on various ego actions. They embed extensive knowledge about the driving environment, facilitating safe and scalable autonomous driving. Most existing methods primarily focus on either data generation or the pretraining paradigms of world models. Unlike the aforementioned prior works, we propose Drive-OccWorld, which adapts a vision-centric 4D forecasting world model to end-to-end planning for autonomous driving. Specifically, we first introduce a semantic and motion-conditional normalization in the memory module, which accumulates semantic and dynamic information from historical BEV embeddings. These BEV features are then conveyed to the world decoder for future occupancy and flow forecasting, considering both geometry and spatiotemporal modeling. Additionally, we propose injecting flexible action conditions, such as velocity, steering angle, trajectory, and commands, into the world model to enable controllable generation and facilitate a broader range of downstream applications. Furthermore, we explore integrating the generative capabilities of the 4D world model with end-to-end planning, enabling continuous forecasting of future states and the selection of optimal trajectories using an occupancy-based cost function. Extensive experiments on the nuScenes dataset demonstrate that our method can generate plausible and controllable 4D occupancy, opening new avenues for driving world generation and end-to-end planning.
DriveArena: A Closed-loop Generative Simulation Platform for Autonomous Driving
Aug 01, 2024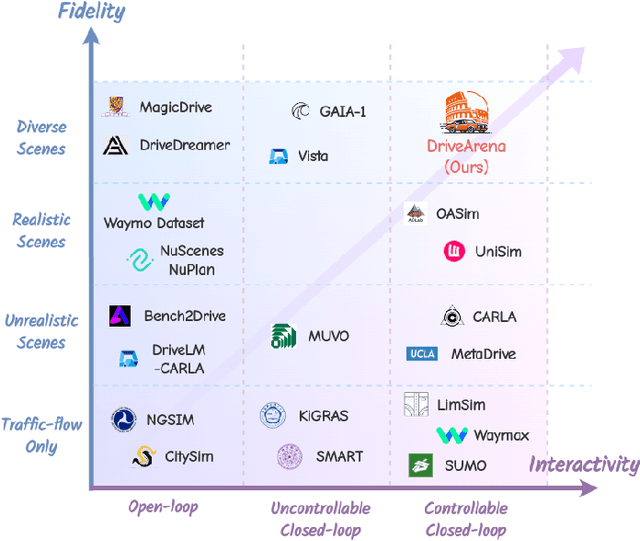

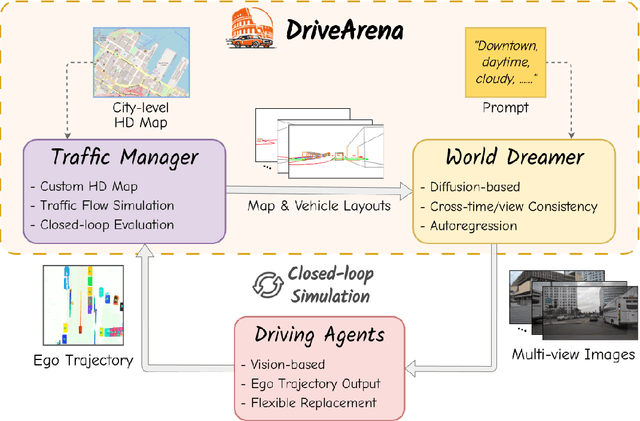

This paper presented DriveArena, the first high-fidelity closed-loop simulation system designed for driving agents navigating in real scenarios. DriveArena features a flexible, modular architecture, allowing for the seamless interchange of its core components: Traffic Manager, a traffic simulator capable of generating realistic traffic flow on any worldwide street map, and World Dreamer, a high-fidelity conditional generative model with infinite autoregression. This powerful synergy empowers any driving agent capable of processing real-world images to navigate in DriveArena's simulated environment. The agent perceives its surroundings through images generated by World Dreamer and output trajectories. These trajectories are fed into Traffic Manager, achieving realistic interactions with other vehicles and producing a new scene layout. Finally, the latest scene layout is relayed back into World Dreamer, perpetuating the simulation cycle. This iterative process fosters closed-loop exploration within a highly realistic environment, providing a valuable platform for developing and evaluating driving agents across diverse and challenging scenarios. DriveArena signifies a substantial leap forward in leveraging generative image data for the driving simulation platform, opening insights for closed-loop autonomous driving. Code will be available soon on GitHub: https://github.com/PJLab-ADG/DriveArena
LiCROcc: Teach Radar for Accurate Semantic Occupancy Prediction using LiDAR and Camera
Jul 23, 2024



Semantic Scene Completion (SSC) is pivotal in autonomous driving perception, frequently confronted with the complexities of weather and illumination changes. The long-term strategy involves fusing multi-modal information to bolster the system's robustness. Radar, increasingly utilized for 3D target detection, is gradually replacing LiDAR in autonomous driving applications, offering a robust sensing alternative. In this paper, we focus on the potential of 3D radar in semantic scene completion, pioneering cross-modal refinement techniques for improved robustness against weather and illumination changes, and enhancing SSC performance.Regarding model architecture, we propose a three-stage tight fusion approach on BEV to realize a fusion framework for point clouds and images. Based on this foundation, we designed three cross-modal distillation modules-CMRD, BRD, and PDD. Our approach enhances the performance in both radar-only (R-LiCROcc) and radar-camera (RC-LiCROcc) settings by distilling to them the rich semantic and structural information of the fused features of LiDAR and camera. Finally, our LC-Fusion (teacher model), R-LiCROcc and RC-LiCROcc achieve the best performance on the nuScenes-Occupancy dataset, with mIOU exceeding the baseline by 22.9%, 44.1%, and 15.5%, respectively. The project page is available at https://hr-zju.github.io/LiCROcc/.
Continuously Learning, Adapting, and Improving: A Dual-Process Approach to Autonomous Driving
May 24, 2024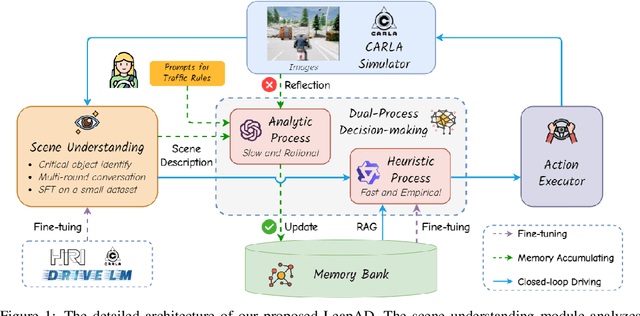
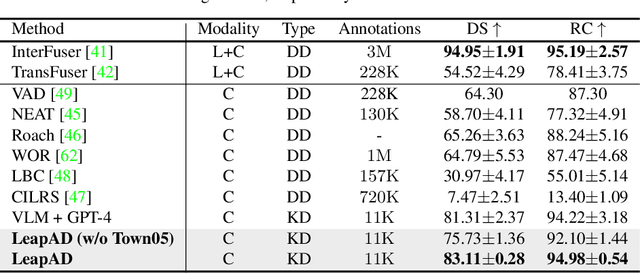
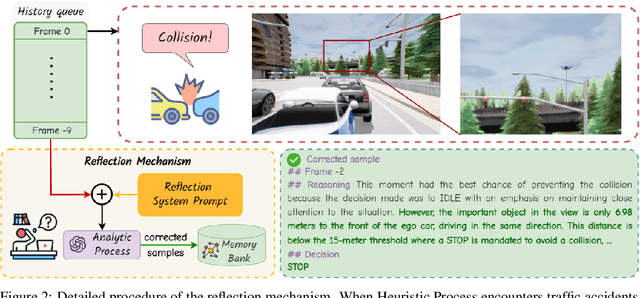
Autonomous driving has advanced significantly due to sensors, machine learning, and artificial intelligence improvements. However, prevailing methods struggle with intricate scenarios and causal relationships, hindering adaptability and interpretability in varied environments. To address the above problems, we introduce LeapAD, a novel paradigm for autonomous driving inspired by the human cognitive process. Specifically, LeapAD emulates human attention by selecting critical objects relevant to driving decisions, simplifying environmental interpretation, and mitigating decision-making complexities. Additionally, LeapAD incorporates an innovative dual-process decision-making module, which consists of an Analytic Process (System-II) for thorough analysis and reasoning, along with a Heuristic Process (System-I) for swift and empirical processing. The Analytic Process leverages its logical reasoning to accumulate linguistic driving experience, which is then transferred to the Heuristic Process by supervised fine-tuning. Through reflection mechanisms and a growing memory bank, LeapAD continuously improves itself from past mistakes in a closed-loop environment. Closed-loop testing in CARLA shows that LeapAD outperforms all methods relying solely on camera input, requiring 1-2 orders of magnitude less labeled data. Experiments also demonstrate that as the memory bank expands, the Heuristic Process with only 1.8B parameters can inherit the knowledge from a GPT-4 powered Analytic Process and achieve continuous performance improvement. Code will be released at https://github.com/PJLab-ADG/LeapAD.