 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperLiDAR: Adaptive Post-Deployment LiDAR Segmentation via Hyperdimensional Computing
Apr 14, 2026LiDAR semantic segmentation plays a pivotal role in 3D scene understanding for edge applications such as autonomous driving. However, significant challenges remain for real-world deployments, particularly for on-device post-deployment adaptation. Real-world environments can shift as the system navigates through different locations, leading to substantial performance degradation without effective and timely model adaptation. Furthermore, edge systems operate under strict computational and energy constraints, making it infeasible to adapt conventional segmentation models (based on large neural networks) directly on-device. To address the above challenges, we introduce HyperLiDAR, the first lightweight, post-deployment LiDAR segmentation framework based on Hyperdimensional Computing (HDC). The design of HyperLiDAR fully leverages the fast learning and high efficiency of HDC, inspired by how the human brain processes information. To further improve the adaptation efficiency, we identify the high data volume per scan as a key bottleneck and introduce a buffer selection strategy that focuses learning on the most informative points. We conduct extensive evaluations on two state-of-the-art LiDAR segmentation benchmarks and two representative devices. Our results show that HyperLiDAR outperforms or achieves comparable adaptation performance to state-of-the-art segmentation methods, while achieving up to a 13.8x speedup in retraining.
O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
Foreground Focus: Enhancing Coherence and Fidelity in Camouflaged Image Generation
Apr 02, 2025Camouflaged image generation is emerging as a solution to data scarcity in camouflaged vision perception, offering a cost-effective alternative to data collection and labeling. Recently, the state-of-the-art approach successfully generates camouflaged images using only foreground objects. However, it faces two critical weaknesses: 1) the background knowledge does not integrate effectively with foreground features, resulting in a lack of foreground-background coherence (e.g., color discrepancy); 2) the generation process does not prioritize the fidelity of foreground objects, which leads to distortion, particularly for small objects. To address these issues, we propose a Foreground-Aware Camouflaged Image Generation (FACIG) model. Specifically, we introduce a Foreground-Aware Feature Integration Module (FAFIM) to strengthen the integration between foreground features and background knowledge. In addition, a Foreground-Aware Denoising Loss is designed to enhance foreground reconstruction supervision. Experiments on various datasets show our method outperforms previous methods in overall camouflaged image quality and foreground fidelity.
A Concise Survey on Lane Topology Reasoning for HD Mapping
Mar 31, 2025



Lane topology reasoning techniques play a crucial role in high-definition (HD) mapping and autonomous driving applications. While recent years have witnessed significant advances in this field, there has been limited effort to consolidate these works into a comprehensive overview. This survey systematically reviews the evolution and current state of lane topology reasoning methods, categorizing them into three major paradigms: procedural modeling-based methods, aerial imagery-based methods, and onboard sensors-based methods. We analyze the progression from early rule-based approaches to modern learning-based solutions utilizing transformers, graph neural networks (GNNs), and other deep learning architectures. The paper examines standardized evaluation metrics, including road-level measures (APLS and TLTS score), and lane-level metrics (DET and TOP score), along with performance comparisons on benchmark datasets such as OpenLane-V2. We identify key technical challenges, including dataset availability and model efficiency, and outline promising directions for future research. This comprehensive review provides researchers and practitioners with insights into the theoretical frameworks, practical implementations, and emerging trends in lane topology reasoning for HD mapping applications.
L2COcc: Lightweight Camera-Centric Semantic Scene Completion via Distillation of LiDAR Model
Mar 16, 2025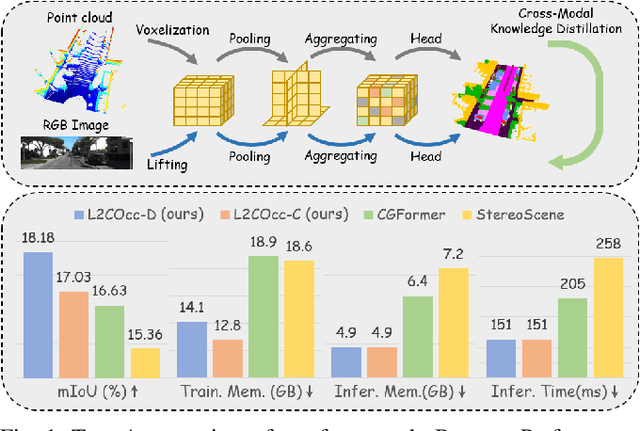
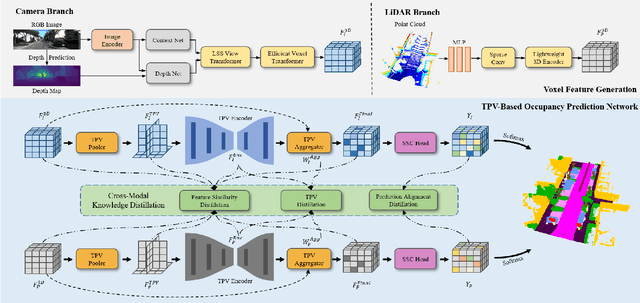
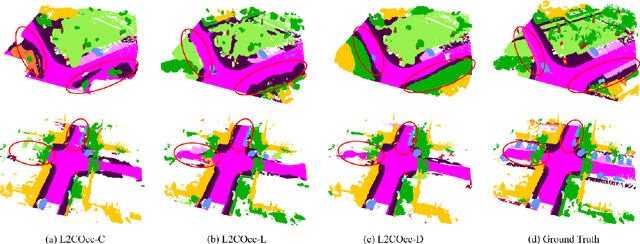
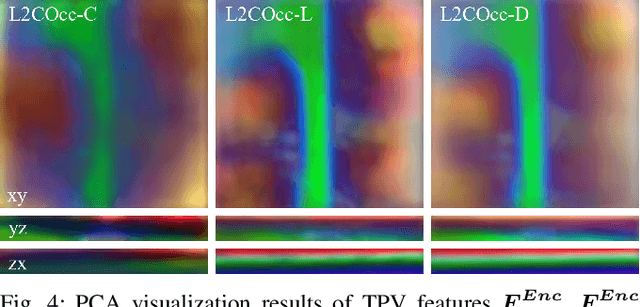
Semantic Scene Completion (SSC) constitutes a pivotal element in autonomous driving perception systems, tasked with inferring the 3D semantic occupancy of a scene from sensory data. To improve accuracy, prior research has implemented various computationally demanding and memory-intensive 3D operations, imposing significant computational requirements on the platform during training and testing. This paper proposes L2COcc, a lightweight camera-centric SSC framework that also accommodates LiDAR inputs. With our proposed efficient voxel transformer (EVT) and cross-modal knowledge modules, including feature similarity distillation (FSD), TPV distillation (TPVD) and prediction alignment distillation (PAD), our method substantially reduce computational burden while maintaining high accuracy. The experimental evaluations demonstrate that our proposed method surpasses the current state-of-the-art vision-based SSC methods regarding accuracy on both the SemanticKITTI and SSCBench-KITTI-360 benchmarks, respectively. Additionally, our method is more lightweight, exhibiting a reduction in both memory consumption and inference time by over 23% compared to the current state-of-the-arts method. Code is available at our project page:https://studyingfufu.github.io/L2COcc/.
RecipeGen: A Benchmark for Real-World Recipe Image Generation
Mar 07, 2025



Recipe image generation is an important challenge in food computing, with applications from culinary education to interactive recipe platforms. However, there is currently no real-world dataset that comprehensively connects recipe goals, sequential steps, and corresponding images. To address this, we introduce RecipeGen, the first real-world goal-step-image benchmark for recipe generation, featuring diverse ingredients, varied recipe steps, multiple cooking styles, and a broad collection of food categories. Data is in https://github.com/zhangdaxia22/RecipeGen.
PedDet: Adaptive Spectral Optimization for Multimodal Pedestrian Detection
Feb 21, 2025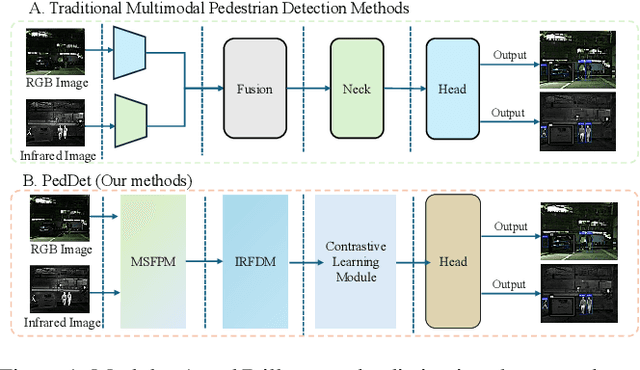
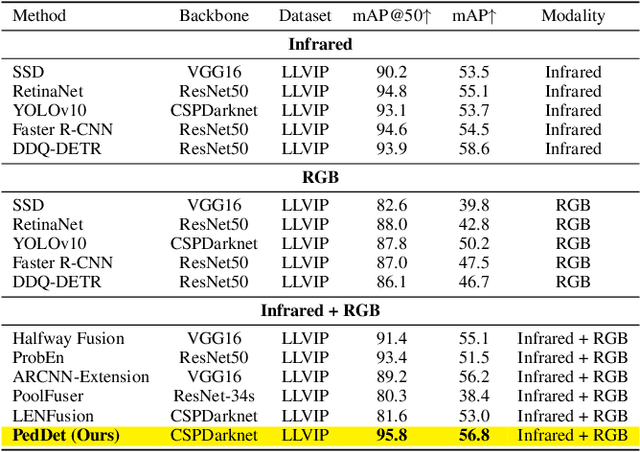
Pedestrian detection in intelligent transportation systems has made significant progress but faces two critical challenges: (1) insufficient fusion of complementary information between visible and infrared spectra, particularly in complex scenarios, and (2) sensitivity to illumination changes, such as low-light or overexposed conditions, leading to degraded performance. To address these issues, we propose PedDet, an adaptive spectral optimization complementarity framework specifically enhanced and optimized for multispectral pedestrian detection. PedDet introduces the Multi-scale Spectral Feature Perception Module (MSFPM) to adaptively fuse visible and infrared features, enhancing robustness and flexibility in feature extraction. Additionally, the Illumination Robustness Feature Decoupling Module (IRFDM) improves detection stability under varying lighting by decoupling pedestrian and background features. We further design a contrastive alignment to enhance intermodal feature discrimination. Experiments on LLVIP and MSDS datasets demonstrate that PedDet achieves state-of-the-art performance, improving the mAP by 6.6% with superior detection accuracy even in low-light conditions, marking a significant step forward for road safety. Code will be available at https://github.com/AIGeeksGroup/PedDet.
Feature-based One-For-All: A Universal Framework for Heterogeneous Knowledge Distillation
Jan 15, 2025Knowledge distillation (KD) involves transferring knowledge from a pre-trained heavy teacher model to a lighter student model, thereby reducing the inference cost while maintaining comparable effectiveness. Prior KD techniques typically assume homogeneity between the teacher and student models. However, as technology advances, a wide variety of architectures have emerged, ranging from initial Convolutional Neural Networks (CNNs) to Vision Transformers (ViTs), and Multi-Level Perceptrons (MLPs). Consequently, developing a universal KD framework compatible with any architecture has become an important research topic. In this paper, we introduce a feature-based one-for-all (FOFA) KD framework to enable feature distillation across diverse architecture. Our framework comprises two key components. First, we design prompt tuning blocks that incorporate student feedback, allowing teacher features to adapt to the student model's learning process. Second, we propose region-aware attention to mitigate the view mismatch problem between heterogeneous architecture. By leveraging these two modules, effective distillation of intermediate features can be achieved across heterogeneous architectures. Extensive experiments on CIFAR, ImageNet, and COCO demonstrate the superiority of the proposed method.
Neural HD Map Generation from Multiple Vectorized Tiles Locally Produced by Autonomous Vehicles
Sep 05, 2024High-definition (HD) map is a fundamental component of autonomous driving systems, as it can provide precise environmental information about driving scenes. Recent work on vectorized map generation could produce merely 65% local map elements around the ego-vehicle at runtime by one tour with onboard sensors, leaving a puzzle of how to construct a global HD map projected in the world coordinate system under high-quality standards. To address the issue, we present GNMap as an end-to-end generative neural network to automatically construct HD maps with multiple vectorized tiles which are locally produced by autonomous vehicles through several tours. It leverages a multi-layer and attention-based autoencoder as the shared network, of which parameters are learned from two different tasks (i.e., pretraining and finetuning, respectively) to ensure both the completeness of generated maps and the correctness of element categories. Abundant qualitative evaluations are conducted on a real-world dataset and experimental results show that GNMap can surpass the SOTA method by more than 5% F1 score, reaching the level of industrial usage with a small amount of manual modification. We have already deployed it at Navinfo Co., Ltd., serving as an indispensable software to automatically build HD maps for autonomous driving systems.
The Fabrication of Reality and Fantasy: Scene Generation with LLM-Assisted Prompt Interpretation
Jul 17, 2024



In spite of recent advancements in text-to-image generation, limitations persist in handling complex and imaginative prompts due to the restricted diversity and complexity of training data. This work explores how diffusion models can generate images from prompts requiring artistic creativity or specialized knowledge. We introduce the Realistic-Fantasy Benchmark (RFBench), a novel evaluation framework blending realistic and fantastical scenarios. To address these challenges, we propose the Realistic-Fantasy Network (RFNet), a training-free approach integrating diffusion models with LLMs. Extensive human evaluations and GPT-based compositional assessments demonstrate our approach's superiority over state-of-the-art methods. Our code and dataset is available at https://leo81005.github.io/Reality-and-Fantasy/.