 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATMapTR: Satellite Image Enhanced Online HD Map Construction
Dec 12, 2025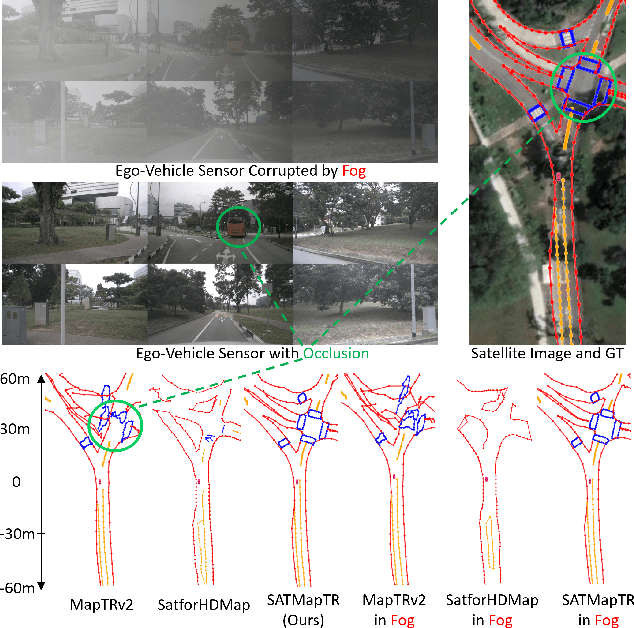
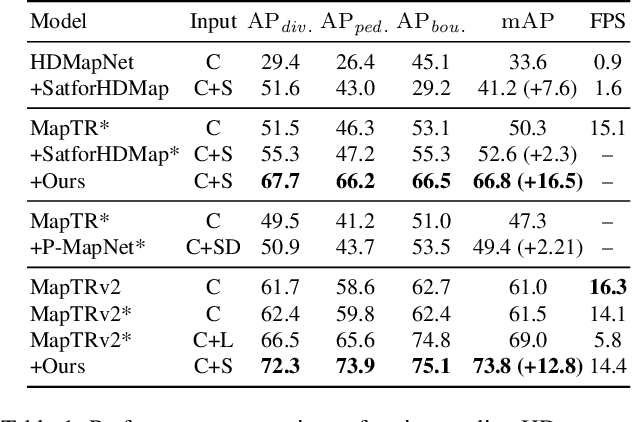
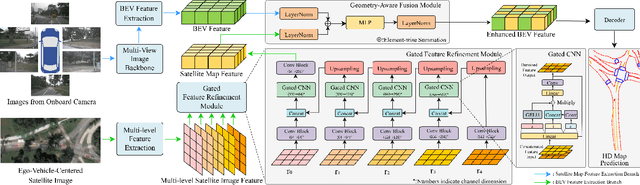
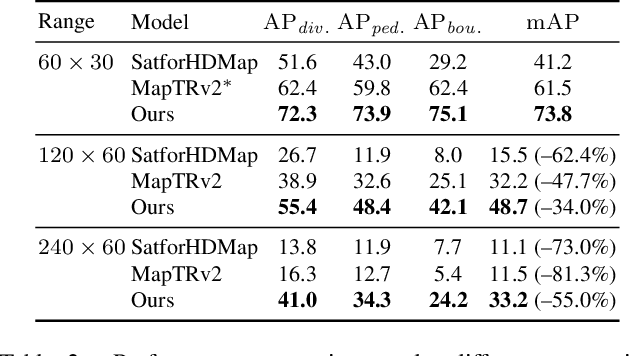
High-definition (HD) maps are evolving from pre-annotated to real-time construction to better support autonomous driving in diverse scenarios. However, this process is hindered by low-quality input data caused by onboard sensors limited capability and frequent occlusions, leading to incomplete, noisy, or missing data, and thus reduced mapping accuracy and robustness. Recent efforts have introduced satellite images as auxiliary input, offering a stable, wide-area view to complement the limited ego perspective. However, satellite images in Bird's Eye View are often degraded by shadows and occlusions from vegetation and buildings. Prior methods using basic feature extraction and fusion remain ineffective. To address these challenges, we propose SATMapTR, a novel online map construction model that effectively fuses satellite image through two key components: (1) a gated feature refinement module that adaptively filters satellite image features by integrating high-level semantics with low-level structural cues to extract high signal-to-noise ratio map-relevant representations; and (2) a geometry-aware fusion module that consistently fuse satellite and BEV features at a grid-to-grid level, minimizing interference from irrelevant regions and low-quality inputs. Experimental results on the nuScenes dataset show that SATMapTR achieves the highest mean average precision (mAP) of 73.8, outperforming state-of-the-art satellite-enhanced models by up to 14.2 mAP. It also shows lower mAP degradation under adverse weather and sensor failures, and achieves nearly 3 times higher mAP at extended perception ranges.
Global Regulation and Excitation via Attention Tuning for Stereo Matching
Sep 19, 2025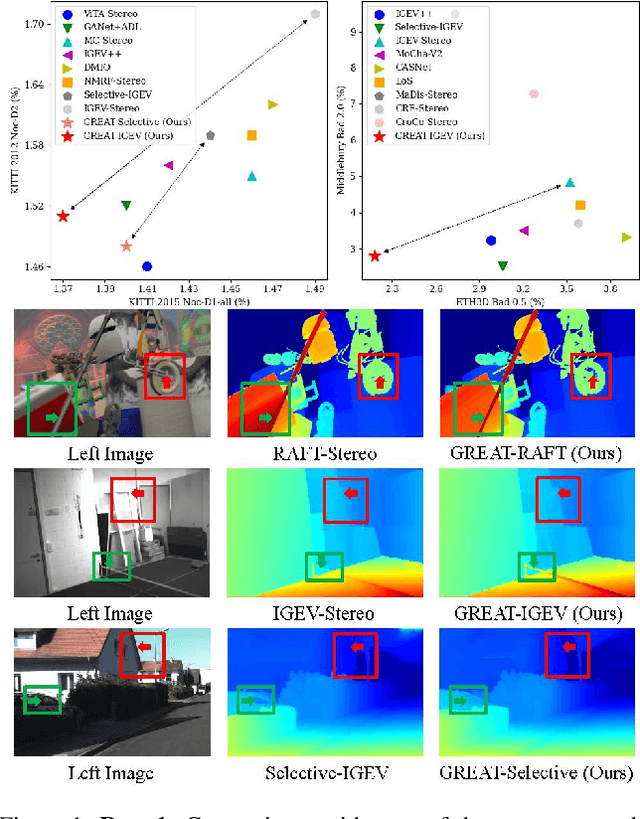
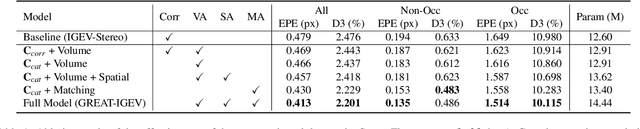
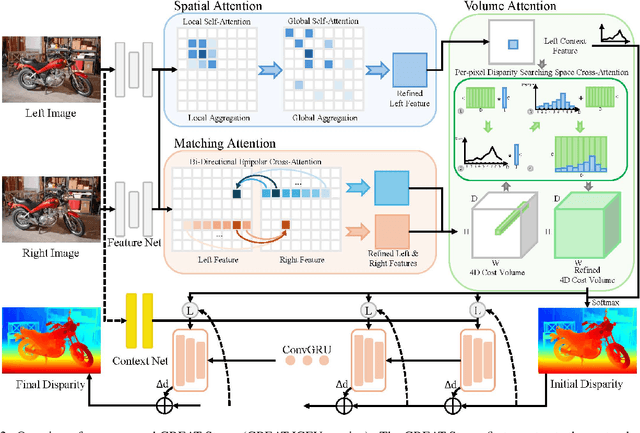
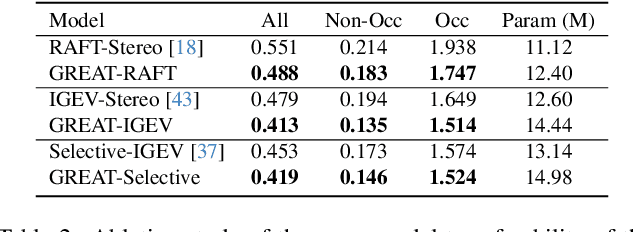
Stereo matching achieves significant progress with iterative algorithms like RAFT-Stereo and IGEV-Stereo. However, these methods struggle in ill-posed regions with occlusions, textureless, or repetitive patterns, due to a lack of global context and geometric information for effective iterative refinement. To enable the existing iterative approaches to incorporate global context, we propose the Global Regulation and Excitation via Attention Tuning (GREAT) framework which encompasses three attention modules. Specifically, Spatial Attention (SA) captures the global context within the spatial dimension, Matching Attention (MA) extracts global context along epipolar lines, and Volume Attention (VA) works in conjunction with SA and MA to construct a more robust cost-volume excited by global context and geometric details. To verify the universality and effectiveness of this framework, we integrate it into several representative iterative stereo-matching methods and validate it through extensive experiments, collectively denoted as GREAT-Stereo. This framework demonstrates superior performance in challenging ill-posed regions. Applied to IGEV-Stereo, among all published methods, our GREAT-IGEV ranks first on the Scene Flow test set, KITTI 2015, and ETH3D leaderboards, and achieves second on the Middlebury benchmark. Code is available at https://github.com/JarvisLee0423/GREAT-Stereo.
VLM-C4L: Continual Core Dataset Learning with Corner Case Optimization via Vision-Language Models for Autonomous Driving
Mar 29, 2025With the widespread adoption and deployment of autonomous driving, handling complex environments has become an unavoidable challenge. Due to the scarcity and diversity of extreme scenario datasets, current autonomous driving models struggle to effectively manage corner cases. This limitation poses a significant safety risk, according to the National Highway Traffic Safety Administration (NHTSA), autonomous vehicle systems have been involved in hundreds of reported crashes annually in the United States, occurred in corner cases like sun glare and fog, which caused a few fatal accident. Furthermore, in order to consistently maintain a robust and reliable autonomous driving system, it is essential for models not only to perform well on routine scenarios but also to adapt to newly emerging scenarios, especially those corner cases that deviate from the norm. This requires a learning mechanism that incrementally integrates new knowledge without degrading previously acquired capabilities. However, to the best of our knowledge, no existing continual learning methods have been proposed to ensure consistent and scalable corner case learning in autonomous driving. To address these limitations, we propose VLM-C4L, a continual learning framework that introduces Vision-Language Models (VLMs) to dynamically optimize and enhance corner case datasets, and VLM-C4L combines VLM-guided high-quality data extraction with a core data replay strategy, enabling the model to incrementally learn from diverse corner cases while preserving performance on previously routine scenarios, thus ensuring long-term stability and adaptability in real-world autonomous driving. We evaluate VLM-C4L on large-scale real-world autonomous driving datasets, including Waymo and the corner case dataset CODA.
Leveraging Diffusion Knowledge for Generative Image Compression with Fractal Frequency-Aware Band Learning
Mar 14, 2025By optimizing the rate-distortion-realism trade-off, generative image compression approaches produce detailed, realistic images instead of the only sharp-looking reconstructions produced by rate-distortion-optimized models. In this paper, we propose a novel deep learning-based generative image compression method injected with diffusion knowledge, obtaining the capacity to recover more realistic textures in practical scenarios. Efforts are made from three perspectives to navigate the rate-distortion-realism trade-off in the generative image compression task. First, recognizing the strong connection between image texture and frequency-domain characteristics, we design a Fractal Frequency-Aware Band Image Compression (FFAB-IC) network to effectively capture the directional frequency components inherent in natural images. This network integrates commonly used fractal band feature operations within a neural non-linear mapping design, enhancing its ability to retain essential given information and filter out unnecessary details. Then, to improve the visual quality of image reconstruction under limited bandwidth, we integrate diffusion knowledge into the encoder and implement diffusion iterations into the decoder process, thus effectively recovering lost texture details. Finally, to fully leverage the spatial and frequency intensity information, we incorporate frequency- and content-aware regularization terms to regularize the training of the generative image compression network. Extensive experiments in quantitative and qualitative evaluations demonstrate the superiority of the proposed method, advancing the boundaries of achievable distortion-realism pairs, i.e., our method achieves better distortions at high realism and better realism at low distortion than ever before.
RecipeGen: A Benchmark for Real-World Recipe Image Generation
Mar 07, 2025



Recipe image generation is an important challenge in food computing, with applications from culinary education to interactive recipe platforms. However, there is currently no real-world dataset that comprehensively connects recipe goals, sequential steps, and corresponding images. To address this, we introduce RecipeGen, the first real-world goal-step-image benchmark for recipe generation, featuring diverse ingredients, varied recipe steps, multiple cooking styles, and a broad collection of food categories. Data is in https://github.com/zhangdaxia22/RecipeGen.
ModeSeq: Taming Sparse Multimodal Motion Prediction with Sequential Mode Modeling
Nov 17, 2024



Anticipating the multimodality of future events lays the foundation for safe autonomous driving. However, multimodal motion prediction for traffic agents has been clouded by the lack of multimodal ground truth. Existing works predominantly adopt the winner-take-all training strategy to tackle this challenge, yet still suffer from limited trajectory diversity and misaligned mode confidence. While some approaches address these limitations by generating excessive trajectory candidates, they necessitate a post-processing stage to identify the most representative modes, a process lacking universal principles and compromising trajectory accuracy. We are thus motivated to introduce ModeSeq, a new multimodal prediction paradigm that models modes as sequences. Unlike the common practice of decoding multiple plausible trajectories in one shot, ModeSeq requires motion decoders to infer the next mode step by step, thereby more explicitly capturing the correlation between modes and significantly enhancing the ability to reason about multimodality. Leveraging the inductive bias of sequential mode prediction, we also propose the Early-Match-Take-All (EMTA) training strategy to diversify the trajectories further. Without relying on dense mode prediction or rule-based trajectory selection, ModeSeq considerably improves the diversity of multimodal output while attaining satisfactory trajectory accuracy, resulting in balanced performance on motion prediction benchmarks. Moreover, ModeSeq naturally emerges with the capability of mode extrapolation, which supports forecasting more behavior modes when the future is highly uncertain.
PAVLM: Advancing Point Cloud based Affordance Understanding Via Vision-Language Model
Oct 15, 2024



Affordance understanding, the task of identifying actionable regions on 3D objects, plays a vital role in allowing robotic systems to engage with and operate within the physical world. Although Visual Language Models (VLMs) have excelled in high-level reasoning and long-horizon planning for robotic manipulation, they still fall short in grasping the nuanced physical properties required for effective human-robot interaction. In this paper, we introduce PAVLM (Point cloud Affordance Vision-Language Model), an innovative framework that utilizes the extensive multimodal knowledge embedded in pre-trained language models to enhance 3D affordance understanding of point cloud. PAVLM integrates a geometric-guided propagation module with hidden embeddings from large language models (LLMs) to enrich visual semantics. On the language side, we prompt Llama-3.1 models to generate refined context-aware text, augmenting the instructional input with deeper semantic cues. Experimental results on the 3D-AffordanceNet benchmark demonstrate that PAVLM outperforms baseline methods for both full and partial point clouds, particularly excelling in its generalization to novel open-world affordance tasks of 3D objects. For more information, visit our project site: pavlm-source.github.io.
Traffic Scene Generation from Natural Language Description for Autonomous Vehicles with Large Language Model
Sep 15, 2024Text-to-scene generation, transforming textual descriptions into detailed scenes, typically relies on generating key scenarios along predetermined paths, constraining environmental diversity and limiting customization flexibility. To address these limitations, we propose a novel text-to-traffic scene framework that leverages a large language model to generate diverse traffic scenarios within the Carla simulator based on natural language descriptions. Users can define specific parameters such as weather conditions, vehicle types, and road signals, while our pipeline can autonomously select the starting point and scenario details, generating scenes from scratch without relying on predetermined locations or trajectories. Furthermore, our framework supports both critical and routine traffic scenarios, enhancing its applicability. Experimental results indicate that our approach promotes diverse agent planning and road selection, enhancing the training of autonomous agents in traffic environments. Notably, our methodology has achieved a 16% reduction in average collision rates. Our work is made publicly available at https://basiclab.github.io/TTSG.
BehaviorGPT: Smart Agent Simulation for Autonomous Driving with Next-Patch Prediction
May 27, 2024



Simulating realistic interactions among traffic agents is crucial for efficiently validating the safety of autonomous driving systems. Existing leading simulators primarily use an encoder-decoder structure to encode the historical trajectories for future simulation. However, such a paradigm complicates the model architecture, and the manual separation of history and future trajectories leads to low data utilization. To address these challenges, we propose Behavior Generative Pre-trained Transformers (BehaviorGPT), a decoder-only, autoregressive architecture designed to simulate the sequential motion of multiple agents. Crucially, our approach discards the traditional separation between "history" and "future," treating each time step as the "current" one, resulting in a simpler, more parameter- and data-efficient design that scales seamlessly with data and computation. Additionally, we introduce the Next-Patch Prediction Paradigm (NP3), which enables models to reason at the patch level of trajectories and capture long-range spatial-temporal interactions. BehaviorGPT ranks first across several metrics on the Waymo Sim Agents Benchmark, demonstrating its exceptional performance in multi-agent and agent-map interactions. We outperformed state-of-the-art models with a realism score of 0.741 and improved the minADE metric to 1.540, with an approximately 91.6% reduction in model parameters.
Lightweight Deep Learning for Resource-Constrained Environments: A Survey
Apr 12, 2024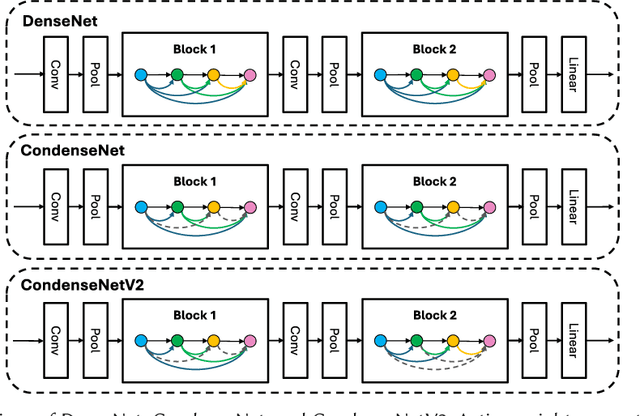

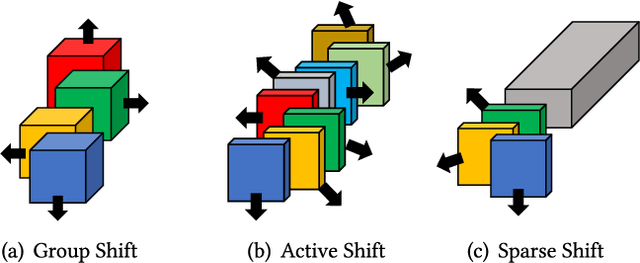

Over the past decade, the dominance of deep learning has prevailed across various domains of artificial intelligence, including natural language processing, computer vision, and biomedical signal processing. While there have been remarkable improvements in model accuracy, deploying these models on lightweight devices, such as mobile phones and microcontrollers, is constrained by limited resources. In this survey, we provide comprehensive design guidance tailored for these devices, detailing the meticulous design of lightweight models, compression methods, and hardware acceleration strategies. The principal goal of this work is to explore methods and concepts for getting around hardware constraints without compromising the model's accuracy. Additionally, we explore two notable paths for lightweight deep learning in the future: deployment techniques for TinyML and Large Language Models. Although these paths undoubtedly have potential, they also present significant challenges, encouraging research into unexplored areas.