 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePAVLM: Advancing Point Cloud based Affordance Understanding Via Vision-Language Model
Oct 15, 2024



Affordance understanding, the task of identifying actionable regions on 3D objects, plays a vital role in allowing robotic systems to engage with and operate within the physical world. Although Visual Language Models (VLMs) have excelled in high-level reasoning and long-horizon planning for robotic manipulation, they still fall short in grasping the nuanced physical properties required for effective human-robot interaction. In this paper, we introduce PAVLM (Point cloud Affordance Vision-Language Model), an innovative framework that utilizes the extensive multimodal knowledge embedded in pre-trained language models to enhance 3D affordance understanding of point cloud. PAVLM integrates a geometric-guided propagation module with hidden embeddings from large language models (LLMs) to enrich visual semantics. On the language side, we prompt Llama-3.1 models to generate refined context-aware text, augmenting the instructional input with deeper semantic cues. Experimental results on the 3D-AffordanceNet benchmark demonstrate that PAVLM outperforms baseline methods for both full and partial point clouds, particularly excelling in its generalization to novel open-world affordance tasks of 3D objects. For more information, visit our project site: pavlm-source.github.io.
JarviX: A LLM No code Platform for Tabular Data Analysis and Optimization
Dec 03, 2023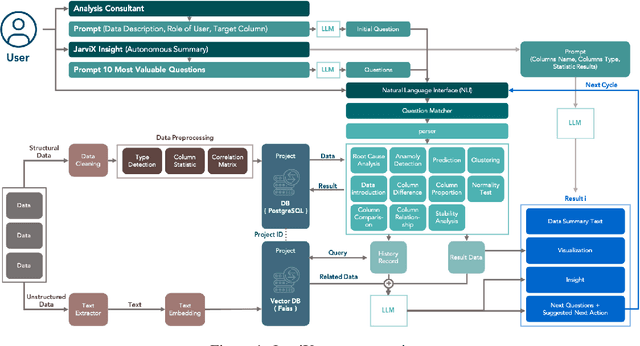
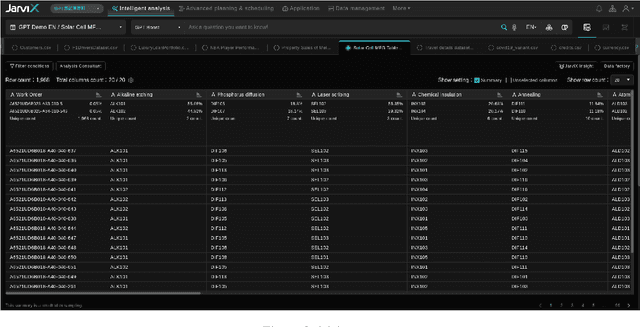
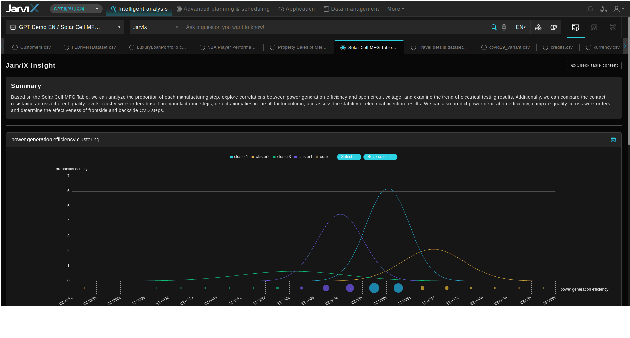
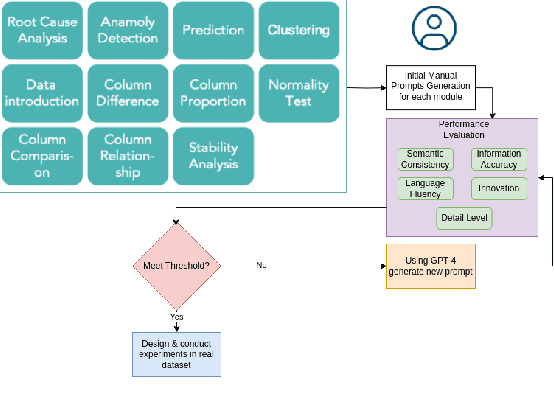
In this study, we introduce JarviX, a sophisticated data analytics framework. JarviX is designed to employ Large Language Models (LLMs) to facilitate an automated guide and execute high-precision data analyzes on tabular datasets. This framework emphasizes the significance of varying column types, capitalizing on state-of-the-art LLMs to generate concise data insight summaries, propose relevant analysis inquiries, visualize data effectively, and provide comprehensive explanations for results drawn from an extensive data analysis pipeline. Moreover, JarviX incorporates an automated machine learning (AutoML) pipeline for predictive modeling. This integration forms a comprehensive and automated optimization cycle, which proves particularly advantageous for optimizing machine configuration. The efficacy and adaptability of JarviX are substantiated through a series of practical use case studies.
Trixi the Librarian
Oct 20, 2022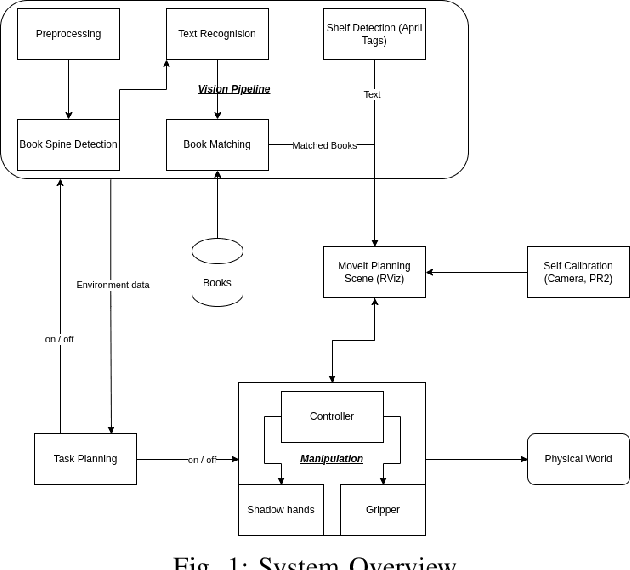
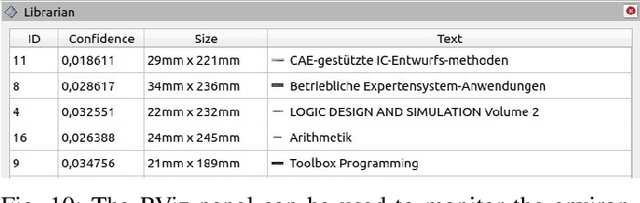


In this work, we present a three-part system that automatically sorts books on a shelf using the PR- 2 platform. The paper describes a methodology to sufficiently detect and recognize books using a multistep vision pipeline based on deep learning models as well as conventional computer vision. Furthermore, the difficulties of relocating books using a bi-manual robot along with solutions based on MoveIt and BioIK are being addressed. Experiments show that the performance is overall good enough to repeatedly sort three books on a shelf. Nevertheless, further improvements are being discussed, potentially leading to a more robust book recognition and more versatile manipulation techniques.