 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAesCrop: Aesthetic-driven Cropping Guided by Composition
Oct 26, 2025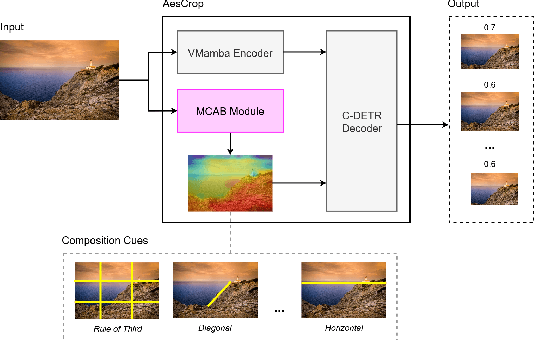
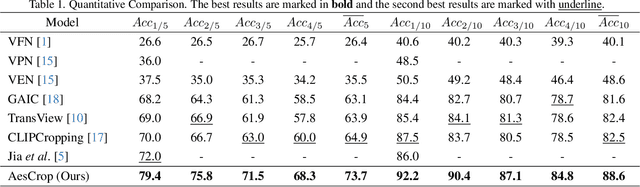
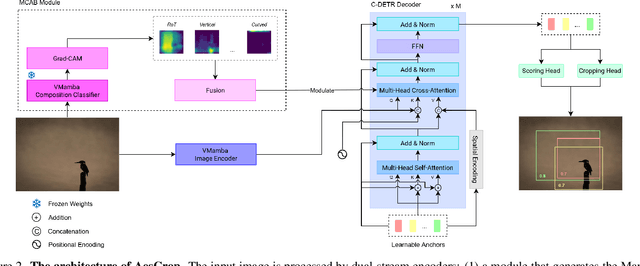
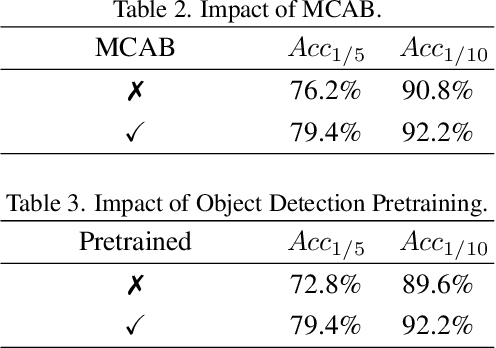
Aesthetic-driven image cropping is crucial for applications like view recommendation and thumbnail generation, where visual appeal significantly impacts user engagement. A key factor in visual appeal is composition--the deliberate arrangement of elements within an image. Some methods have successfully incorporated compositional knowledge through evaluation-based and regression-based paradigms. However, evaluation-based methods lack globality while regression-based methods lack diversity. Recently, hybrid approaches that integrate both paradigms have emerged, bridging the gap between these two to achieve better diversity and globality. Notably, existing hybrid methods do not incorporate photographic composition guidance, a key attribute that defines photographic aesthetics. In this work, we introduce AesCrop, a composition-aware hybrid image-cropping model that integrates a VMamba image encoder, augmented with a novel Mamba Composition Attention Bias (MCAB) and a transformer decoder to perform end-to-end rank-based image cropping, generating multiple crops along with the corresponding quality scores. By explicitly encoding compositional cues into the attention mechanism, MCAB directs AesCrop to focus on the most compositionally salient regions. Extensive experiments demonstrate that AesCrop outperforms current state-of-the-art methods, delivering superior quantitative metrics and qualitatively more pleasing crops.
Lightweight Deep Learning for Resource-Constrained Environments: A Survey
Apr 12, 2024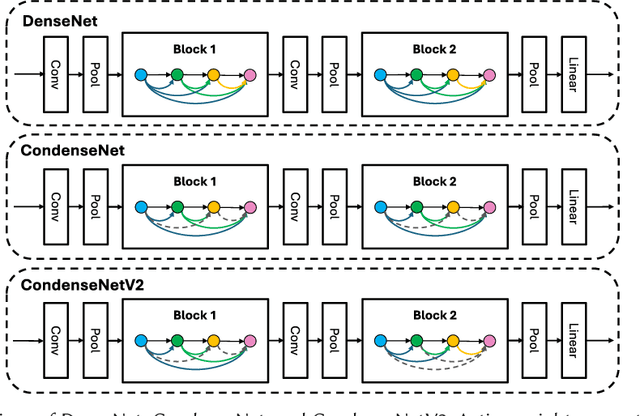

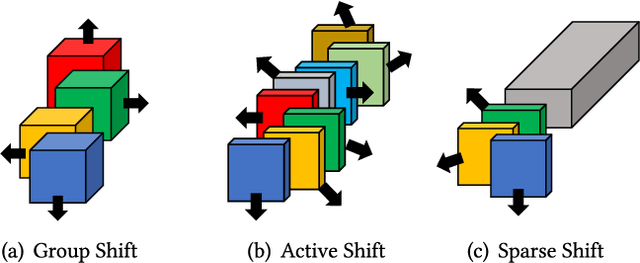

Over the past decade, the dominance of deep learning has prevailed across various domains of artificial intelligence, including natural language processing, computer vision, and biomedical signal processing. While there have been remarkable improvements in model accuracy, deploying these models on lightweight devices, such as mobile phones and microcontrollers, is constrained by limited resources. In this survey, we provide comprehensive design guidance tailored for these devices, detailing the meticulous design of lightweight models, compression methods, and hardware acceleration strategies. The principal goal of this work is to explore methods and concepts for getting around hardware constraints without compromising the model's accuracy. Additionally, we explore two notable paths for lightweight deep learning in the future: deployment techniques for TinyML and Large Language Models. Although these paths undoubtedly have potential, they also present significant challenges, encouraging research into unexplored areas.
Saliency-aware Stereoscopic Video Retargeting
Apr 18, 2023



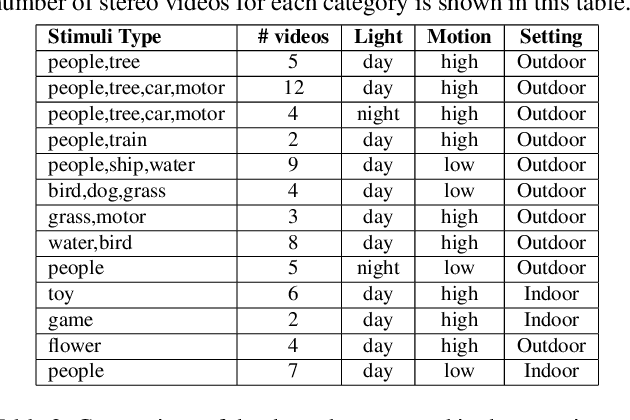
Stereo video retargeting aims to resize an image to a desired aspect ratio. The quality of retargeted videos can be significantly impacted by the stereo videos spatial, temporal, and disparity coherence, all of which can be impacted by the retargeting process. Due to the lack of a publicly accessible annotated dataset, there is little research on deep learning-based methods for stereo video retargeting. This paper proposes an unsupervised deep learning-based stereo video retargeting network. Our model first detects the salient objects and shifts and warps all objects such that it minimizes the distortion of the salient parts of the stereo frames. We use 1D convolution for shifting the salient objects and design a stereo video Transformer to assist the retargeting process. To train the network, we use the parallax attention mechanism to fuse the left and right views and feed the retargeted frames to a reconstruction module that reverses the retargeted frames to the input frames. Therefore, the network is trained in an unsupervised manner. Extensive qualitative and quantitative experiments and ablation studies on KITTI stereo 2012 and 2015 datasets demonstrate the efficiency of the proposed method over the existing state-of-the-art methods. The code is available at https://github.com/z65451/SVR/.
A New Dataset and Transformer for Stereoscopic Video Super-Resolution
Apr 21, 2022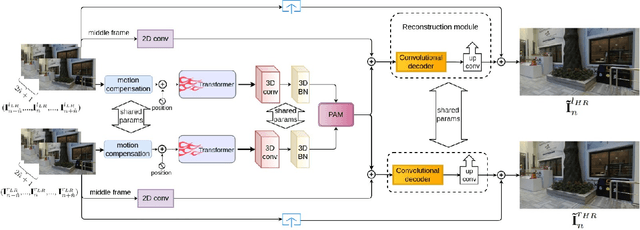

Stereo video super-resolution (SVSR) aims to enhance the spatial resolution of the low-resolution video by reconstructing the high-resolution video. The key challenges in SVSR are preserving the stereo-consistency and temporal-consistency, without which viewers may experience 3D fatigue. There are several notable works on stereoscopic image super-resolution, but there is little research on stereo video super-resolution. In this paper, we propose a novel Transformer-based model for SVSR, namely Trans-SVSR. Trans-SVSR comprises two key novel components: a spatio-temporal convolutional self-attention layer and an optical flow-based feed-forward layer that discovers the correlation across different video frames and aligns the features. The parallax attention mechanism (PAM) that uses the cross-view information to consider the significant disparities is used to fuse the stereo views. Due to the lack of a benchmark dataset suitable for the SVSR task, we collected a new stereoscopic video dataset, SVSR-Set, containing 71 full high-definition (HD) stereo videos captured using a professional stereo camera. Extensive experiments on the collected dataset, along with two other datasets, demonstrate that the Trans-SVSR can achieve competitive performance compared to the state-of-the-art methods. Project code and additional results are available at https://github.com/H-deep/Trans-SVSR/
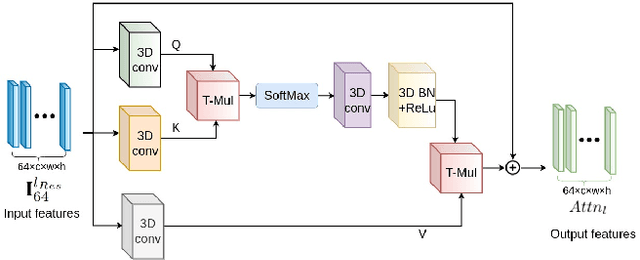
HiMODE: A Hybrid Monocular Omnidirectional Depth Estimation Model
Apr 11, 2022
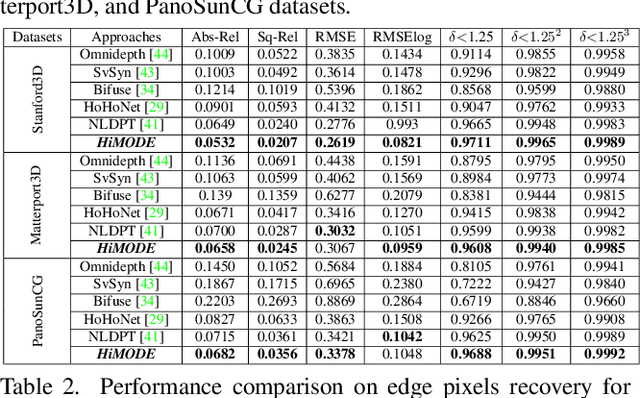
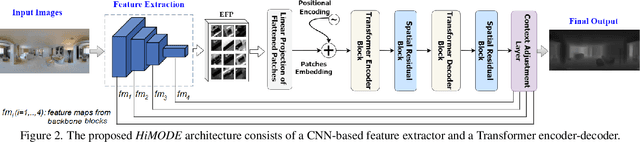
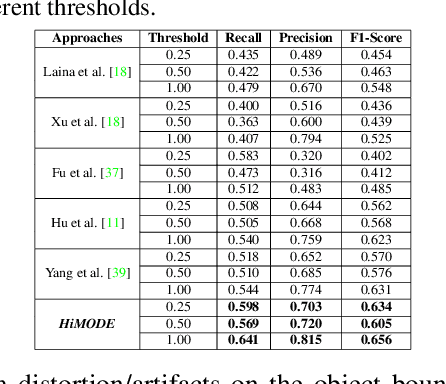
Monocular omnidirectional depth estimation is receiving considerable research attention due to its broad applications for sensing 360{\deg} surroundings. Existing approaches in this field suffer from limitations in recovering small object details and data lost during the ground-truth depth map acquisition. In this paper, a novel monocular omnidirectional depth estimation model, namely HiMODE is proposed based on a hybrid CNN+Transformer (encoder-decoder) architecture whose modules are efficiently designed to mitigate distortion and computational cost, without performance degradation. Firstly, we design a feature pyramid network based on the HNet block to extract high-resolution features near the edges. The performance is further improved, benefiting from a self and cross attention layer and spatial/temporal patches in the Transformer encoder and decoder, respectively. Besides, a spatial residual block is employed to reduce the number of parameters. By jointly passing the deep features extracted from an input image at each backbone block, along with the raw depth maps predicted by the transformer encoder-decoder, through a context adjustment layer, our model can produce resulting depth maps with better visual quality than the ground-truth. Comprehensive ablation studies demonstrate the significance of each individual module. Extensive experiments conducted on three datasets; Stanford3D, Matterport3D, and SunCG, demonstrate that HiMODE can achieve state-of-the-art performance for 360{\deg} monocular depth estimation.
Shallow Optical Flow Three-Stream CNN for Macro- and Micro-Expression Spotting from Long Videos
Jun 11, 2021
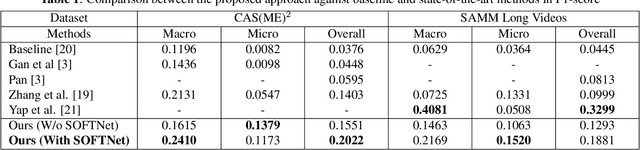
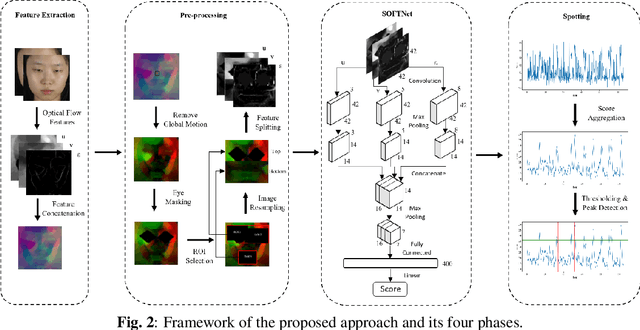
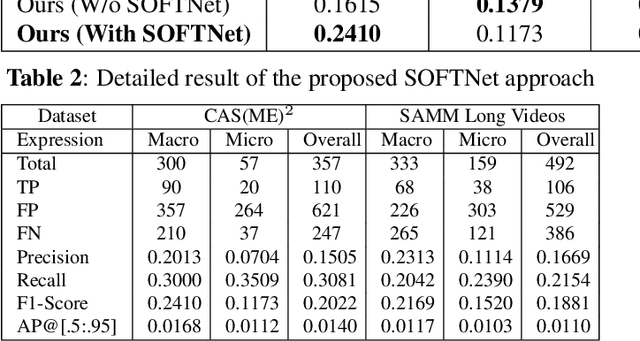
Facial expressions vary from the visible to the subtle. In recent years, the analysis of micro-expressions $-$ a natural occurrence resulting from the suppression of one's true emotions, has drawn the attention of researchers with a broad range of potential applications. However, spotting microexpressions in long videos becomes increasingly challenging when intertwined with normal or macro-expressions. In this paper, we propose a shallow optical flow three-stream CNN (SOFTNet) model to predict a score that captures the likelihood of a frame being in an expression interval. By fashioning the spotting task as a regression problem, we introduce pseudo-labeling to facilitate the learning process. We demonstrate the efficacy and efficiency of the proposed approach on the recent MEGC 2020 benchmark, where state-of-the-art performance is achieved on CAS(ME)$^{2}$ with equally promising results on SAMM Long Videos.