 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Depth Analysis of Automated Acne Disease Recognition and Classification
Mar 04, 2025



Facial acne is a common disease, especially among adolescents, negatively affecting both physically and psychologically. Classifying acne is vital to providing the appropriate treatment. Traditional visual inspection or expert scanning is time-consuming and difficult to differentiate acne types. This paper introduces an automated expert system for acne recognition and classification. The proposed method employs a machine learning-based technique to classify and evaluate six types of acne diseases to facilitate the diagnosis of dermatologists. The pre-processing phase includes contrast improvement, smoothing filter, and RGB to L*a*b color conversion to eliminate noise and improve the classification accuracy. Then, a clustering-based segmentation method, k-means clustering, is applied for segmenting the disease-affected regions that pass through the feature extraction step. Characteristics of these disease-affected regions are extracted based on a combination of gray-level co-occurrence matrix (GLCM) and Statistical features. Finally, five different machine learning classifiers are employed to classify acne diseases. Experimental results show that the Random Forest (RF) achieves the highest accuracy of 98.50%, which is promising compared to the state-of-the-art methods.
Denoising Diffusion Probabilistic Model for Retinal Image Generation and Segmentation
Aug 16, 2023



Experts use retinal images and vessel trees to detect and diagnose various eye, blood circulation, and brain-related diseases. However, manual segmentation of retinal images is a time-consuming process that requires high expertise and is difficult due to privacy issues. Many methods have been proposed to segment images, but the need for large retinal image datasets limits the performance of these methods. Several methods synthesize deep learning models based on Generative Adversarial Networks (GAN) to generate limited sample varieties. This paper proposes a novel Denoising Diffusion Probabilistic Model (DDPM) that outperformed GANs in image synthesis. We developed a Retinal Trees (ReTree) dataset consisting of retinal images, corresponding vessel trees, and a segmentation network based on DDPM trained with images from the ReTree dataset. In the first stage, we develop a two-stage DDPM that generates vessel trees from random numbers belonging to a standard normal distribution. Later, the model is guided to generate fundus images from given vessel trees and random distribution. The proposed dataset has been evaluated quantitatively and qualitatively. Quantitative evaluation metrics include Frechet Inception Distance (FID) score, Jaccard similarity coefficient, Cohen's kappa, Matthew's Correlation Coefficient (MCC), precision, recall, F1-score, and accuracy. We trained the vessel segmentation model with synthetic data to validate our dataset's efficiency and tested it on authentic data. Our developed dataset and source code is available at https://github.com/AAleka/retree.
Saliency-aware Stereoscopic Video Retargeting
Apr 18, 2023



Stereo video retargeting aims to resize an image to a desired aspect ratio. The quality of retargeted videos can be significantly impacted by the stereo videos spatial, temporal, and disparity coherence, all of which can be impacted by the retargeting process. Due to the lack of a publicly accessible annotated dataset, there is little research on deep learning-based methods for stereo video retargeting. This paper proposes an unsupervised deep learning-based stereo video retargeting network. Our model first detects the salient objects and shifts and warps all objects such that it minimizes the distortion of the salient parts of the stereo frames. We use 1D convolution for shifting the salient objects and design a stereo video Transformer to assist the retargeting process. To train the network, we use the parallax attention mechanism to fuse the left and right views and feed the retargeted frames to a reconstruction module that reverses the retargeted frames to the input frames. Therefore, the network is trained in an unsupervised manner. Extensive qualitative and quantitative experiments and ablation studies on KITTI stereo 2012 and 2015 datasets demonstrate the efficiency of the proposed method over the existing state-of-the-art methods. The code is available at https://github.com/z65451/SVR/.
Retinal Image Restoration using Transformer and Cycle-Consistent Generative Adversarial Network
Mar 03, 2023



Medical imaging plays a significant role in detecting and treating various diseases. However, these images often happen to be of too poor quality, leading to decreased efficiency, extra expenses, and even incorrect diagnoses. Therefore, we propose a retinal image enhancement method using a vision transformer and convolutional neural network. It builds a cycle-consistent generative adversarial network that relies on unpaired datasets. It consists of two generators that translate images from one domain to another (e.g., low- to high-quality and vice versa), playing an adversarial game with two discriminators. Generators produce indistinguishable images for discriminators that predict the original images from generated ones. Generators are a combination of vision transformer (ViT) encoder and convolutional neural network (CNN) decoder. Discriminators include traditional CNN encoders. The resulting improved images have been tested quantitatively using such evaluation metrics as peak signal-to-noise ratio (PSNR), structural similarity index measure (SSIM), and qualitatively, i.e., vessel segmentation. The proposed method successfully reduces the adverse effects of blurring, noise, illumination disturbances, and color distortions while significantly preserving structural and color information. Experimental results show the superiority of the proposed method. Our testing PSNR is 31.138 dB for the first and 27.798 dB for the second dataset. Testing SSIM is 0.919 and 0.904, respectively.
HiMFR: A Hybrid Masked Face Recognition Through Face Inpainting
Sep 19, 2022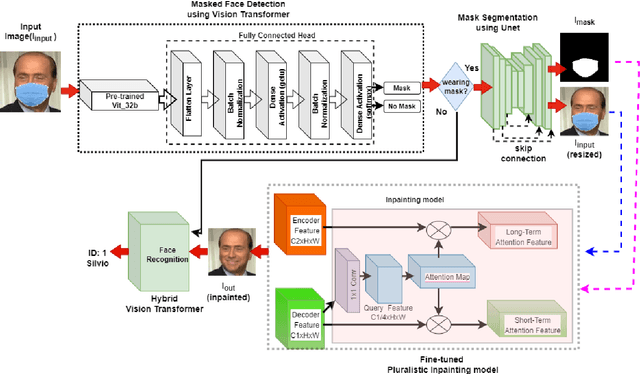
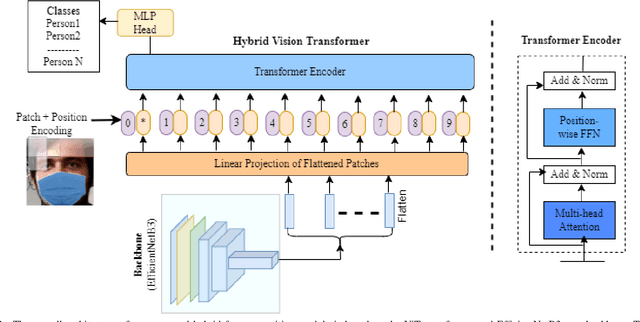


To recognize the masked face, one of the possible solutions could be to restore the occluded part of the face first and then apply the face recognition method. Inspired by the recent image inpainting methods, we propose an end-to-end hybrid masked face recognition system, namely HiMFR, consisting of three significant parts: masked face detector, face inpainting, and face recognition. The masked face detector module applies a pretrained Vision Transformer (ViT\_b32) to detect whether faces are covered with masked or not. The inpainting module uses a fine-tune image inpainting model based on a Generative Adversarial Network (GAN) to restore faces. Finally, the hybrid face recognition module based on ViT with an EfficientNetB3 backbone recognizes the faces. We have implemented and evaluated our proposed method on four different publicly available datasets: CelebA, SSDMNV2, MAFA, {Pubfig83} with our locally collected small dataset, namely Face5. Comprehensive experimental results show the efficacy of the proposed HiMFR method with competitive performance. Code is available at https://github.com/mdhosen/HiMFR
Masked Face Inpainting Through Residual Attention UNet
Sep 19, 2022
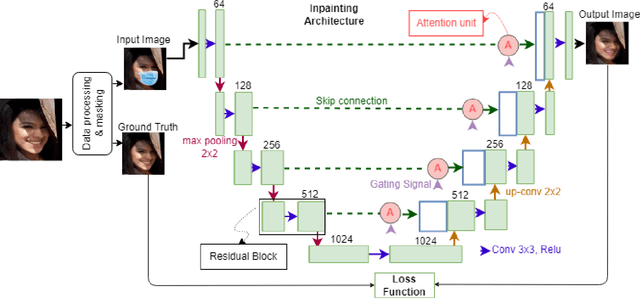
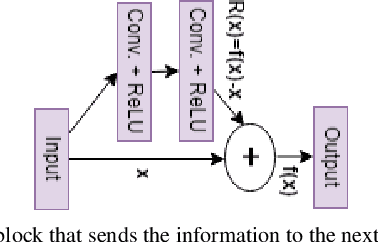
Realistic image restoration with high texture areas such as removing face masks is challenging. The state-of-the-art deep learning-based methods fail to guarantee high-fidelity, cause training instability due to vanishing gradient problems (e.g., weights are updated slightly in initial layers) and spatial information loss. They also depend on intermediary stage such as segmentation meaning require external mask. This paper proposes a blind mask face inpainting method using residual attention UNet to remove the face mask and restore the face with fine details while minimizing the gap with the ground truth face structure. A residual block feeds info to the next layer and directly into the layers about two hops away to solve the gradient vanishing problem. Besides, the attention unit helps the model focus on the relevant mask region, reducing resources and making the model faster. Extensive experiments on the publicly available CelebA dataset show the feasibility and robustness of our proposed model. Code is available at \url{https://github.com/mdhosen/Mask-Face-Inpainting-Using-Residual-Attention-Unet}
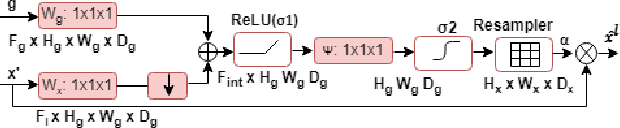
Retinal Image Restoration and Vessel Segmentation using Modified Cycle-CBAM and CBAM-UNet
Sep 09, 2022
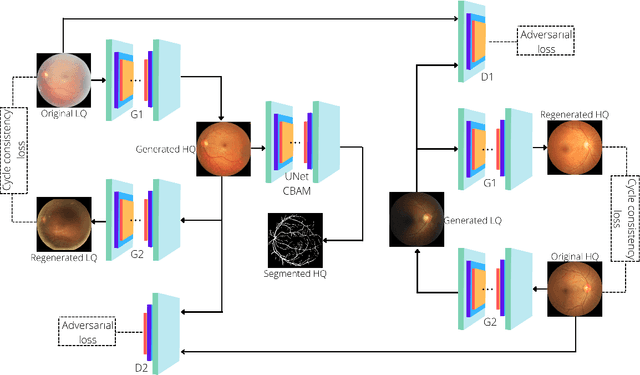
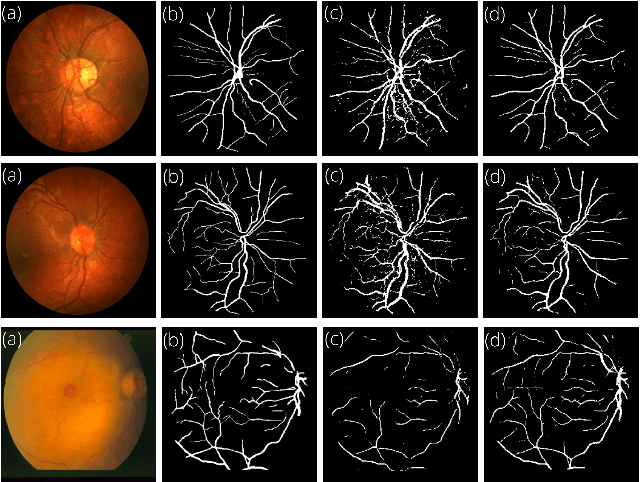
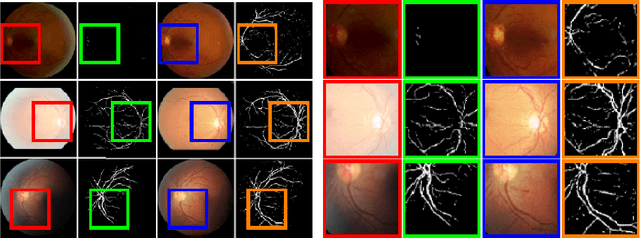
Clinical screening with low-quality fundus images is challenging and significantly leads to misdiagnosis. This paper addresses the issue of improving the retinal image quality and vessel segmentation through retinal image restoration. More specifically, a cycle-consistent generative adversarial network (CycleGAN) with a convolution block attention module (CBAM) is used for retinal image restoration. A modified UNet is used for retinal vessel segmentation for the restored retinal images (CBAM-UNet). The proposed model consists of two generators and two discriminators. Generators translate images from one domain to another, i.e., from low to high quality and vice versa. Discriminators classify generated and original images. The retinal vessel segmentation model uses downsampling, bottlenecking, and upsampling layers to generate segmented images. The CBAM has been used to enhance the feature extraction of these models. The proposed method does not require paired image datasets, which are challenging to produce. Instead, it uses unpaired data that consists of low- and high-quality fundus images retrieved from publicly available datasets. The restoration performance of the proposed method was evaluated using full-reference evaluation metrics, e.g., peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM). The retinal vessel segmentation performance was compared with the ground-truth fundus images. The proposed method can significantly reduce the degradation effects caused by out-of-focus blurring, color distortion, low, high, and uneven illumination. Experimental results show the effectiveness of the proposed method for retinal image restoration and vessel segmentation.
A New Dataset and Transformer for Stereoscopic Video Super-Resolution
Apr 21, 2022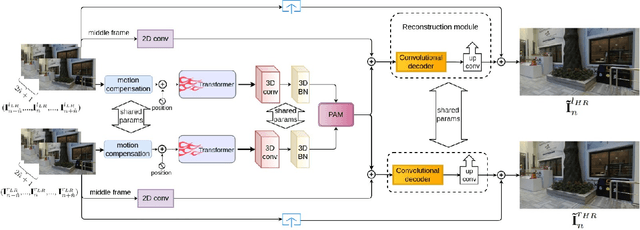

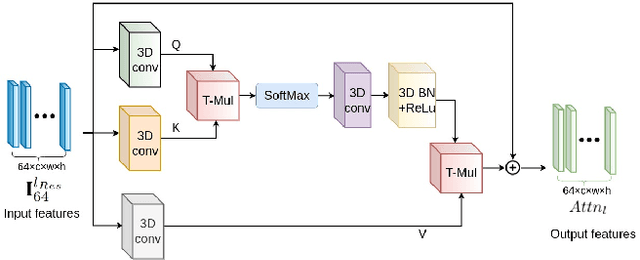
Stereo video super-resolution (SVSR) aims to enhance the spatial resolution of the low-resolution video by reconstructing the high-resolution video. The key challenges in SVSR are preserving the stereo-consistency and temporal-consistency, without which viewers may experience 3D fatigue. There are several notable works on stereoscopic image super-resolution, but there is little research on stereo video super-resolution. In this paper, we propose a novel Transformer-based model for SVSR, namely Trans-SVSR. Trans-SVSR comprises two key novel components: a spatio-temporal convolutional self-attention layer and an optical flow-based feed-forward layer that discovers the correlation across different video frames and aligns the features. The parallax attention mechanism (PAM) that uses the cross-view information to consider the significant disparities is used to fuse the stereo views. Due to the lack of a benchmark dataset suitable for the SVSR task, we collected a new stereoscopic video dataset, SVSR-Set, containing 71 full high-definition (HD) stereo videos captured using a professional stereo camera. Extensive experiments on the collected dataset, along with two other datasets, demonstrate that the Trans-SVSR can achieve competitive performance compared to the state-of-the-art methods. Project code and additional results are available at https://github.com/H-deep/Trans-SVSR/
An Efficient End-to-End Deep Neural Network for Interstitial Lung Disease Recognition and Classification
Apr 21, 2022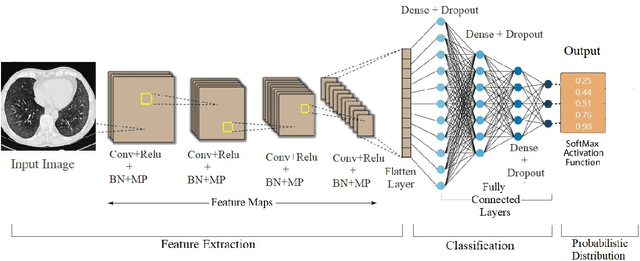
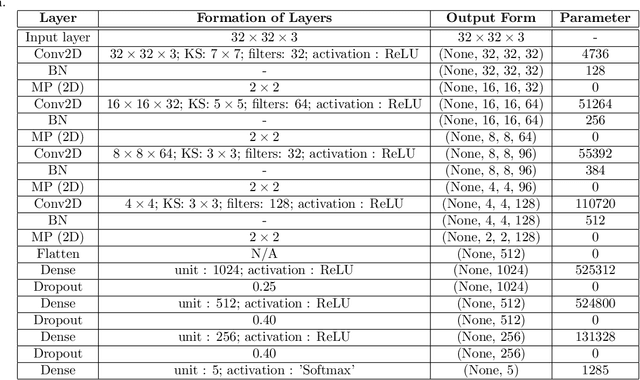
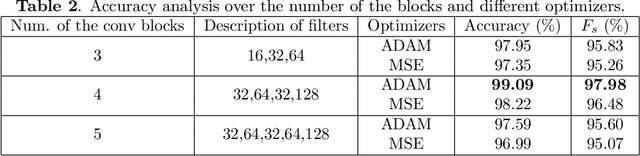
The automated Interstitial Lung Diseases (ILDs) classification technique is essential for assisting clinicians during the diagnosis process. Detecting and classifying ILDs patterns is a challenging problem. This paper introduces an end-to-end deep convolution neural network (CNN) for classifying ILDs patterns. The proposed model comprises four convolutional layers with different kernel sizes and Rectified Linear Unit (ReLU) activation function, followed by batch normalization and max-pooling with a size equal to the final feature map size well as four dense layers. We used the ADAM optimizer to minimize categorical cross-entropy. A dataset consisting of 21328 image patches of 128 CT scans with five classes is taken to train and assess the proposed model. A comparison study showed that the presented model outperformed pre-trained CNNs and five-fold cross-validation on the same dataset. For ILDs pattern classification, the proposed approach achieved the accuracy scores of 99.09% and the average F score of 97.9%, outperforming three pre-trained CNNs. These outcomes show that the proposed model is relatively state-of-the-art in precision, recall, f score, and accuracy.
HiMODE: A Hybrid Monocular Omnidirectional Depth Estimation Model
Apr 11, 2022
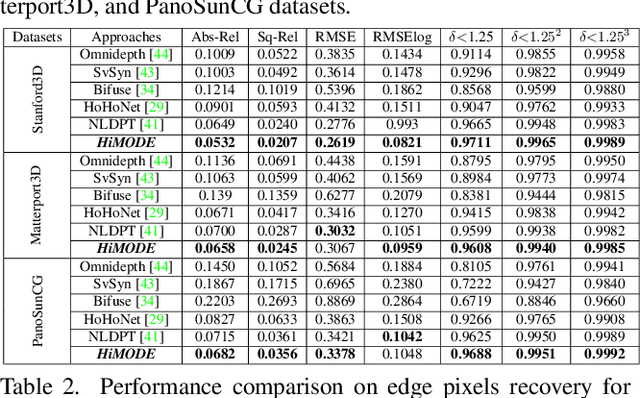
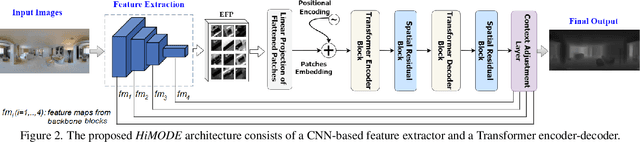
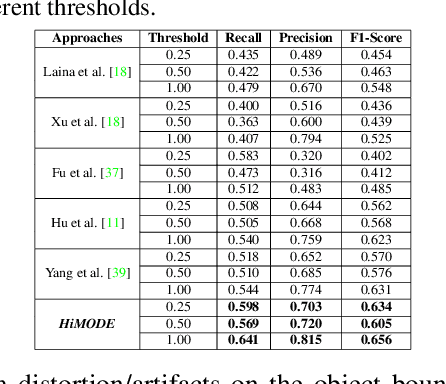
Monocular omnidirectional depth estimation is receiving considerable research attention due to its broad applications for sensing 360{\deg} surroundings. Existing approaches in this field suffer from limitations in recovering small object details and data lost during the ground-truth depth map acquisition. In this paper, a novel monocular omnidirectional depth estimation model, namely HiMODE is proposed based on a hybrid CNN+Transformer (encoder-decoder) architecture whose modules are efficiently designed to mitigate distortion and computational cost, without performance degradation. Firstly, we design a feature pyramid network based on the HNet block to extract high-resolution features near the edges. The performance is further improved, benefiting from a self and cross attention layer and spatial/temporal patches in the Transformer encoder and decoder, respectively. Besides, a spatial residual block is employed to reduce the number of parameters. By jointly passing the deep features extracted from an input image at each backbone block, along with the raw depth maps predicted by the transformer encoder-decoder, through a context adjustment layer, our model can produce resulting depth maps with better visual quality than the ground-truth. Comprehensive ablation studies demonstrate the significance of each individual module. Extensive experiments conducted on three datasets; Stanford3D, Matterport3D, and SunCG, demonstrate that HiMODE can achieve state-of-the-art performance for 360{\deg} monocular depth estimation.