 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantization Robustness to Input Degradations for Object Detection
Aug 27, 2025Post-training quantization (PTQ) is crucial for deploying efficient object detection models, like YOLO, on resource-constrained devices. However, the impact of reduced precision on model robustness to real-world input degradations such as noise, blur, and compression artifacts is a significant concern. This paper presents a comprehensive empirical study evaluating the robustness of YOLO models (nano to extra-large scales) across multiple precision formats: FP32, FP16 (TensorRT), Dynamic UINT8 (ONNX), and Static INT8 (TensorRT). We introduce and evaluate a degradation-aware calibration strategy for Static INT8 PTQ, where the TensorRT calibration process is exposed to a mix of clean and synthetically degraded images. Models were benchmarked on the COCO dataset under seven distinct degradation conditions (including various types and levels of noise, blur, low contrast, and JPEG compression) and a mixed-degradation scenario. Results indicate that while Static INT8 TensorRT engines offer substantial speedups (~1.5-3.3x) with a moderate accuracy drop (~3-7% mAP50-95) on clean data, the proposed degradation-aware calibration did not yield consistent, broad improvements in robustness over standard clean-data calibration across most models and degradations. A notable exception was observed for larger model scales under specific noise conditions, suggesting model capacity may influence the efficacy of this calibration approach. These findings highlight the challenges in enhancing PTQ robustness and provide insights for deploying quantized detectors in uncontrolled environments. All code and evaluation tables are available at https://github.com/AllanK24/QRID.
Saliency-aware Stereoscopic Video Retargeting
Apr 18, 2023



Stereo video retargeting aims to resize an image to a desired aspect ratio. The quality of retargeted videos can be significantly impacted by the stereo videos spatial, temporal, and disparity coherence, all of which can be impacted by the retargeting process. Due to the lack of a publicly accessible annotated dataset, there is little research on deep learning-based methods for stereo video retargeting. This paper proposes an unsupervised deep learning-based stereo video retargeting network. Our model first detects the salient objects and shifts and warps all objects such that it minimizes the distortion of the salient parts of the stereo frames. We use 1D convolution for shifting the salient objects and design a stereo video Transformer to assist the retargeting process. To train the network, we use the parallax attention mechanism to fuse the left and right views and feed the retargeted frames to a reconstruction module that reverses the retargeted frames to the input frames. Therefore, the network is trained in an unsupervised manner. Extensive qualitative and quantitative experiments and ablation studies on KITTI stereo 2012 and 2015 datasets demonstrate the efficiency of the proposed method over the existing state-of-the-art methods. The code is available at https://github.com/z65451/SVR/.
A New Dataset and Transformer for Stereoscopic Video Super-Resolution
Apr 21, 2022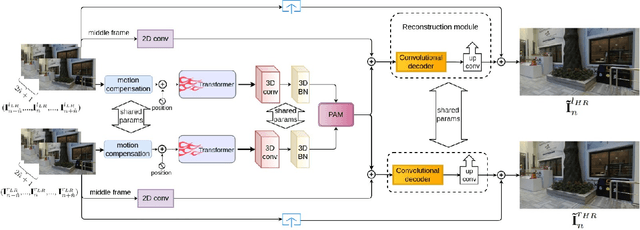
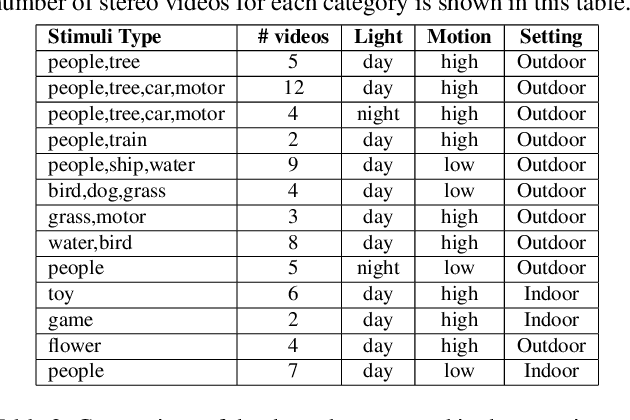

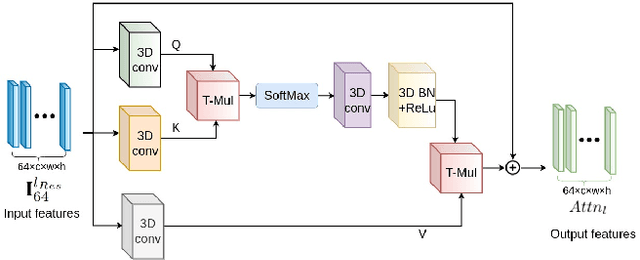
Stereo video super-resolution (SVSR) aims to enhance the spatial resolution of the low-resolution video by reconstructing the high-resolution video. The key challenges in SVSR are preserving the stereo-consistency and temporal-consistency, without which viewers may experience 3D fatigue. There are several notable works on stereoscopic image super-resolution, but there is little research on stereo video super-resolution. In this paper, we propose a novel Transformer-based model for SVSR, namely Trans-SVSR. Trans-SVSR comprises two key novel components: a spatio-temporal convolutional self-attention layer and an optical flow-based feed-forward layer that discovers the correlation across different video frames and aligns the features. The parallax attention mechanism (PAM) that uses the cross-view information to consider the significant disparities is used to fuse the stereo views. Due to the lack of a benchmark dataset suitable for the SVSR task, we collected a new stereoscopic video dataset, SVSR-Set, containing 71 full high-definition (HD) stereo videos captured using a professional stereo camera. Extensive experiments on the collected dataset, along with two other datasets, demonstrate that the Trans-SVSR can achieve competitive performance compared to the state-of-the-art methods. Project code and additional results are available at https://github.com/H-deep/Trans-SVSR/