 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Dataset and Transformer for Stereoscopic Video Super-Resolution
Paper and Code
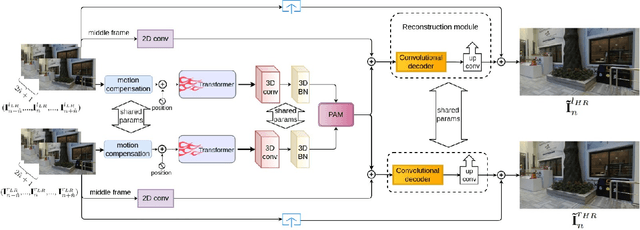
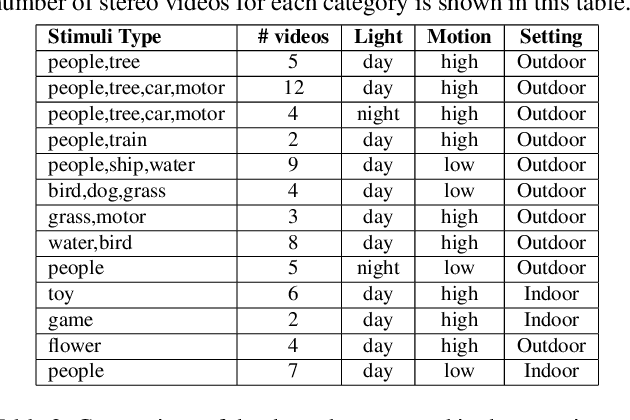

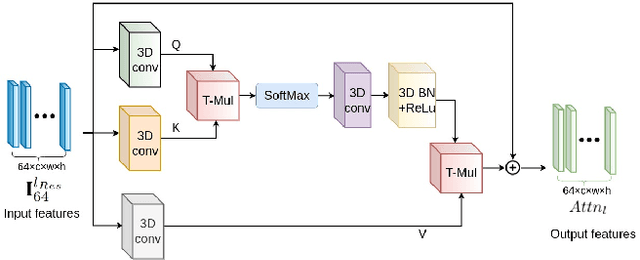
Stereo video super-resolution (SVSR) aims to enhance the spatial resolution of the low-resolution video by reconstructing the high-resolution video. The key challenges in SVSR are preserving the stereo-consistency and temporal-consistency, without which viewers may experience 3D fatigue. There are several notable works on stereoscopic image super-resolution, but there is little research on stereo video super-resolution. In this paper, we propose a novel Transformer-based model for SVSR, namely Trans-SVSR. Trans-SVSR comprises two key novel components: a spatio-temporal convolutional self-attention layer and an optical flow-based feed-forward layer that discovers the correlation across different video frames and aligns the features. The parallax attention mechanism (PAM) that uses the cross-view information to consider the significant disparities is used to fuse the stereo views. Due to the lack of a benchmark dataset suitable for the SVSR task, we collected a new stereoscopic video dataset, SVSR-Set, containing 71 full high-definition (HD) stereo videos captured using a professional stereo camera. Extensive experiments on the collected dataset, along with two other datasets, demonstrate that the Trans-SVSR can achieve competitive performance compared to the state-of-the-art methods. Project code and additional results are available at https://github.com/H-deep/Trans-SVSR/