 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivator: GLU Activations as The Core Functions of a Vision Transformer
May 24, 2024Transformer architecture currently represents the main driver behind many successes in a variety of tasks addressed by deep learning, especially the recent advances in natural language processing (NLP) culminating with large language models (LLM). In addition, transformer architecture has found a wide spread of interest from computer vision (CV) researchers and practitioners, allowing for many advancements in vision-related tasks and opening the door for multi-task and multi-modal deep learning architectures that share the same principle of operation. One drawback to these architectures is their reliance on the scaled dot product attention mechanism with the softmax activation function, which is computationally expensive and requires large compute capabilities both for training and inference. This paper investigates substituting the attention mechanism usually adopted for transformer architecture with an architecture incorporating gated linear unit (GLU) activation within a multi-layer perceptron (MLP) structure in conjunction with the default MLP incorporated in the traditional transformer design. Another step forward taken by this paper is to eliminate the second non-gated MLP to further reduce the computational cost. Experimental assessments conducted by this research show that both proposed modifications and reductions offer competitive performance in relation to baseline architectures, in support of the aims of this work in establishing a more efficient yet capable alternative to the traditional attention mechanism as the core component in designing transformer architectures.
NiNformer: A Network in Network Transformer with Token Mixing Generated Gating Function
Mar 04, 2024The Attention mechanism is the main component of the Transformer architecture, and since its introduction, it has led to significant advancements in Deep Learning that span many domains and multiple tasks. The Attention Mechanism was utilized in Computer Vision as the Vision Transformer ViT, and its usage has expanded into many tasks in the vision domain, such as classification, segmentation, object detection, and image generation. While this mechanism is very expressive and capable, it comes with the drawback of being computationally expensive and requiring datasets of considerable size for effective optimization. To address these shortcomings, many designs have been proposed in the literature to reduce the computational burden and alleviate the data size requirements. Examples of such attempts in the vision domain are the MLP-Mixer, the Conv-Mixer, the Perciver-IO, and many more. This paper introduces a new computational block as an alternative to the standard ViT block that reduces the compute burdens by replacing the normal Attention layers with a Network in Network structure that enhances the static approach of the MLP Mixer with a dynamic system of learning an element-wise gating function by a token mixing process. Extensive experimentation shows that the proposed design provides better performance than the baseline architectures on multiple datasets applied in the image classification task of the vision domain.
HiMODE: A Hybrid Monocular Omnidirectional Depth Estimation Model
Apr 11, 2022
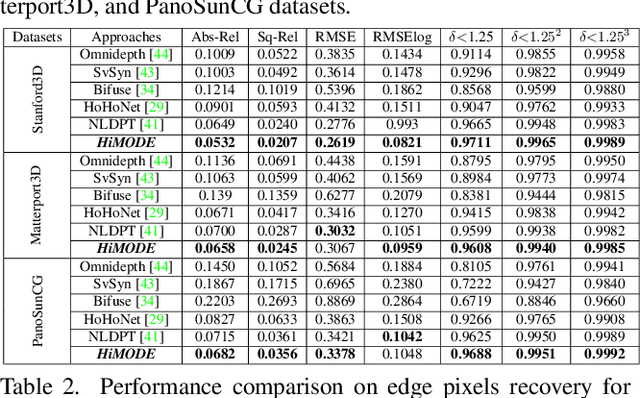
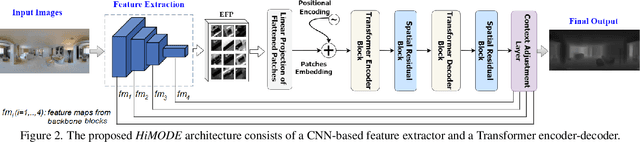
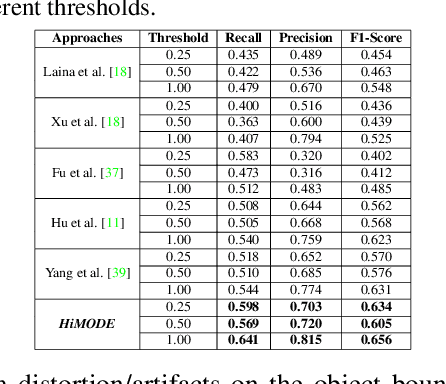
Monocular omnidirectional depth estimation is receiving considerable research attention due to its broad applications for sensing 360{\deg} surroundings. Existing approaches in this field suffer from limitations in recovering small object details and data lost during the ground-truth depth map acquisition. In this paper, a novel monocular omnidirectional depth estimation model, namely HiMODE is proposed based on a hybrid CNN+Transformer (encoder-decoder) architecture whose modules are efficiently designed to mitigate distortion and computational cost, without performance degradation. Firstly, we design a feature pyramid network based on the HNet block to extract high-resolution features near the edges. The performance is further improved, benefiting from a self and cross attention layer and spatial/temporal patches in the Transformer encoder and decoder, respectively. Besides, a spatial residual block is employed to reduce the number of parameters. By jointly passing the deep features extracted from an input image at each backbone block, along with the raw depth maps predicted by the transformer encoder-decoder, through a context adjustment layer, our model can produce resulting depth maps with better visual quality than the ground-truth. Comprehensive ablation studies demonstrate the significance of each individual module. Extensive experiments conducted on three datasets; Stanford3D, Matterport3D, and SunCG, demonstrate that HiMODE can achieve state-of-the-art performance for 360{\deg} monocular depth estimation.