 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSA-Tokenizer: Disentangled Semantic-Acoustic Tokenization via Flow Matching-based Hierarchical Fusion
Jan 15, 2026Speech tokenizers serve as the cornerstone of discrete Speech Large Language Models (Speech LLMs). Existing tokenizers either prioritize semantic encoding, fuse semantic content with acoustic style inseparably, or achieve incomplete semantic-acoustic disentanglement. To achieve better disentanglement, we propose DSA-Tokenizer, which explicitly disentangles speech into discrete semantic and acoustic tokens via distinct optimization constraints. Specifically, semantic tokens are supervised by ASR to capture linguistic content, while acoustic tokens focus on mel-spectrograms restoration to encode style. To eliminate rigid length constraints between the two sequences, we introduce a hierarchical Flow-Matching decoder that further improve speech generation quality. Furthermore, We employ a joint reconstruction-recombination training strategy to enforce this separation. DSA-Tokenizer enables high fidelity reconstruction and flexible recombination through robust disentanglement, facilitating controllable generation in speech LLMs. Our analysis highlights disentangled tokenization as a pivotal paradigm for future speech modeling. Audio samples are avaialble at https://anonymous.4open.science/w/DSA_Tokenizer_demo/. The code and model will be made publicly available after the paper has been accepted.
Orion-RAG: Path-Aligned Hybrid Retrieval for Graphless Data
Jan 08, 2026Retrieval-Augmented Generation (RAG) has proven effective for knowledge synthesis, yet it encounters significant challenges in practical scenarios where data is inherently discrete and fragmented. In most environments, information is distributed across isolated files like reports and logs that lack explicit links. Standard search engines process files independently, ignoring the connections between them. Furthermore, manually building Knowledge Graphs is impractical for such vast data. To bridge this gap, we present Orion-RAG. Our core insight is simple yet effective: we do not need heavy algorithms to organize this data. Instead, we use a low-complexity strategy to extract lightweight paths that naturally link related concepts. We demonstrate that this streamlined approach suffices to transform fragmented documents into semi-structured data, enabling the system to link information across different files effectively. Extensive experiments demonstrate that Orion-RAG consistently outperforms mainstream frameworks across diverse domains, supporting real-time updates and explicit Human-in-the-Loop verification with high cost-efficiency. Experiments on FinanceBench demonstrate superior precision with a 25.2% relative improvement over strong baselines.
SATMapTR: Satellite Image Enhanced Online HD Map Construction
Dec 12, 2025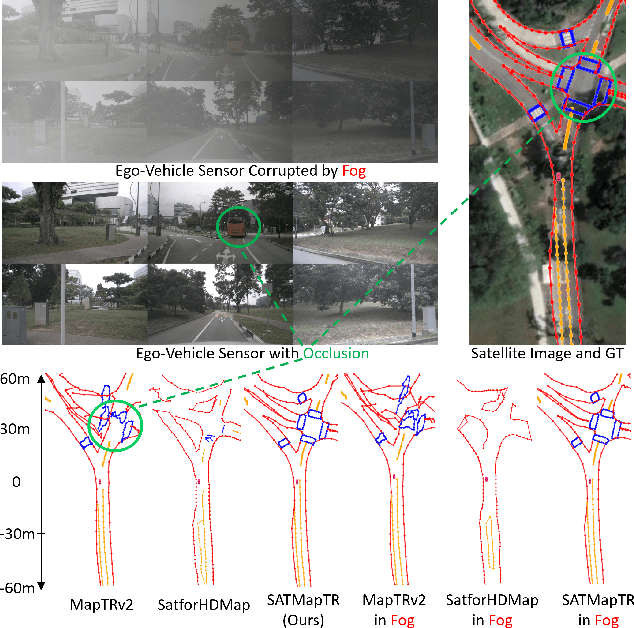
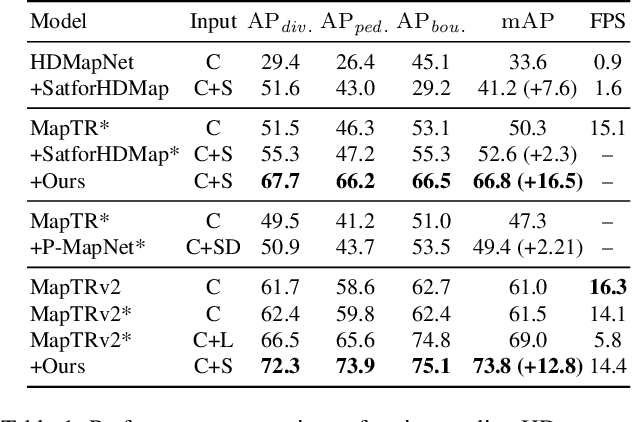
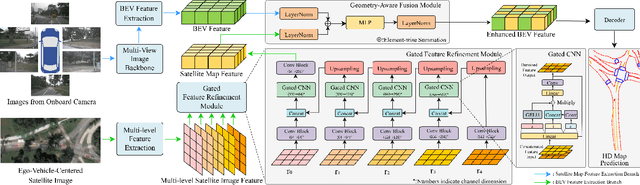
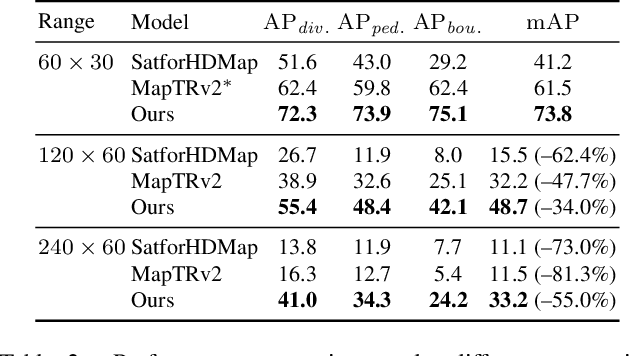
High-definition (HD) maps are evolving from pre-annotated to real-time construction to better support autonomous driving in diverse scenarios. However, this process is hindered by low-quality input data caused by onboard sensors limited capability and frequent occlusions, leading to incomplete, noisy, or missing data, and thus reduced mapping accuracy and robustness. Recent efforts have introduced satellite images as auxiliary input, offering a stable, wide-area view to complement the limited ego perspective. However, satellite images in Bird's Eye View are often degraded by shadows and occlusions from vegetation and buildings. Prior methods using basic feature extraction and fusion remain ineffective. To address these challenges, we propose SATMapTR, a novel online map construction model that effectively fuses satellite image through two key components: (1) a gated feature refinement module that adaptively filters satellite image features by integrating high-level semantics with low-level structural cues to extract high signal-to-noise ratio map-relevant representations; and (2) a geometry-aware fusion module that consistently fuse satellite and BEV features at a grid-to-grid level, minimizing interference from irrelevant regions and low-quality inputs. Experimental results on the nuScenes dataset show that SATMapTR achieves the highest mean average precision (mAP) of 73.8, outperforming state-of-the-art satellite-enhanced models by up to 14.2 mAP. It also shows lower mAP degradation under adverse weather and sensor failures, and achieves nearly 3 times higher mAP at extended perception ranges.
Global Regulation and Excitation via Attention Tuning for Stereo Matching
Sep 19, 2025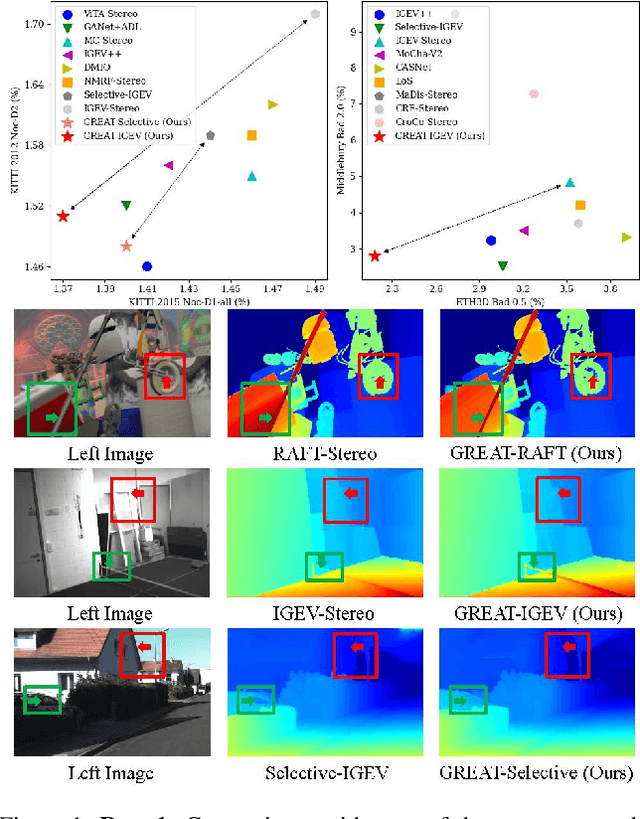
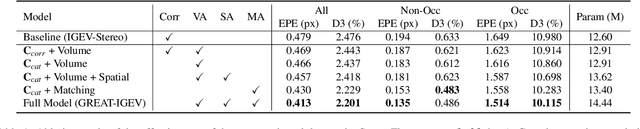
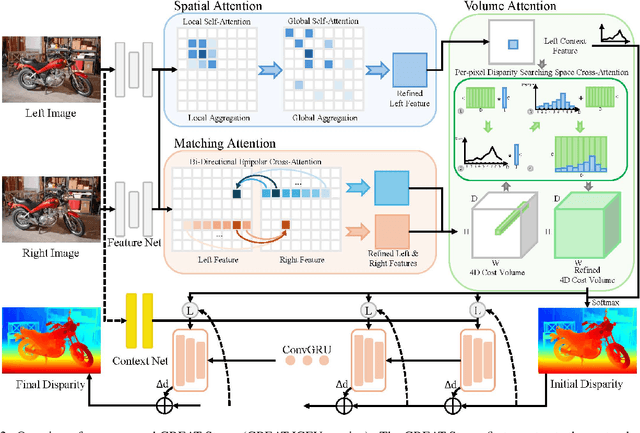
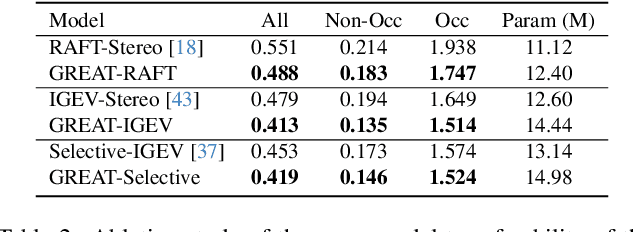
Stereo matching achieves significant progress with iterative algorithms like RAFT-Stereo and IGEV-Stereo. However, these methods struggle in ill-posed regions with occlusions, textureless, or repetitive patterns, due to a lack of global context and geometric information for effective iterative refinement. To enable the existing iterative approaches to incorporate global context, we propose the Global Regulation and Excitation via Attention Tuning (GREAT) framework which encompasses three attention modules. Specifically, Spatial Attention (SA) captures the global context within the spatial dimension, Matching Attention (MA) extracts global context along epipolar lines, and Volume Attention (VA) works in conjunction with SA and MA to construct a more robust cost-volume excited by global context and geometric details. To verify the universality and effectiveness of this framework, we integrate it into several representative iterative stereo-matching methods and validate it through extensive experiments, collectively denoted as GREAT-Stereo. This framework demonstrates superior performance in challenging ill-posed regions. Applied to IGEV-Stereo, among all published methods, our GREAT-IGEV ranks first on the Scene Flow test set, KITTI 2015, and ETH3D leaderboards, and achieves second on the Middlebury benchmark. Code is available at https://github.com/JarvisLee0423/GREAT-Stereo.
CALM: Co-evolution of Algorithms and Language Model for Automatic Heuristic Design
May 18, 2025Tackling complex optimization problems often relies on expert-designed heuristics, typically crafted through extensive trial and error. Recent advances demonstrate that large language models (LLMs), when integrated into well-designed evolutionary search frameworks, can autonomously discover high-performing heuristics at a fraction of the traditional cost. However, existing approaches predominantly rely on verbal guidance, i.e., manipulating the prompt generation process, to steer the evolution of heuristics, without adapting the underlying LLM. We propose a hybrid framework that combines verbal and numerical guidance, the latter achieved by fine-tuning the LLM via reinforcement learning based on the quality of generated heuristics. This joint optimization allows the LLM to co-evolve with the search process. Our method outperforms state-of-the-art (SOTA) baselines across various optimization tasks, running locally on a single 24GB GPU using a 7B model with INT4 quantization. It surpasses methods that rely solely on verbal guidance, even when those use significantly more powerful API-based models.
A Knowledge-Informed Deep Learning Paradigm for Generalizable and Stability-Optimized Car-Following Models
Apr 19, 2025Car-following models (CFMs) are fundamental to traffic flow analysis and autonomous driving. Although calibrated physics-based and trained data-driven CFMs can replicate human driving behavior, their reliance on specific datasets limits generalization across diverse scenarios and reduces reliability in real-world deployment. Moreover, these models typically focus on behavioral fidelity and do not support the explicit optimization of local and string stability, which are increasingly important for the safe and efficient operation of autonomous vehicles (AVs). To address these limitations, we propose a Knowledge-Informed Deep Learning (KIDL) paradigm that distills the generalization capabilities of pre-trained Large Language Models (LLMs) into a lightweight and stability-aware neural architecture. LLMs are used to extract fundamental car-following knowledge beyond dataset-specific patterns, and this knowledge is transferred to a reliable, tractable, and computationally efficient model through knowledge distillation. KIDL also incorporates stability constraints directly into its training objective, ensuring that the resulting model not only emulates human-like behavior but also satisfies the local and string stability requirements essential for real-world AV deployment. We evaluate KIDL on the real-world NGSIM and HighD datasets, comparing its performance with representative physics-based, data-driven, and hybrid CFMs. Both empirical and theoretical results consistently demonstrate KIDL's superior behavioral generalization and traffic flow stability, offering a robust and scalable solution for next-generation traffic systems.
DSSR-Net for Super-Resolution Radar Range Profiles
Apr 06, 2025High-resolution radar range profile (RRP) is crucial for accurate target recognition and scene perception. To get a high-resolution RRP, many methods have been developed, such as multiple signal classification (MUSIC), orthogonal matching pursuit (OMP), and a few deep learning-based approaches. Although they break through the Rayleigh resolution limit determined by radar signal bandwidth, these methods either get limited super-resolution capability or work well just in high signal to noise ratio (SNR) scenarios. To overcome these limitations, in this paper, an interpretable neural network for super-resolution RRP (DSSR-Net) is proposed by integrating the advantages of both model-guided and data-driven models. Specifically, DSSR-Net is designed based on a sparse representation model with dimension scaling, and then trained on a training dataset. Through dimension scaling, DSSR-Net lifts the radar signal into high-dimensional space to extract subtle features of closely spaced objects and suppress the noise of the high-dimensional features. It improves the super-resolving power of closely spaced objects and lowers the SNR requirement of radar signals compared to existing methods. The superiority of the proposed algorithm for super-resolution RRP reconstruction is verified via experiments with both synthetic and measured data.
VLM-C4L: Continual Core Dataset Learning with Corner Case Optimization via Vision-Language Models for Autonomous Driving
Mar 29, 2025With the widespread adoption and deployment of autonomous driving, handling complex environments has become an unavoidable challenge. Due to the scarcity and diversity of extreme scenario datasets, current autonomous driving models struggle to effectively manage corner cases. This limitation poses a significant safety risk, according to the National Highway Traffic Safety Administration (NHTSA), autonomous vehicle systems have been involved in hundreds of reported crashes annually in the United States, occurred in corner cases like sun glare and fog, which caused a few fatal accident. Furthermore, in order to consistently maintain a robust and reliable autonomous driving system, it is essential for models not only to perform well on routine scenarios but also to adapt to newly emerging scenarios, especially those corner cases that deviate from the norm. This requires a learning mechanism that incrementally integrates new knowledge without degrading previously acquired capabilities. However, to the best of our knowledge, no existing continual learning methods have been proposed to ensure consistent and scalable corner case learning in autonomous driving. To address these limitations, we propose VLM-C4L, a continual learning framework that introduces Vision-Language Models (VLMs) to dynamically optimize and enhance corner case datasets, and VLM-C4L combines VLM-guided high-quality data extraction with a core data replay strategy, enabling the model to incrementally learn from diverse corner cases while preserving performance on previously routine scenarios, thus ensuring long-term stability and adaptability in real-world autonomous driving. We evaluate VLM-C4L on large-scale real-world autonomous driving datasets, including Waymo and the corner case dataset CODA.
CoT-VLM4Tar: Chain-of-Thought Guided Vision-Language Models for Traffic Anomaly Resolution
Mar 03, 2025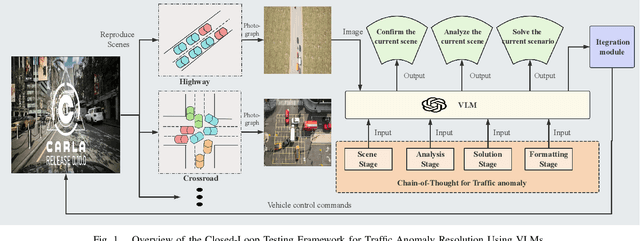
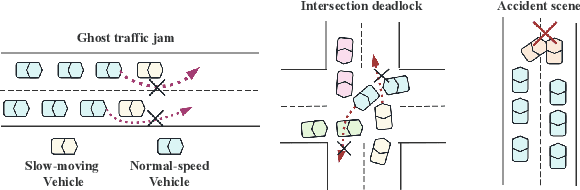
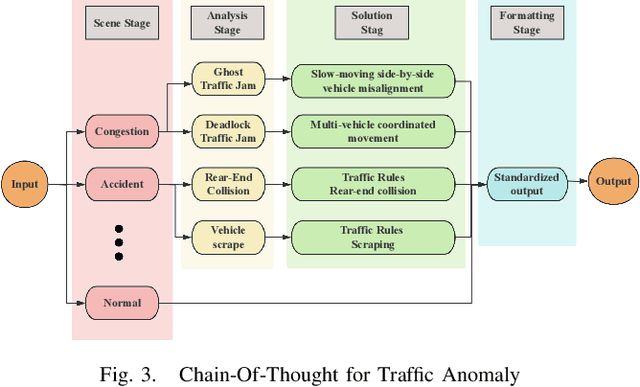
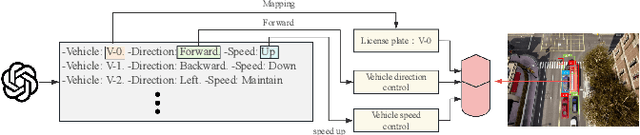
With the acceleration of urbanization, modern urban traffic systems are becoming increasingly complex, leading to frequent traffic anomalies. These anomalies encompass not only common traffic jams but also more challenging issues such as phantom traffic jams, intersection deadlocks, and accident liability analysis, which severely impact traffic flow, vehicular safety, and overall transportation efficiency. Currently, existing solutions primarily rely on manual intervention by traffic police or artificial intelligence-based detection systems. However, these methods often suffer from response delays and inconsistent management due to inadequate resources, while AI detection systems, despite enhancing efficiency to some extent, still struggle to handle complex traffic anomalies in a real-time and precise manner. To address these issues, we propose CoT-VLM4Tar: (Chain of Thought Visual-Language Model for Traffic Anomaly Resolution), this innovative approach introduces a new chain-of-thought to guide the VLM in analyzing, reasoning, and generating solutions for traffic anomalies with greater reasonable and effective solution, and to evaluate the performance and effectiveness of our method, we developed a closed-loop testing framework based on the CARLA simulator. Furthermore, to ensure seamless integration of the solutions generated by the VLM with the CARLA simulator, we implement an itegration module that converts these solutions into executable commands. Our results demonstrate the effectiveness of VLM in the resolution of real-time traffic anomalies, providing a proof-of-concept for its integration into autonomous traffic management systems.
Communication Strategy on Macro-and-Micro Traffic State in Cooperative Deep Reinforcement Learning for Regional Traffic Signal Control
Feb 18, 2025Adaptive Traffic Signal Control (ATSC) has become a popular research topic in intelligent transportation systems. Regional Traffic Signal Control (RTSC) using the Multi-agent Deep Reinforcement Learning (MADRL) technique has become a promising approach for ATSC due to its ability to achieve the optimum trade-off between scalability and optimality. Most existing RTSC approaches partition a traffic network into several disjoint regions, followed by applying centralized reinforcement learning techniques to each region. However, the pursuit of cooperation among RTSC agents still remains an open issue and no communication strategy for RTSC agents has been investigated. In this paper, we propose communication strategies to capture the correlation of micro-traffic states among lanes and the correlation of macro-traffic states among intersections. We first justify the evolution equation of the RTSC process is Markovian via a system of store-and-forward queues. Next, based on the evolution equation, we propose two GAT-Aggregated (GA2) communication modules--GA2-Naive and GA2-Aug to extract both intra-region and inter-region correlations between macro and micro traffic states. While GA2-Naive only considers the movements at each intersection, GA2-Aug also considers the lane-changing behavior of vehicles. Two proposed communication modules are then aggregated into two existing novel RTSC frameworks--RegionLight and Regional-DRL. Experimental results demonstrate that both GA2-Naive and GA2-Aug effectively improve the performance of existing RTSC frameworks under both real and synthetic scenarios. Hyperparameter testing also reveals the robustness and potential of our communication modules in large-scale traffic networks.