 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Dependency Dynamics in Multi-Agent Reinforcement Learning for Traffic Signal Control
Feb 23, 2025Reinforcement learning (RL) emerges as a promising data-driven approach for adaptive traffic signal control (ATSC) in complex urban traffic networks, with deep neural networks substantially augmenting its learning capabilities. However, centralized RL becomes impractical for ATSC involving multiple agents due to the exceedingly high dimensionality of the joint action space. Multi-agent RL (MARL) mitigates this scalability issue by decentralizing control to local RL agents. Nevertheless, this decentralized method introduces new challenges: the environment becomes partially observable from the perspective of each local agent due to constrained inter-agent communication. Both centralized RL and MARL exhibit distinct strengths and weaknesses, particularly under heavy intersectional traffic conditions. In this paper, we justify that MARL can achieve the optimal global Q-value by separating into multiple IRL (Independent Reinforcement Learning) processes when no spill-back congestion occurs (no agent dependency) among agents (intersections). In the presence of spill-back congestion (with agent dependency), the maximum global Q-value can be achieved by using centralized RL. Building upon the conclusions, we propose a novel Dynamic Parameter Update Strategy for Deep Q-Network (DQN-DPUS), which updates the weights and bias based on the dependency dynamics among agents, i.e. updating only the diagonal sub-matrices for the scenario without spill-back congestion. We validate the DQN-DPUS in a simple network with two intersections under varying traffic, and show that the proposed strategy can speed up the convergence rate without sacrificing optimal exploration. The results corroborate our theoretical findings, demonstrating the efficacy of DQN-DPUS in optimizing traffic signal control.
Communication Strategy on Macro-and-Micro Traffic State in Cooperative Deep Reinforcement Learning for Regional Traffic Signal Control
Feb 18, 2025Adaptive Traffic Signal Control (ATSC) has become a popular research topic in intelligent transportation systems. Regional Traffic Signal Control (RTSC) using the Multi-agent Deep Reinforcement Learning (MADRL) technique has become a promising approach for ATSC due to its ability to achieve the optimum trade-off between scalability and optimality. Most existing RTSC approaches partition a traffic network into several disjoint regions, followed by applying centralized reinforcement learning techniques to each region. However, the pursuit of cooperation among RTSC agents still remains an open issue and no communication strategy for RTSC agents has been investigated. In this paper, we propose communication strategies to capture the correlation of micro-traffic states among lanes and the correlation of macro-traffic states among intersections. We first justify the evolution equation of the RTSC process is Markovian via a system of store-and-forward queues. Next, based on the evolution equation, we propose two GAT-Aggregated (GA2) communication modules--GA2-Naive and GA2-Aug to extract both intra-region and inter-region correlations between macro and micro traffic states. While GA2-Naive only considers the movements at each intersection, GA2-Aug also considers the lane-changing behavior of vehicles. Two proposed communication modules are then aggregated into two existing novel RTSC frameworks--RegionLight and Regional-DRL. Experimental results demonstrate that both GA2-Naive and GA2-Aug effectively improve the performance of existing RTSC frameworks under both real and synthetic scenarios. Hyperparameter testing also reveals the robustness and potential of our communication modules in large-scale traffic networks.
Multi-agent Reinforcement Learning for Regional Signal control in Large-scale Grid Traffic network
Mar 22, 2023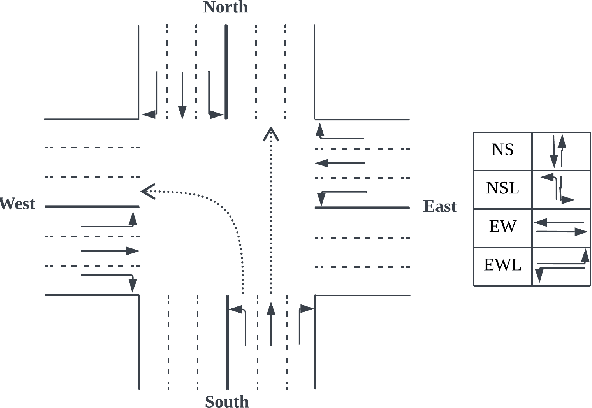
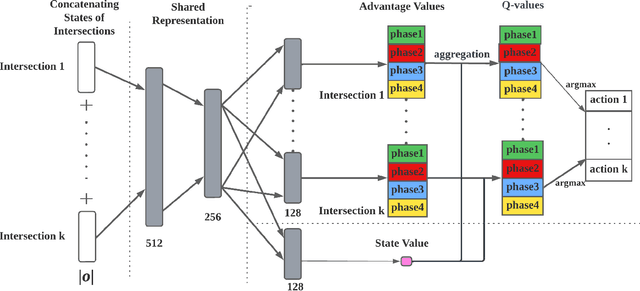
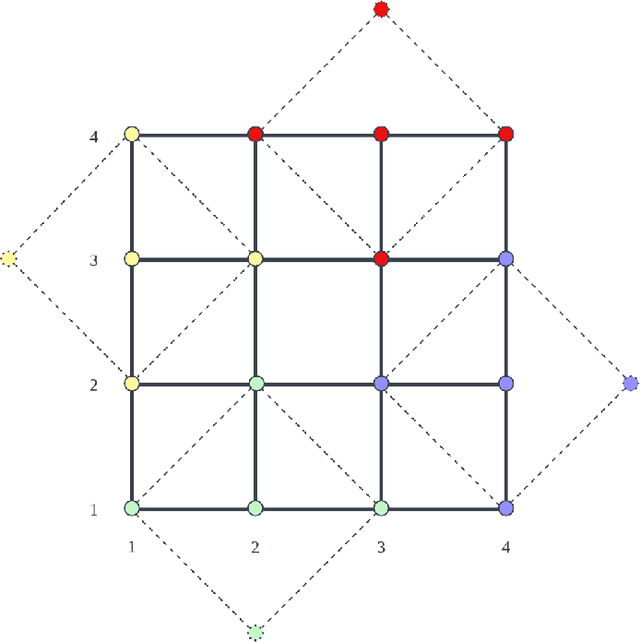
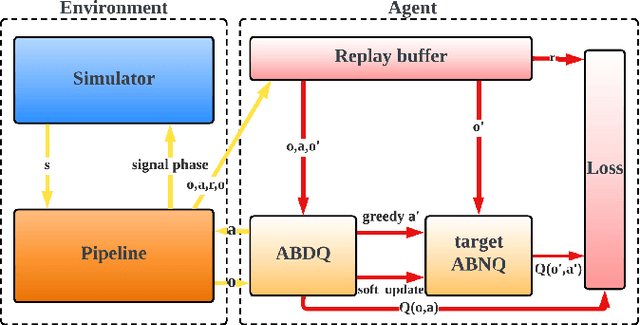
Adaptive traffic signal control with Multi-agent Reinforcement Learning(MARL) is a very popular topic nowadays. In most existing novel methods, one agent controls single intersections and these methods focus on the cooperation between intersections. However, the non-stationary property of MARL still limits the performance of the above methods as the size of traffic networks grows. One compromised strategy is to assign one agent with a region of intersections to reduce the number of agents. There are two challenges in this strategy, one is how to partition a traffic network into small regions and the other is how to search for the optimal joint actions for a region of intersections. In this paper, we propose a novel training framework RegionLight where our region partition rule is based on the adjacency between the intersection and extended Branching Dueling Q-Network(BDQ) to Dynamic Branching Dueling Q-Network(DBDQ) to bound the growth of the size of joint action space and alleviate the bias introduced by imaginary intersections outside of the boundary of the traffic network. Our experiments on both real datasets and synthetic datasets demonstrate that our framework performs best among other novel frameworks and that our region partition rule is robust.