 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSATMapTR: Satellite Image Enhanced Online HD Map Construction
Dec 12, 2025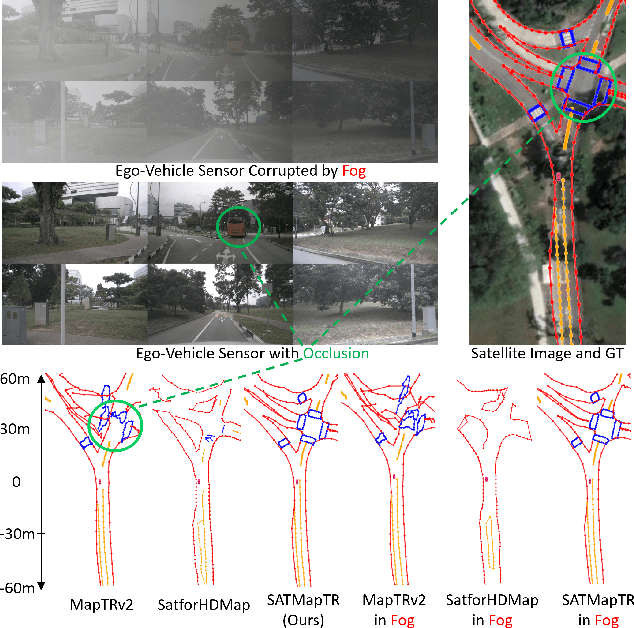
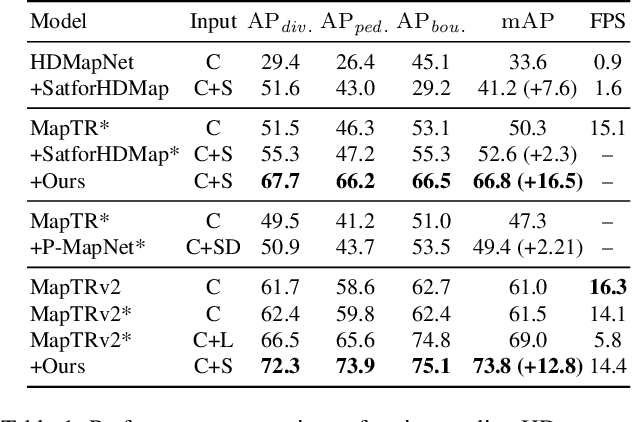
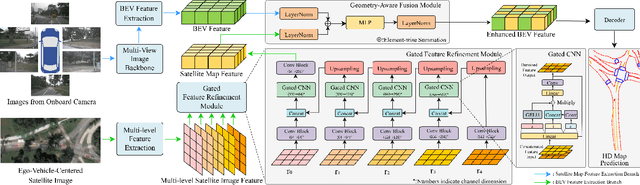
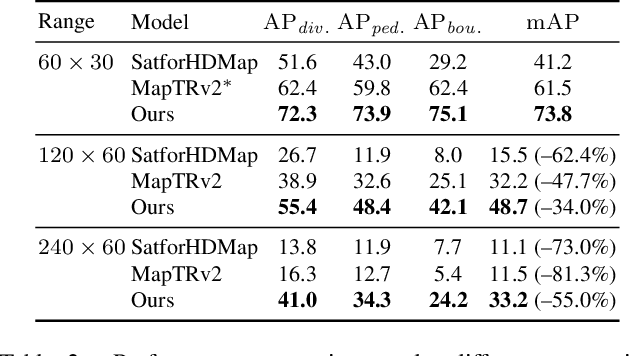
High-definition (HD) maps are evolving from pre-annotated to real-time construction to better support autonomous driving in diverse scenarios. However, this process is hindered by low-quality input data caused by onboard sensors limited capability and frequent occlusions, leading to incomplete, noisy, or missing data, and thus reduced mapping accuracy and robustness. Recent efforts have introduced satellite images as auxiliary input, offering a stable, wide-area view to complement the limited ego perspective. However, satellite images in Bird's Eye View are often degraded by shadows and occlusions from vegetation and buildings. Prior methods using basic feature extraction and fusion remain ineffective. To address these challenges, we propose SATMapTR, a novel online map construction model that effectively fuses satellite image through two key components: (1) a gated feature refinement module that adaptively filters satellite image features by integrating high-level semantics with low-level structural cues to extract high signal-to-noise ratio map-relevant representations; and (2) a geometry-aware fusion module that consistently fuse satellite and BEV features at a grid-to-grid level, minimizing interference from irrelevant regions and low-quality inputs. Experimental results on the nuScenes dataset show that SATMapTR achieves the highest mean average precision (mAP) of 73.8, outperforming state-of-the-art satellite-enhanced models by up to 14.2 mAP. It also shows lower mAP degradation under adverse weather and sensor failures, and achieves nearly 3 times higher mAP at extended perception ranges.
VLM-C4L: Continual Core Dataset Learning with Corner Case Optimization via Vision-Language Models for Autonomous Driving
Mar 29, 2025With the widespread adoption and deployment of autonomous driving, handling complex environments has become an unavoidable challenge. Due to the scarcity and diversity of extreme scenario datasets, current autonomous driving models struggle to effectively manage corner cases. This limitation poses a significant safety risk, according to the National Highway Traffic Safety Administration (NHTSA), autonomous vehicle systems have been involved in hundreds of reported crashes annually in the United States, occurred in corner cases like sun glare and fog, which caused a few fatal accident. Furthermore, in order to consistently maintain a robust and reliable autonomous driving system, it is essential for models not only to perform well on routine scenarios but also to adapt to newly emerging scenarios, especially those corner cases that deviate from the norm. This requires a learning mechanism that incrementally integrates new knowledge without degrading previously acquired capabilities. However, to the best of our knowledge, no existing continual learning methods have been proposed to ensure consistent and scalable corner case learning in autonomous driving. To address these limitations, we propose VLM-C4L, a continual learning framework that introduces Vision-Language Models (VLMs) to dynamically optimize and enhance corner case datasets, and VLM-C4L combines VLM-guided high-quality data extraction with a core data replay strategy, enabling the model to incrementally learn from diverse corner cases while preserving performance on previously routine scenarios, thus ensuring long-term stability and adaptability in real-world autonomous driving. We evaluate VLM-C4L on large-scale real-world autonomous driving datasets, including Waymo and the corner case dataset CODA.
A First Physical-World Trajectory Prediction Attack via LiDAR-induced Deceptions in Autonomous Driving
Jun 17, 2024



Trajectory prediction forecasts nearby agents' moves based on their historical trajectories. Accurate trajectory prediction is crucial for autonomous vehicles. Existing attacks compromise the prediction model of a victim AV by directly manipulating the historical trajectory of an attacker AV, which has limited real-world applicability. This paper, for the first time, explores an indirect attack approach that induces prediction errors via attacks against the perception module of a victim AV. Although it has been shown that physically realizable attacks against LiDAR-based perception are possible by placing a few objects at strategic locations, it is still an open challenge to find an object location from the vast search space in order to launch effective attacks against prediction under varying victim AV velocities. Through analysis, we observe that a prediction model is prone to an attack focusing on a single point in the scene. Consequently, we propose a novel two-stage attack framework to realize the single-point attack. The first stage of prediction-side attack efficiently identifies, guided by the distribution of detection results under object-based attacks against perception, the state perturbations for the prediction model that are effective and velocity-insensitive. In the second stage of location matching, we match the feasible object locations with the found state perturbations. Our evaluation using a public autonomous driving dataset shows that our attack causes a collision rate of up to 63% and various hazardous responses of the victim AV. The effectiveness of our attack is also demonstrated on a real testbed car. To the best of our knowledge, this study is the first security analysis spanning from LiDAR-based perception to prediction in autonomous driving, leading to a realistic attack on prediction. To counteract the proposed attack, potential defenses are discussed.
Uncertainty-Encoded Multi-Modal Fusion for Robust Object Detection in Autonomous Driving
Jul 30, 2023
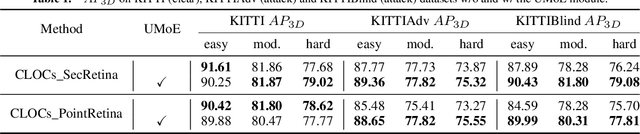

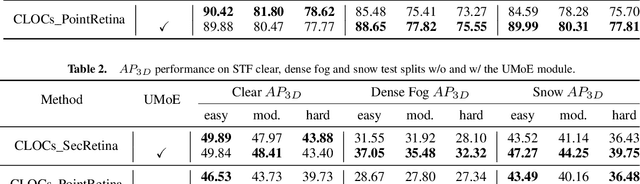
Multi-modal fusion has shown initial promising results for object detection of autonomous driving perception. However, many existing fusion schemes do not consider the quality of each fusion input and may suffer from adverse conditions on one or more sensors. While predictive uncertainty has been applied to characterize single-modal object detection performance at run time, incorporating uncertainties into the multi-modal fusion still lacks effective solutions due primarily to the uncertainty's cross-modal incomparability and distinct sensitivities to various adverse conditions. To fill this gap, this paper proposes Uncertainty-Encoded Mixture-of-Experts (UMoE) that explicitly incorporates single-modal uncertainties into LiDAR-camera fusion. UMoE uses individual expert network to process each sensor's detection result together with encoded uncertainty. Then, the expert networks' outputs are analyzed by a gating network to determine the fusion weights. The proposed UMoE module can be integrated into any proposal fusion pipeline. Evaluation shows that UMoE achieves a maximum of 10.67%, 3.17%, and 5.40% performance gain compared with the state-of-the-art proposal-level multi-modal object detectors under extreme weather, adversarial, and blinding attack scenarios.
SPP-CNN: An Efficient Framework for Network Robustness Prediction
May 13, 2023



This paper addresses the robustness of a network to sustain its connectivity and controllability against malicious attacks. This kind of network robustness is typically measured by the time-consuming attack simulation, which returns a sequence of values that record the remaining connectivity and controllability after a sequence of node- or edge-removal attacks. For improvement, this paper develops an efficient framework for network robustness prediction, the spatial pyramid pooling convolutional neural network (SPP-CNN). The new framework installs a spatial pyramid pooling layer between the convolutional and fully-connected layers, overcoming the common mismatch issue in the CNN-based prediction approaches and extending its generalizability. Extensive experiments are carried out by comparing SPP-CNN with three state-of-the-art robustness predictors, namely a CNN-based and two graph neural networks-based frameworks. Synthetic and real-world networks, both directed and undirected, are investigated. Experimental results demonstrate that the proposed SPP-CNN achieves better prediction performances and better generalizability to unknown datasets, with significantly lower time-consumption, than its counterparts.
CNN-based Prediction of Network Robustness With Missing Edges
Aug 25, 2022
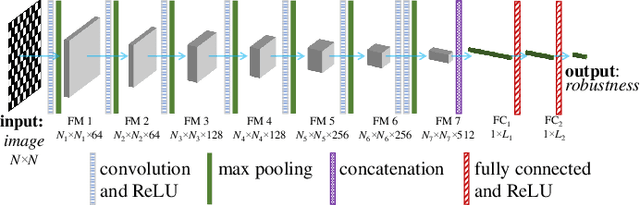
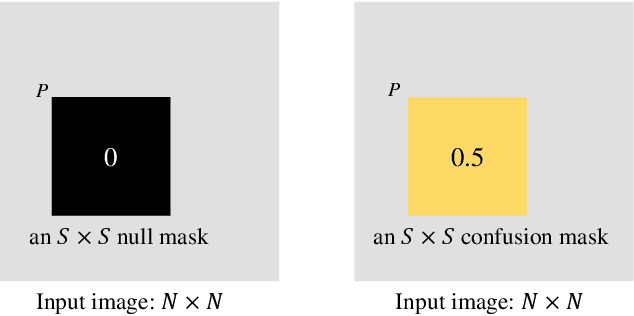
Connectivity and controllability of a complex network are two important issues that guarantee a networked system to function. Robustness of connectivity and controllability guarantees the system to function properly and stably under various malicious attacks. Evaluating network robustness using attack simulations is time consuming, while the convolutional neural network (CNN)-based prediction approach provides a cost-efficient method to approximate the network robustness. In this paper, we investigate the performance of CNN-based approaches for connectivity and controllability robustness prediction, when partial network information is missing, namely the adjacency matrix is incomplete. Extensive experimental studies are carried out. A threshold is explored that if a total amount of more than 7.29\% information is lost, the performance of CNN-based prediction will be significantly degenerated for all cases in the experiments. Two scenarios of missing edge representations are compared, 1) a missing edge is marked `no edge' in the input for prediction, and 2) a missing edge is denoted using a special marker of `unknown'. Experimental results reveal that the first representation is misleading to the CNN-based predictors.
A Learning Convolutional Neural Network Approach for Network Robustness Prediction
Mar 20, 2022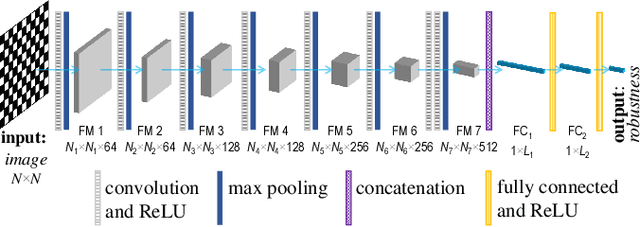
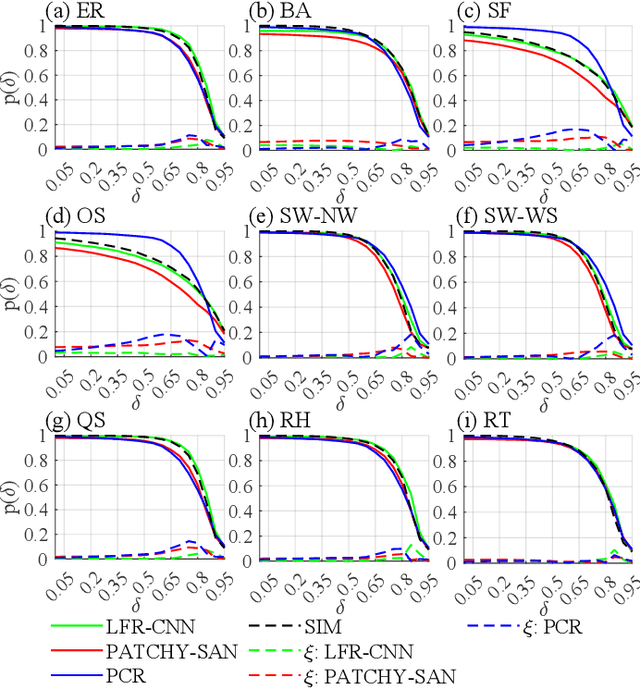
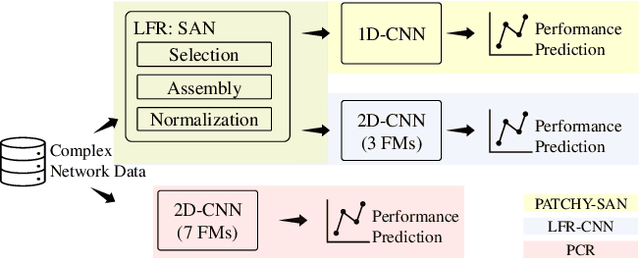
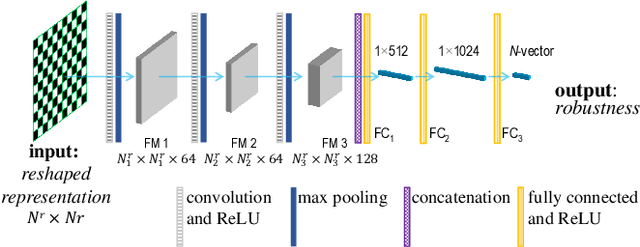
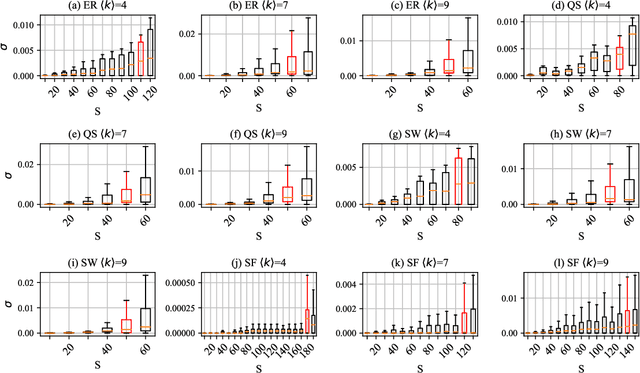
Network robustness is critical for various societal and industrial networks again malicious attacks. In particular, connectivity robustness and controllability robustness reflect how well a networked system can maintain its connectedness and controllability against destructive attacks, which can be quantified by a sequence of values that record the remaining connectivity and controllability of the network after a sequence of node- or edge-removal attacks. Traditionally, robustness is determined by attack simulations, which are computationally very time-consuming or even practically infeasible. In this paper, an improved method for network robustness prediction is developed based on learning feature representation using convolutional neural network (LFR-CNN). In this scheme, higher-dimensional network data are compressed to lower-dimensional representations, and then passed to a CNN to perform robustness prediction. Extensive experimental studies on both synthetic and real-world networks, both directed and undirected, demonstrate that 1) the proposed LFR-CNN performs better than other two state-of-the-art prediction methods, with significantly lower prediction errors; 2) LFR-CNN is insensitive to the variation of the network size, which significantly extends its applicability; 3) although LFR-CNN needs more time to perform feature learning, it can achieve accurate prediction faster than attack simulations; 4) LFR-CNN not only can accurately predict network robustness, but also provides a good indicator for connectivity robustness, better than the classical spectral measures.
Evaluating Adversarial Attacks on Driving Safety in Vision-Based Autonomous Vehicles
Aug 06, 2021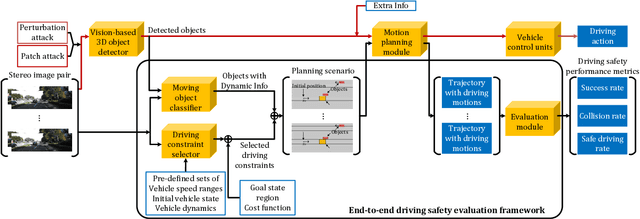

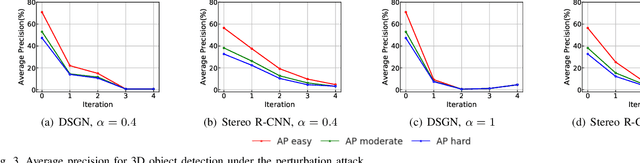
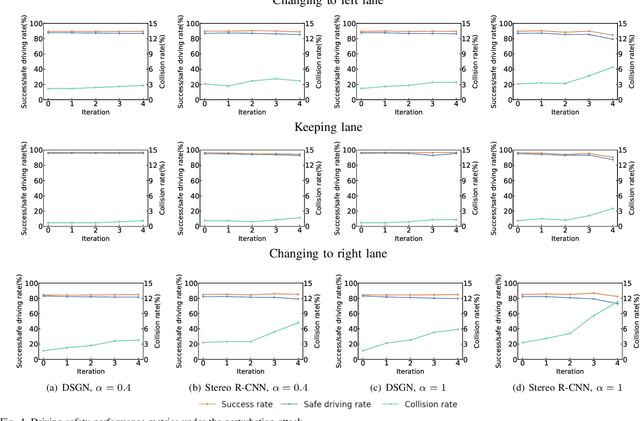
In recent years, many deep learning models have been adopted in autonomous driving. At the same time, these models introduce new vulnerabilities that may compromise the safety of autonomous vehicles. Specifically, recent studies have demonstrated that adversarial attacks can cause a significant decline in detection precision of deep learning-based 3D object detection models. Although driving safety is the ultimate concern for autonomous driving, there is no comprehensive study on the linkage between the performance of deep learning models and the driving safety of autonomous vehicles under adversarial attacks. In this paper, we investigate the impact of two primary types of adversarial attacks, perturbation attacks and patch attacks, on the driving safety of vision-based autonomous vehicles rather than the detection precision of deep learning models. In particular, we consider two state-of-the-art models in vision-based 3D object detection, Stereo R-CNN and DSGN. To evaluate driving safety, we propose an end-to-end evaluation framework with a set of driving safety performance metrics. By analyzing the results of our extensive evaluation experiments, we find that (1) the attack's impact on the driving safety of autonomous vehicles and the attack's impact on the precision of 3D object detectors are decoupled, and (2) the DSGN model demonstrates stronger robustness to adversarial attacks than the Stereo R-CNN model. In addition, we further investigate the causes behind the two findings with an ablation study. The findings of this paper provide a new perspective to evaluate adversarial attacks and guide the selection of deep learning models in autonomous driving.
Computing Cliques and Cavities in Networks
Jan 03, 2021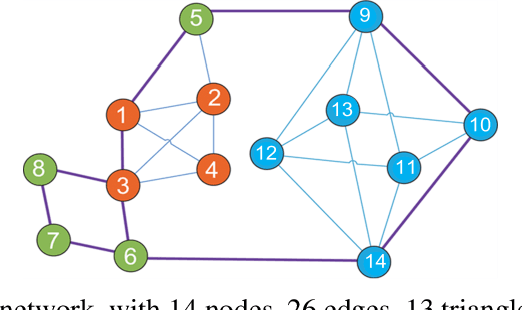

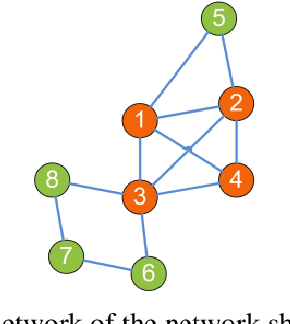
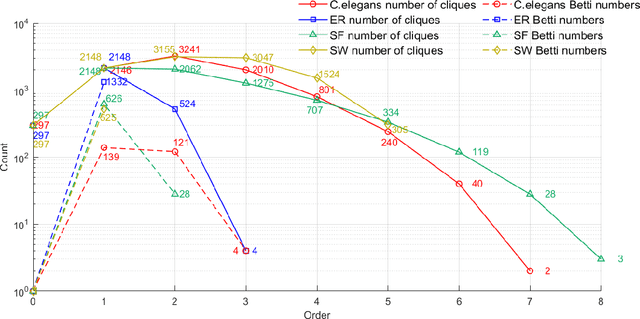
Complex networks have complete subgraphs such as nodes, edges, triangles, etc., referred to as cliques of different orders. Notably, cavities consisting of higher-order cliques have been found playing an important role in brain functions. Since searching for the maximum clique in a large network is an NP-complete problem, we propose using k-core decomposition to determine the computability of a given network subject to limited computing resources. For a computable network, we design a search algorithm for finding cliques of different orders, which also provides the Euler characteristic number. Then, we compute the Betti number by using the ranks of the boundary matrices of adjacent cliques. Furthermore, we design an optimized algorithm for finding cavities of different orders. Finally, we apply the algorithm to the neuronal network of C. elegans in one dataset, and find its all cliques and some cavities of different orders therein, providing a basis for further mathematical analysis and computation of the structure and function of the C. elegans neuronal network.
Predicting Network Controllability Robustness: A Convolutional Neural Network Approach
Aug 26, 2019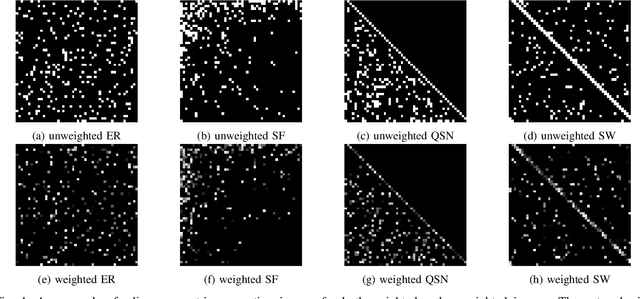
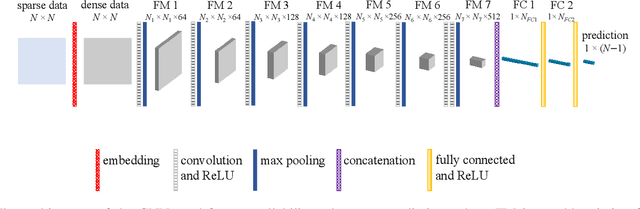
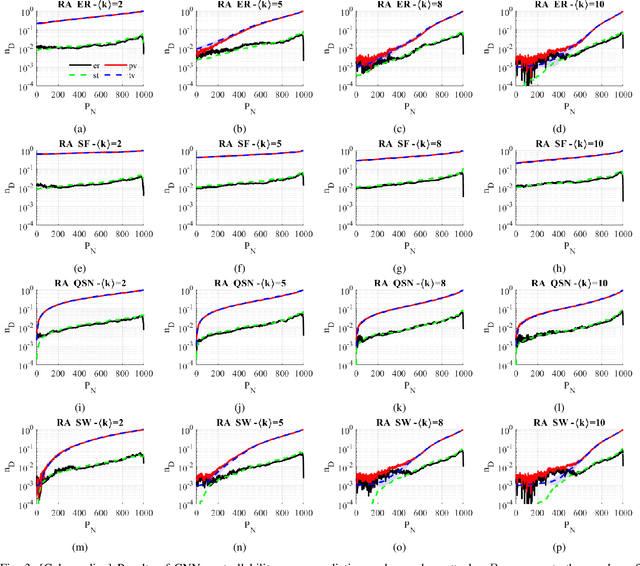
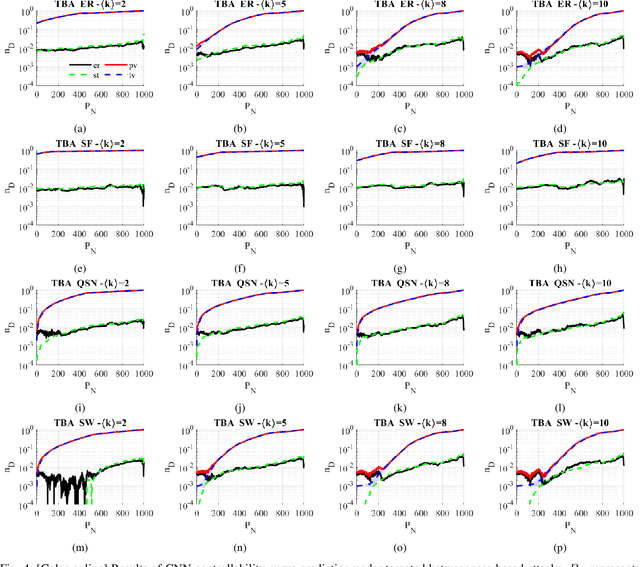
Network controllability measures how well a networked system can be controlled to a target state, and its robustness reflects how well the system can maintain the controllability against malicious attacks by means of node-removals or edge-removals. The measure of network controllability is quantified by the number of external control inputs needed to recover or to retain the controllability after the occurrence of an unexpected attack. The measure of the network controllability robustness, on the other hand, is quantified by a sequence of values that record the remaining controllability of the network after a sequence of attacks. Traditionally, the controllability robustness is determined by attack simulations, which is computationally time consuming. In this paper, a method to predict the controllability robustness based on machine learning using a convolutional neural network is proposed, motivated by the observations that 1) there is no clear correlation between the topological features and the controllability robustness of a general network, 2) the adjacency matrix of a network can be regarded as a gray-scale image, and 3) the convolutional neural network technique has proved successful in image processing without human intervention. Under the new framework, a fairly large number of training data generated by simulations are used to train a convolutional neural network for predicting the controllability robustness according to the input network-adjacency matrices, without performing conventional attack simulations. Extensive experimental studies were carried out, which demonstrate that the proposed framework for predicting controllability robustness of different network configurations is accurate and reliable with very low overheads.