 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication-Efficient Verifiable Attention for LLM Inference
Jun 15, 2026Computation integrity of remote large language model (LLM) serving can be questionable. For conventional deep neural networks (DNNs), the existing TEE-shielded DNN partitioning (TSDP) approach uses Trusted Execution Environment (TEE) to compute non-linear components and verify the integrity of linear components offloaded to an untrusted GPU. However, directly applying TSDP to Transformer-based LLMs incurs significant TEE computation and TEE-GPU communication overhead. This paper presents Communication-efficient TEE-GPU Attention (\textsc{VeriAttn}) for accelerating verifiable LLM inference. \textsc{VeriAttn} offloads both linear and non-linear computations of attention to the GPU, while TEE performs verification. Moreover, for prefill, \textsc{VeriAttn} uses a two-level pipeline to overlap data movement, TEE pre-/post-processing, and GPU computation. For decoding, when the key-value cache exceeds available GPU memory, \textsc{VeriAttn} partitions attention across TEE and GPU to reduce repeated key-value transfers. Evaluation on an Intel TDX platform shows that \textsc{VeriAttn} achieves 2.60-3.38$\times$ and 3.86-5.42$\times$ acceleration over TSDP for 6k-token prompts and 10k-token outputs during prefill and decoding, respectively.
DCoPilot: Generative AI-Empowered Policy Adaptation for Dynamic Data Center Operations
Feb 03, 2026Modern data centers (DCs) hosting artificial intelligence (AI)-dedicated devices operate at high power densities with rapidly varying workloads, making minute-level adaptation essential for safe and energy-efficient operation. However, manually designing piecewise deep reinforcement learning (DRL) agents cannot keep pace with frequent dynamics shifts and service-level agreement (SLA) changes of an evolving DC. This specification-to-policy lag causes a lack of timely, effective control policies, which may lead to service outages. To bridge the gap, we present DCoPilot, a hybrid framework for generative control policies in dynamic DC operation. DCoPilot synergizes two distinct generative paradigms, i.e., a large language model (LLM) that performs symbolic generation of structured reward forms, and a hypernetwork that conducts parametric generation of policy weights. DCoPilot operates through three coordinated phases: (i) simulation scale-up, which stress-tests reward candidates across diverse simulation-ready (SimReady) scenes; (ii) meta policy distillation, where a hypernetwork is trained to output policy weights conditioned on SLA and scene embeddings; and (iii) online adaptation, enabling zero-shot policy generation in response to updated specifications. Evaluated across five control task families spanning diverse DC components, DCoPilot achieves near-zero constraint violations and outperforms all baselines across specification variations. Ablation studies validate the effectiveness of LLM-based unified reward generation in enabling stable hypernetwork convergence.
Phythesis: Physics-Guided Evolutionary Scene Synthesis for Energy-Efficient Data Center Design via LLMs
Dec 15, 2025Data center (DC) infrastructure serves as the backbone to support the escalating demand for computing capacity. Traditional design methodologies that blend human expertise with specialized simulation tools scale poorly with the increasing system complexity. Recent studies adopt generative artificial intelligence to design plausible human-centric indoor layouts. However, they do not consider the underlying physics, making them unsuitable for the DC design that sets quantifiable operational objectives and strict physical constraints. To bridge the gap, we propose Phythesis, a novel framework that synergizes large language models (LLMs) and physics-guided evolutionary optimization to automate simulation-ready (SimReady) scene synthesis for energy-efficient DC design. Phythesis employs an iterative bi-level optimization architecture, where (i) the LLM-driven optimization level generates physically plausible three-dimensional layouts and self-criticizes them to refine the scene topology, and (ii) the physics-informed optimization level identifies the optimal asset parameters and selects the best asset combination. Experiments on three generation scales show that Phythesis achieves 57.3% generation success rate increase and 11.5% power usage effectiveness (PUE) improvement, compared with the vanilla LLM-based solution.
Toward Physics-Informed Machine Learning for Data Center Operations: A Tropical Case Study
May 26, 2025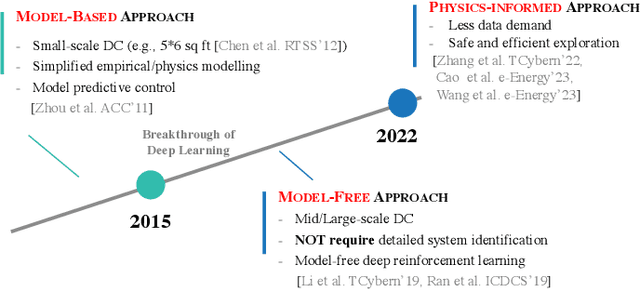
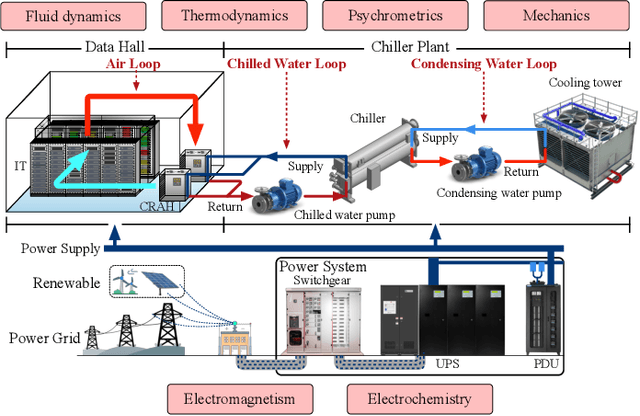
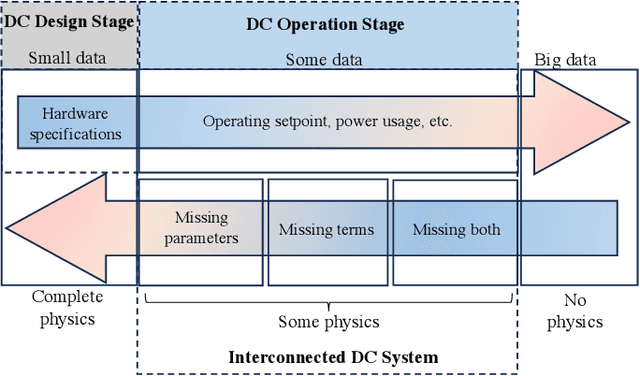
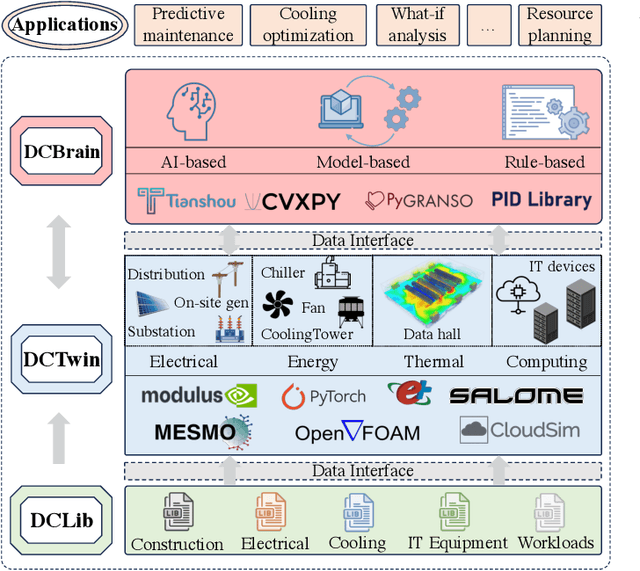
Data centers are the backbone of computing capacity. Operating data centers in the tropical regions faces unique challenges due to consistently high ambient temperature and elevated relative humidity throughout the year. These conditions result in increased cooling costs to maintain the reliability of the computing systems. While existing machine learning-based approaches have demonstrated potential to elevate operations to a more proactive and intelligent level, their deployment remains dubious due to concerns about model extrapolation capabilities and associated system safety issues. To address these concerns, this article proposes incorporating the physical characteristics of data centers into traditional data-driven machine learning solutions. We begin by introducing the data center system, including the relevant multiphysics processes and the data-physics availability. Next, we outline the associated modeling and optimization problems and propose an integrated, physics-informed machine learning system to address them. Using the proposed system, we present relevant applications across varying levels of operational intelligence. A case study on an industry-grade tropical data center is provided to demonstrate the effectiveness of our approach. Finally, we discuss key challenges and highlight potential future directions.
Advancing Mobile GUI Agents: A Verifier-Driven Approach to Practical Deployment
Mar 21, 2025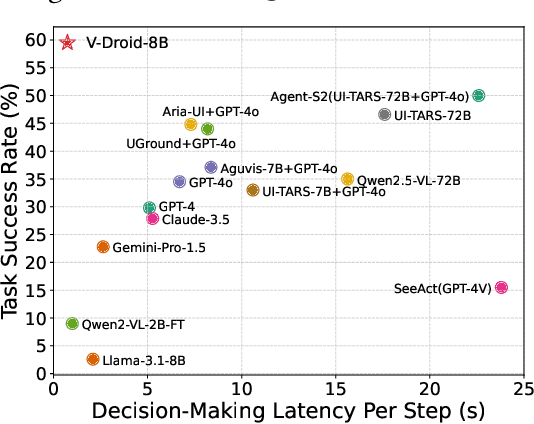
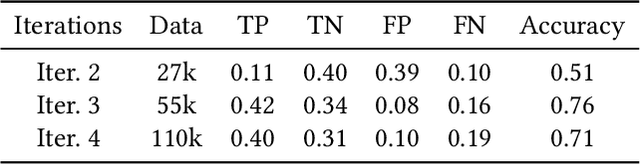
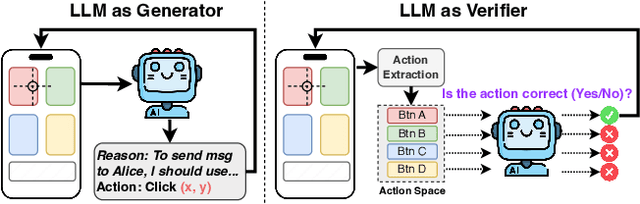
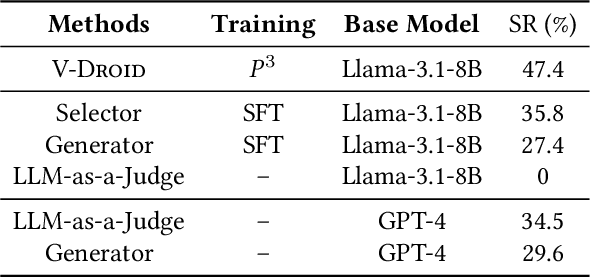
We propose V-Droid, a mobile GUI task automation agent. Unlike previous mobile agents that utilize Large Language Models (LLMs) as generators to directly generate actions at each step, V-Droid employs LLMs as verifiers to evaluate candidate actions before making final decisions. To realize this novel paradigm, we introduce a comprehensive framework for constructing verifier-driven mobile agents: the discretized action space construction coupled with the prefilling-only workflow to accelerate the verification process, the pair-wise progress preference training to significantly enhance the verifier's decision-making capabilities, and the scalable human-agent joint annotation scheme to efficiently collect the necessary data at scale. V-Droid sets a new state-of-the-art task success rate across several public mobile task automation benchmarks: 59.5% on AndroidWorld, 38.3% on AndroidLab, and 49% on MobileAgentBench, surpassing existing agents by 9.5%, 2.1%, and 9%, respectively. Furthermore, V-Droid achieves an impressively low latency of 0.7 seconds per step, making it the first mobile agent capable of delivering near-real-time, effective decision-making capabilities.
Expanding Deep Learning-based Sensing Systems with Multi-Source Knowledge Transfer
Dec 05, 2024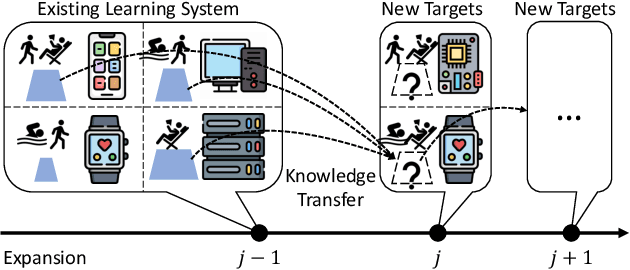
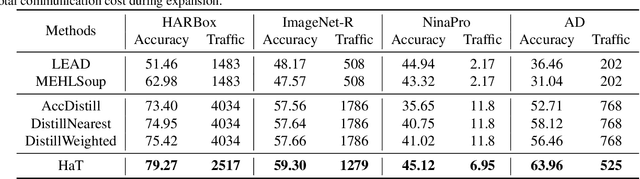
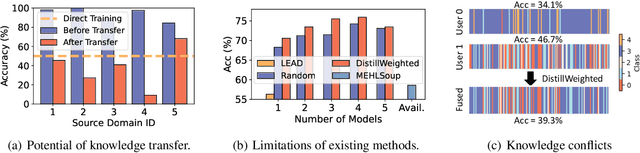
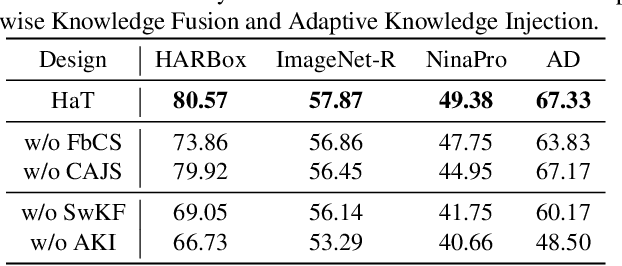
Expanding the existing sensing systems to provide high-quality deep learning models for more domains, such as new users or environments, is challenged by the limited labeled data and the data and device heterogeneities. While knowledge distillation methods could overcome label scarcity and device heterogeneity, they assume the teachers are fully reliable and overlook the data heterogeneity, which prevents the direct adoption of existing models. To address this problem, this paper proposes an efficient knowledge transfer framework, HaKT, to expand sensing systems. It first selects multiple high-quality models from the system at a low cost and then fuses their knowledge by assigning sample-wise weights to their predictions. Later, the fused knowledge is selectively injected into the customized models for new domains based on the knowledge quality. Extensive experiments on different tasks, modalities, and settings show that HaKT outperforms stat-of-the-art baselines by at most 16.5% accuracy and saves up to 39% communication traffic.
Invisible Optical Adversarial Stripes on Traffic Sign against Autonomous Vehicles
Jul 10, 2024



Camera-based computer vision is essential to autonomous vehicle's perception. This paper presents an attack that uses light-emitting diodes and exploits the camera's rolling shutter effect to create adversarial stripes in the captured images to mislead traffic sign recognition. The attack is stealthy because the stripes on the traffic sign are invisible to human. For the attack to be threatening, the recognition results need to be stable over consecutive image frames. To achieve this, we design and implement GhostStripe, an attack system that controls the timing of the modulated light emission to adapt to camera operations and victim vehicle movements. Evaluated on real testbeds, GhostStripe can stably spoof the traffic sign recognition results for up to 94\% of frames to a wrong class when the victim vehicle passes the road section. In reality, such attack effect may fool victim vehicles into life-threatening incidents. We discuss the countermeasures at the levels of camera sensor, perception model, and autonomous driving system.
A First Physical-World Trajectory Prediction Attack via LiDAR-induced Deceptions in Autonomous Driving
Jun 17, 2024



Trajectory prediction forecasts nearby agents' moves based on their historical trajectories. Accurate trajectory prediction is crucial for autonomous vehicles. Existing attacks compromise the prediction model of a victim AV by directly manipulating the historical trajectory of an attacker AV, which has limited real-world applicability. This paper, for the first time, explores an indirect attack approach that induces prediction errors via attacks against the perception module of a victim AV. Although it has been shown that physically realizable attacks against LiDAR-based perception are possible by placing a few objects at strategic locations, it is still an open challenge to find an object location from the vast search space in order to launch effective attacks against prediction under varying victim AV velocities. Through analysis, we observe that a prediction model is prone to an attack focusing on a single point in the scene. Consequently, we propose a novel two-stage attack framework to realize the single-point attack. The first stage of prediction-side attack efficiently identifies, guided by the distribution of detection results under object-based attacks against perception, the state perturbations for the prediction model that are effective and velocity-insensitive. In the second stage of location matching, we match the feasible object locations with the found state perturbations. Our evaluation using a public autonomous driving dataset shows that our attack causes a collision rate of up to 63% and various hazardous responses of the victim AV. The effectiveness of our attack is also demonstrated on a real testbed car. To the best of our knowledge, this study is the first security analysis spanning from LiDAR-based perception to prediction in autonomous driving, leading to a realistic attack on prediction. To counteract the proposed attack, potential defenses are discussed.
MESEN: Exploit Multimodal Data to Design Unimodal Human Activity Recognition with Few Labels
Apr 02, 2024Human activity recognition (HAR) will be an essential function of various emerging applications. However, HAR typically encounters challenges related to modality limitations and label scarcity, leading to an application gap between current solutions and real-world requirements. In this work, we propose MESEN, a multimodal-empowered unimodal sensing framework, to utilize unlabeled multimodal data available during the HAR model design phase for unimodal HAR enhancement during the deployment phase. From a study on the impact of supervised multimodal fusion on unimodal feature extraction, MESEN is designed to feature a multi-task mechanism during the multimodal-aided pre-training stage. With the proposed mechanism integrating cross-modal feature contrastive learning and multimodal pseudo-classification aligning, MESEN exploits unlabeled multimodal data to extract effective unimodal features for each modality. Subsequently, MESEN can adapt to downstream unimodal HAR with only a few labeled samples. Extensive experiments on eight public multimodal datasets demonstrate that MESEN achieves significant performance improvements over state-of-the-art baselines in enhancing unimodal HAR by exploiting multimodal data.
Knowledge-aware Alert Aggregation in Large-scale Cloud Systems: a Hybrid Approach
Mar 11, 2024Due to the scale and complexity of cloud systems, a system failure would trigger an "alert storm", i.e., massive correlated alerts. Although these alerts can be traced back to a few root causes, the overwhelming number makes it infeasible for manual handling. Alert aggregation is thus critical to help engineers concentrate on the root cause and facilitate failure resolution. Existing methods typically utilize semantic similarity-based methods or statistical methods to aggregate alerts. However, semantic similarity-based methods overlook the causal rationale of alerts, while statistical methods can hardly handle infrequent alerts. To tackle these limitations, we introduce leveraging external knowledge, i.e., Standard Operation Procedure (SOP) of alerts as a supplement. We propose COLA, a novel hybrid approach based on correlation mining and LLM (Large Language Model) reasoning for online alert aggregation. The correlation mining module effectively captures the temporal and spatial relations between alerts, measuring their correlations in an efficient manner. Subsequently, only uncertain pairs with low confidence are forwarded to the LLM reasoning module for detailed analysis. This hybrid design harnesses both statistical evidence for frequent alerts and the reasoning capabilities of computationally intensive LLMs, ensuring the overall efficiency of COLA in handling large volumes of alerts in practical scenarios. We evaluate COLA on three datasets collected from the production environment of a large-scale cloud platform. The experimental results show COLA achieves F1-scores from 0.901 to 0.930, outperforming state-of-the-art methods and achieving comparable efficiency. We also share our experience in deploying COLA in our real-world cloud system, Cloud X.