 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNVIDIA Nemotron Nano V2 VL
Nov 07, 2025We introduce Nemotron Nano V2 VL, the latest model of the Nemotron vision-language series designed for strong real-world document understanding, long video comprehension, and reasoning tasks. Nemotron Nano V2 VL delivers significant improvements over our previous model, Llama-3.1-Nemotron-Nano-VL-8B, across all vision and text domains through major enhancements in model architecture, datasets, and training recipes. Nemotron Nano V2 VL builds on Nemotron Nano V2, a hybrid Mamba-Transformer LLM, and innovative token reduction techniques to achieve higher inference throughput in long document and video scenarios. We are releasing model checkpoints in BF16, FP8, and FP4 formats and sharing large parts of our datasets, recipes and training code.
Llama-Nemotron: Efficient Reasoning Models
May 02, 2025



We introduce the Llama-Nemotron series of models, an open family of heterogeneous reasoning models that deliver exceptional reasoning capabilities, inference efficiency, and an open license for enterprise use. The family comes in three sizes -- Nano (8B), Super (49B), and Ultra (253B) -- and performs competitively with state-of-the-art reasoning models such as DeepSeek-R1 while offering superior inference throughput and memory efficiency. In this report, we discuss the training procedure for these models, which entails using neural architecture search from Llama 3 models for accelerated inference, knowledge distillation, and continued pretraining, followed by a reasoning-focused post-training stage consisting of two main parts: supervised fine-tuning and large scale reinforcement learning. Llama-Nemotron models are the first open-source models to support a dynamic reasoning toggle, allowing users to switch between standard chat and reasoning modes during inference. To further support open research and facilitate model development, we provide the following resources: 1. We release the Llama-Nemotron reasoning models -- LN-Nano, LN-Super, and LN-Ultra -- under the commercially permissive NVIDIA Open Model License Agreement. 2. We release the complete post-training dataset: Llama-Nemotron-Post-Training-Dataset. 3. We also release our training codebases: NeMo, NeMo-Aligner, and Megatron-LM.
CognTKE: A Cognitive Temporal Knowledge Extrapolation Framework
Dec 21, 2024



Reasoning future unknowable facts on temporal knowledge graphs (TKGs) is a challenging task, holding significant academic and practical values for various fields. Existing studies exploring explainable reasoning concentrate on modeling comprehensible temporal paths relevant to the query. Yet, these path-based methods primarily focus on local temporal paths appearing in recent times, failing to capture the complex temporal paths in TKG and resulting in the loss of longer historical relations related to the query. Motivated by the Dual Process Theory in cognitive science, we propose a \textbf{Cogn}itive \textbf{T}emporal \textbf{K}nowledge \textbf{E}xtrapolation framework (CognTKE), which introduces a novel temporal cognitive relation directed graph (TCR-Digraph) and performs interpretable global shallow reasoning and local deep reasoning over the TCR-Digraph. Specifically, the proposed TCR-Digraph is constituted by retrieving significant local and global historical temporal relation paths associated with the query. In addition, CognTKE presents the global shallow reasoner and the local deep reasoner to perform global one-hop temporal relation reasoning (System 1) and local complex multi-hop path reasoning (System 2) over the TCR-Digraph, respectively. The experimental results on four benchmark datasets demonstrate that CognTKE achieves significant improvement in accuracy compared to the state-of-the-art baselines and delivers excellent zero-shot reasoning ability. \textit{The code is available at https://github.com/WeiChen3690/CognTKE}.
Enhancing the Reasoning Capabilities of Small Language Models via Solution Guidance Fine-Tuning
Dec 13, 2024

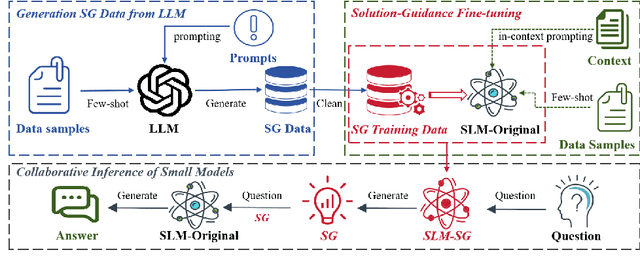
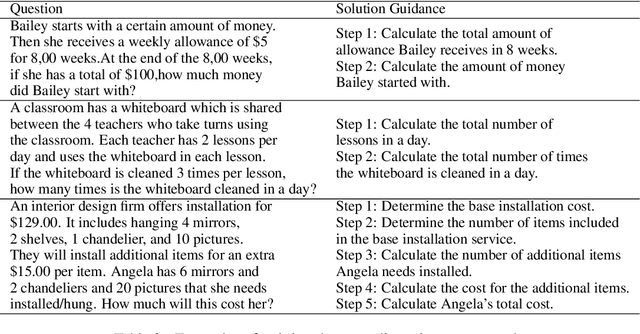
Large language models (LLMs) have demonstrated remarkable performance across a wide range of tasks. Advances in prompt engineering and fine-tuning techniques have further enhanced their ability to address complex reasoning challenges. However, these advanced capabilities are often exclusive to models exceeding 100 billion parameters. Although Chain-of-Thought (CoT) fine-tuning methods have been explored for smaller models (under 10 billion parameters), they typically depend on extensive CoT training data, which can introduce inconsistencies and limit effectiveness in low-data settings. To overcome these limitations, this paper introduce a new reasoning strategy Solution Guidance (SG) and a plug-and-play training paradigm Solution-Guidance Fine-Tuning (SGFT) for enhancing the reasoning capabilities of small language models. SG focuses on problem understanding and decomposition at the semantic and logical levels, rather than specific computations, which can effectively improve the SLMs' generalization and reasoning abilities. With only a small amount of SG training data, SGFT can fine-tune a SLM to produce accurate problem-solving guidances, which can then be flexibly fed to any SLM as prompts, enabling it to generate correct answers directly. Experimental results demonstrate that our method significantly improves the performance of SLMs on various reasoning tasks, enhancing both their practicality and efficiency within resource-constrained environments.
Invisible Optical Adversarial Stripes on Traffic Sign against Autonomous Vehicles
Jul 10, 2024



Camera-based computer vision is essential to autonomous vehicle's perception. This paper presents an attack that uses light-emitting diodes and exploits the camera's rolling shutter effect to create adversarial stripes in the captured images to mislead traffic sign recognition. The attack is stealthy because the stripes on the traffic sign are invisible to human. For the attack to be threatening, the recognition results need to be stable over consecutive image frames. To achieve this, we design and implement GhostStripe, an attack system that controls the timing of the modulated light emission to adapt to camera operations and victim vehicle movements. Evaluated on real testbeds, GhostStripe can stably spoof the traffic sign recognition results for up to 94\% of frames to a wrong class when the victim vehicle passes the road section. In reality, such attack effect may fool victim vehicles into life-threatening incidents. We discuss the countermeasures at the levels of camera sensor, perception model, and autonomous driving system.
Local-Global History-aware Contrastive Learning for Temporal Knowledge Graph Reasoning
Dec 04, 2023



Temporal knowledge graphs (TKGs) have been identified as a promising approach to represent the dynamics of facts along the timeline. The extrapolation of TKG is to predict unknowable facts happening in the future, holding significant practical value across diverse fields. Most extrapolation studies in TKGs focus on modeling global historical fact repeating and cyclic patterns, as well as local historical adjacent fact evolution patterns, showing promising performance in predicting future unknown facts. Yet, existing methods still face two major challenges: (1) They usually neglect the importance of historical information in KG snapshots related to the queries when encoding the local and global historical information; (2) They exhibit weak anti-noise capabilities, which hinders their performance when the inputs are contaminated with noise.To this end, we propose a novel \blue{Lo}cal-\blue{g}lobal history-aware \blue{C}ontrastive \blue{L}earning model (\blue{LogCL}) for TKG reasoning, which adopts contrastive learning to better guide the fusion of local and global historical information and enhance the ability to resist interference. Specifically, for the first challenge, LogCL proposes an entity-aware attention mechanism applied to the local and global historical facts encoder, which captures the key historical information related to queries. For the latter issue, LogCL designs four historical query contrast patterns, effectively improving the robustness of the model. The experimental results on four benchmark datasets demonstrate that LogCL delivers better and more robust performance than the state-of-the-art baselines.
Towards Enhancing Relational Rules for Knowledge Graph Link Prediction
Oct 20, 2023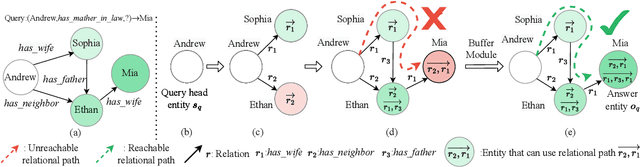
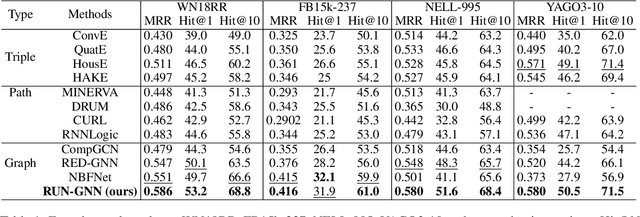
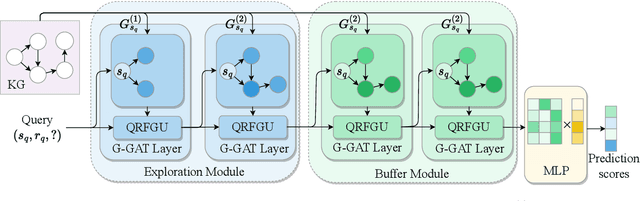
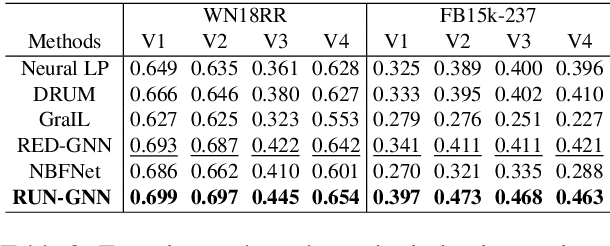
Graph neural networks (GNNs) have shown promising performance for knowledge graph reasoning. A recent variant of GNN called progressive relational graph neural network (PRGNN), utilizes relational rules to infer missing knowledge in relational digraphs and achieves notable results. However, during reasoning with PRGNN, two important properties are often overlooked: (1) the sequentiality of relation composition, where the order of combining different relations affects the semantics of the relational rules, and (2) the lagged entity information propagation, where the transmission speed of required information lags behind the appearance speed of new entities. Ignoring these properties leads to incorrect relational rule learning and decreased reasoning accuracy. To address these issues, we propose a novel knowledge graph reasoning approach, the Relational rUle eNhanced Graph Neural Network (RUN-GNN). Specifically, RUN-GNN employs a query related fusion gate unit to model the sequentiality of relation composition and utilizes a buffering update mechanism to alleviate the negative effect of lagged entity information propagation, resulting in higher-quality relational rule learning. Experimental results on multiple datasets demonstrate the superiority of RUN-GNN is superior on both transductive and inductive link prediction tasks.
Bulk-Switching Memristor-based Compute-In-Memory Module for Deep Neural Network Training
May 23, 2023The need for deep neural network (DNN) models with higher performance and better functionality leads to the proliferation of very large models. Model training, however, requires intensive computation time and energy. Memristor-based compute-in-memory (CIM) modules can perform vector-matrix multiplication (VMM) in situ and in parallel, and have shown great promises in DNN inference applications. However, CIM-based model training faces challenges due to non-linear weight updates, device variations, and low-precision in analog computing circuits. In this work, we experimentally implement a mixed-precision training scheme to mitigate these effects using a bulk-switching memristor CIM module. Lowprecision CIM modules are used to accelerate the expensive VMM operations, with high precision weight updates accumulated in digital units. Memristor devices are only changed when the accumulated weight update value exceeds a pre-defined threshold. The proposed scheme is implemented with a system-on-chip (SoC) of fully integrated analog CIM modules and digital sub-systems, showing fast convergence of LeNet training to 97.73%. The efficacy of training larger models is evaluated using realistic hardware parameters and shows that that analog CIM modules can enable efficient mix-precision DNN training with accuracy comparable to full-precision software trained models. Additionally, models trained on chip are inherently robust to hardware variations, allowing direct mapping to CIM inference chips without additional re-training.
PowerGAN: A Machine Learning Approach for Power Side-Channel Attack on Compute-in-Memory Accelerators
Apr 13, 2023Analog compute-in-memory (CIM) accelerators are becoming increasingly popular for deep neural network (DNN) inference due to their energy efficiency and in-situ vector-matrix multiplication (VMM) capabilities. However, as the use of DNNs expands, protecting user input privacy has become increasingly important. In this paper, we identify a security vulnerability wherein an adversary can reconstruct the user's private input data from a power side-channel attack, under proper data acquisition and pre-processing, even without knowledge of the DNN model. We further demonstrate a machine learning-based attack approach using a generative adversarial network (GAN) to enhance the reconstruction. Our results show that the attack methodology is effective in reconstructing user inputs from analog CIM accelerator power leakage, even when at large noise levels and countermeasures are applied. Specifically, we demonstrate the efficacy of our approach on the U-Net for brain tumor detection in magnetic resonance imaging (MRI) medical images, with a noise-level of 20% standard deviation of the maximum power signal value. Our study highlights a significant security vulnerability in analog CIM accelerators and proposes an effective attack methodology using a GAN to breach user privacy.
Hand Gestures Recognition in Videos Taken with Lensless Camera
Oct 15, 2022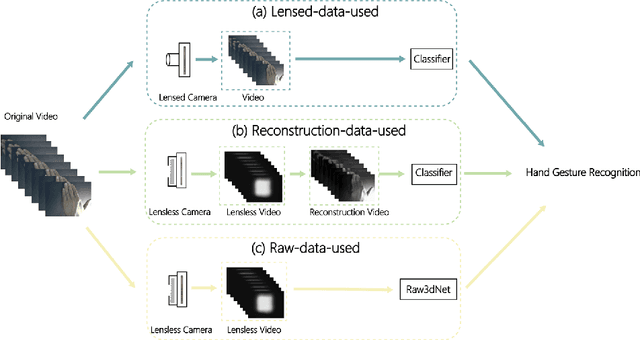
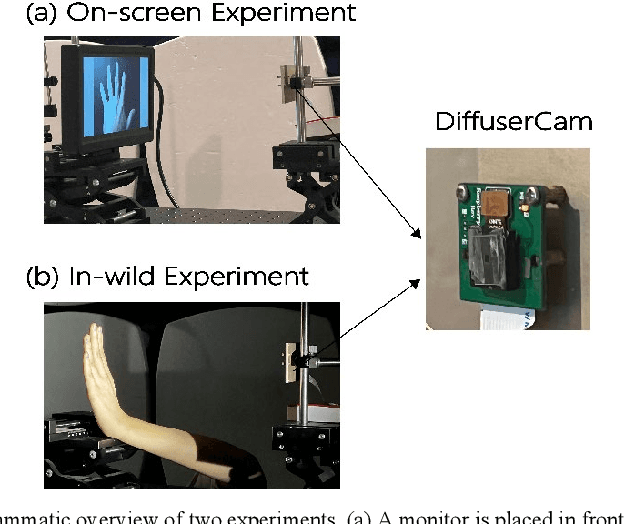

A lensless camera is an imaging system that uses a mask in place of a lens, making it thinner, lighter, and less expensive than a lensed camera. However, additional complex computation and time are required for image reconstruction. This work proposes a deep learning model named Raw3dNet that recognizes hand gestures directly on raw videos captured by a lensless camera without the need for image restoration. In addition to conserving computational resources, the reconstruction-free method provides privacy protection. Raw3dNet is a novel end-to-end deep neural network model for the recognition of hand gestures in lensless imaging systems. It is created specifically for raw video captured by a lensless camera and has the ability to properly extract and combine temporal and spatial features. The network is composed of two stages: 1. spatial feature extractor (SFE), which enhances the spatial features of each frame prior to temporal convolution; 2. 3D-ResNet, which implements spatial and temporal convolution of video streams. The proposed model achieves 98.59% accuracy on the Cambridge Hand Gesture dataset in the lensless optical experiment, which is comparable to the lensed-camera result. Additionally, the feasibility of physical object recognition is assessed. Furtherly, we show that the recognition can be achieved with respectable accuracy using only a tiny portion of the original raw data, indicating the potential for reducing data traffic in cloud computing scenarios.