 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText detection and recognition based on a lensless imaging system
Paper and Code
Oct 09, 2022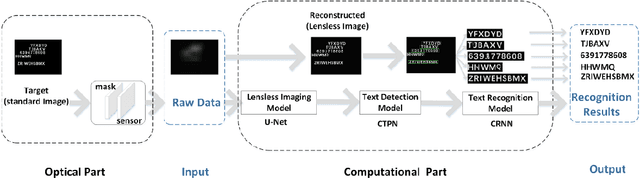
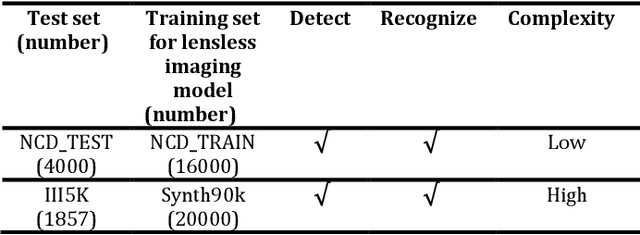
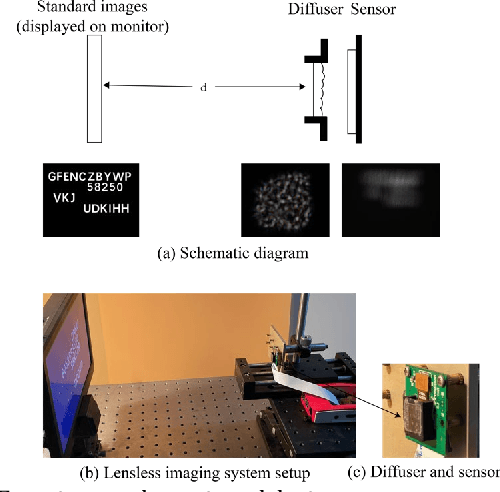
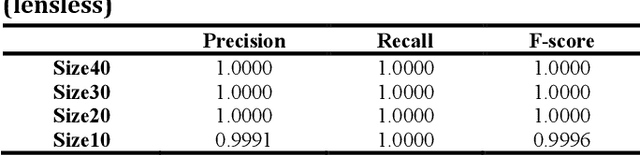
Lensless cameras are characterized by several advantages (e.g., miniaturization, ease of manufacture, and low cost) as compared with conventional cameras. However, they have not been extensively employed due to their poor image clarity and low image resolution, especially for tasks that have high requirements on image quality and details such as text detection and text recognition. To address the problem, a framework of deep-learning-based pipeline structure was built to recognize text with three steps from raw data captured by employing lensless cameras. This pipeline structure consisted of the lensless imaging model U-Net, the text detection model connectionist text proposal network (CTPN), and the text recognition model convolutional recurrent neural network (CRNN). Compared with the method focusing only on image reconstruction, UNet in the pipeline was able to supplement the imaging details by enhancing factors related to character categories in the reconstruction process, so the textual information can be more effectively detected and recognized by CTPN and CRNN with fewer artifacts and high-clarity reconstructed lensless images. By performing experiments on datasets of different complexities, the applicability to text detection and recognition on lensless cameras was verified. This study reasonably demonstrates text detection and recognition tasks in the lensless camera system,and develops a basic method for novel applications.