 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOccuBench: Evaluating AI Agents on Real-World Professional Tasks via Language World Models
Apr 13, 2026AI agents are expected to perform professional work across hundreds of occupational domains (from emergency department triage to nuclear reactor safety monitoring to customs import processing), yet existing benchmarks can only evaluate agents in the few domains where public environments exist. We introduce OccuBench, a benchmark covering 100 real-world professional task scenarios across 10 industry categories and 65 specialized domains, enabled by Language World Models (LWMs) that simulate domain-specific environments through LLM-driven tool response generation. Our multi-agent synthesis pipeline automatically produces evaluation instances with guaranteed solvability, calibrated difficulty, and document-grounded diversity. OccuBench evaluates agents along two complementary dimensions: task completion across professional domains and environmental robustness under controlled fault injection (explicit errors, implicit data degradation, and mixed faults). We evaluate 15 frontier models across 8 model families and find that: (1) no single model dominates all industries, as each has a distinct occupational capability profile; (2) implicit faults (truncated data, missing fields) are harder than both explicit errors (timeouts, 500s) and mixed faults, because they lack overt error signals and require the agent to independently detect data degradation; (3) larger models, newer generations, and higher reasoning effort consistently improve performance. GPT-5.2 improves by 27.5 points from minimal to maximum reasoning effort; and (4) strong agents are not necessarily strong environment simulators. Simulator quality is critical for LWM-based evaluation reliability. OccuBench provides the first systematic cross-industry evaluation of AI agents on professional occupational tasks.
DeepPlanning: Benchmarking Long-Horizon Agentic Planning with Verifiable Constraints
Jan 26, 2026While agent evaluation has shifted toward long-horizon tasks, most benchmarks still emphasize local, step-level reasoning rather than the global constrained optimization (e.g., time and financial budgets) that demands genuine planning ability. Meanwhile, existing LLM planning benchmarks underrepresent the active information gathering and fine-grained local constraints typical of real-world settings. To address this, we introduce DeepPlanning, a challenging benchmark for practical long-horizon agent planning. It features multi-day travel planning and multi-product shopping tasks that require proactive information acquisition, local constrained reasoning, and global constrained optimization. Evaluations on DeepPlanning show that even frontier agentic LLMs struggle with these problems, highlighting the importance of reliable explicit reasoning patterns and parallel tool use for achieving better effectiveness-efficiency trade-offs. Error analysis further points to promising directions for improving agentic LLMs over long planning horizons. We open-source the code and data to support future research.
Qwen3 Technical Report
May 14, 2025



In this work, we present Qwen3, the latest version of the Qwen model family. Qwen3 comprises a series of large language models (LLMs) designed to advance performance, efficiency, and multilingual capabilities. The Qwen3 series includes models of both dense and Mixture-of-Expert (MoE) architectures, with parameter scales ranging from 0.6 to 235 billion. A key innovation in Qwen3 is the integration of thinking mode (for complex, multi-step reasoning) and non-thinking mode (for rapid, context-driven responses) into a unified framework. This eliminates the need to switch between different models--such as chat-optimized models (e.g., GPT-4o) and dedicated reasoning models (e.g., QwQ-32B)--and enables dynamic mode switching based on user queries or chat templates. Meanwhile, Qwen3 introduces a thinking budget mechanism, allowing users to allocate computational resources adaptively during inference, thereby balancing latency and performance based on task complexity. Moreover, by leveraging the knowledge from the flagship models, we significantly reduce the computational resources required to build smaller-scale models, while ensuring their highly competitive performance. Empirical evaluations demonstrate that Qwen3 achieves state-of-the-art results across diverse benchmarks, including tasks in code generation, mathematical reasoning, agent tasks, etc., competitive against larger MoE models and proprietary models. Compared to its predecessor Qwen2.5, Qwen3 expands multilingual support from 29 to 119 languages and dialects, enhancing global accessibility through improved cross-lingual understanding and generation capabilities. To facilitate reproducibility and community-driven research and development, all Qwen3 models are publicly accessible under Apache 2.0.
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Jun 19, 2024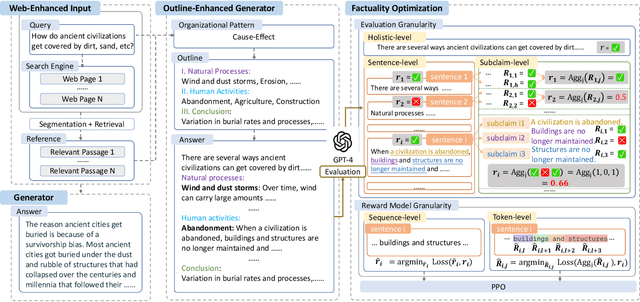
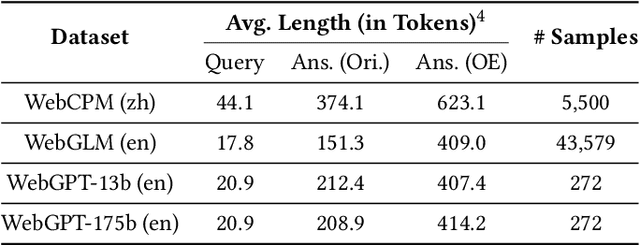

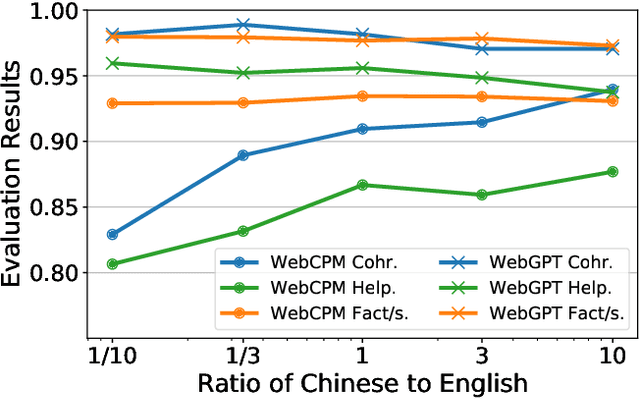
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed \textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.
MoDE: A Mixture-of-Experts Model with Mutual Distillation among the Experts
Jan 31, 2024The application of mixture-of-experts (MoE) is gaining popularity due to its ability to improve model's performance. In an MoE structure, the gate layer plays a significant role in distinguishing and routing input features to different experts. This enables each expert to specialize in processing their corresponding sub-tasks. However, the gate's routing mechanism also gives rise to narrow vision: the individual MoE's expert fails to use more samples in learning the allocated sub-task, which in turn limits the MoE to further improve its generalization ability. To effectively address this, we propose a method called Mixture-of-Distilled-Expert (MoDE), which applies moderate mutual distillation among experts to enable each expert to pick up more features learned by other experts and gain more accurate perceptions on their original allocated sub-tasks. We conduct plenty experiments including tabular, NLP and CV datasets, which shows MoDE's effectiveness, universality and robustness. Furthermore, we develop a parallel study through innovatively constructing "expert probing", to experimentally prove why MoDE works: moderate distilling knowledge can improve each individual expert's test performances on their assigned tasks, leading to MoE's overall performance improvement.
Reverse Chain: A Generic-Rule for LLMs to Master Multi-API Planning
Oct 10, 2023



While enabling large language models to implement function calling (known as APIs) can greatly enhance the performance of LLMs, function calling is still a challenging task due to the complicated relations between different APIs, especially in a context-learning setting without fine-tuning. This paper proposes a simple yet controllable target-driven approach called Reverse Chain to empower LLMs with capabilities to use external APIs with only prompts. Given that most open-source LLMs have limited tool-use or tool-plan capabilities, LLMs in Reverse Chain are only employed to implement simple tasks, e.g., API selection and argument completion, and a generic rule is employed to implement a controllable multiple functions calling. In this generic rule, after selecting a final API to handle a given task via LLMs, we first ask LLMs to fill the required arguments from user query and context. Some missing arguments could be further completed by letting LLMs select another API based on API description before asking user. This process continues until a given task is completed. Extensive numerical experiments indicate an impressive capability of Reverse Chain on implementing multiple function calling. Interestingly enough, the experiments also reveal that tool-use capabilities of the existing LLMs, e.g., ChatGPT, can be greatly improved via Reverse Chain.
Hand Gestures Recognition in Videos Taken with Lensless Camera
Oct 15, 2022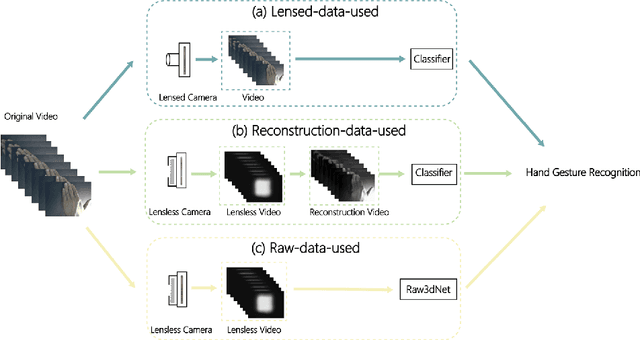
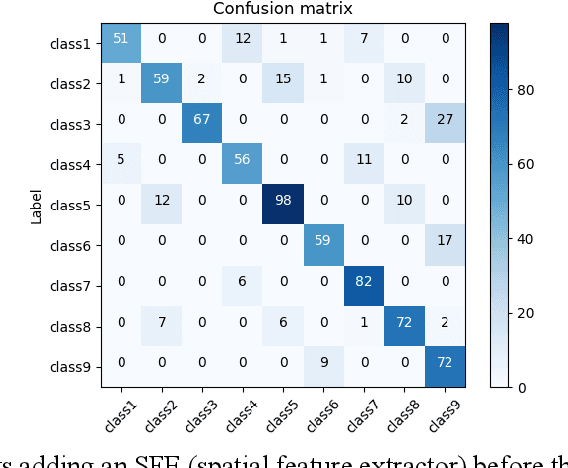
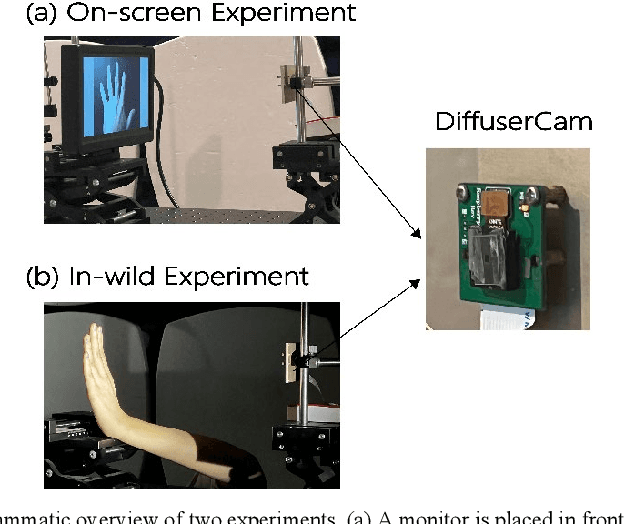

A lensless camera is an imaging system that uses a mask in place of a lens, making it thinner, lighter, and less expensive than a lensed camera. However, additional complex computation and time are required for image reconstruction. This work proposes a deep learning model named Raw3dNet that recognizes hand gestures directly on raw videos captured by a lensless camera without the need for image restoration. In addition to conserving computational resources, the reconstruction-free method provides privacy protection. Raw3dNet is a novel end-to-end deep neural network model for the recognition of hand gestures in lensless imaging systems. It is created specifically for raw video captured by a lensless camera and has the ability to properly extract and combine temporal and spatial features. The network is composed of two stages: 1. spatial feature extractor (SFE), which enhances the spatial features of each frame prior to temporal convolution; 2. 3D-ResNet, which implements spatial and temporal convolution of video streams. The proposed model achieves 98.59% accuracy on the Cambridge Hand Gesture dataset in the lensless optical experiment, which is comparable to the lensed-camera result. Additionally, the feasibility of physical object recognition is assessed. Furtherly, we show that the recognition can be achieved with respectable accuracy using only a tiny portion of the original raw data, indicating the potential for reducing data traffic in cloud computing scenarios.
Text detection and recognition based on a lensless imaging system
Oct 09, 2022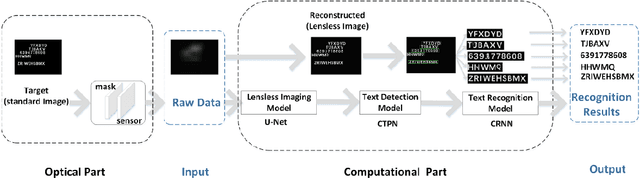
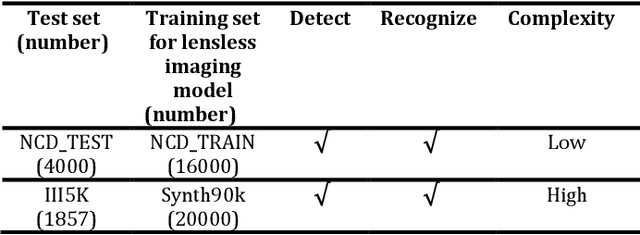
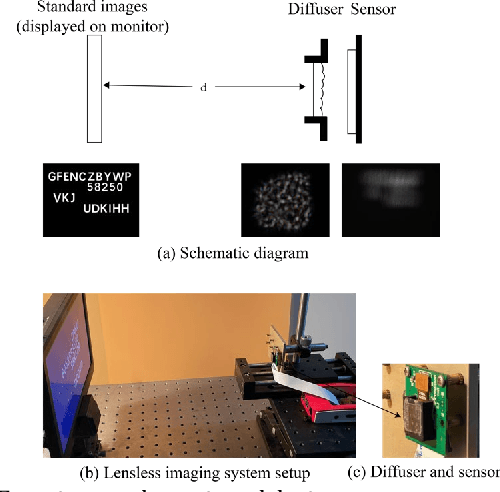
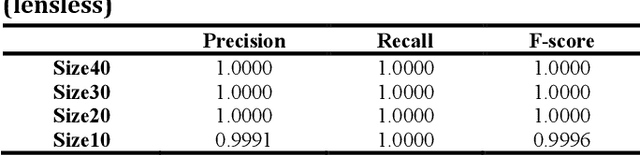
Lensless cameras are characterized by several advantages (e.g., miniaturization, ease of manufacture, and low cost) as compared with conventional cameras. However, they have not been extensively employed due to their poor image clarity and low image resolution, especially for tasks that have high requirements on image quality and details such as text detection and text recognition. To address the problem, a framework of deep-learning-based pipeline structure was built to recognize text with three steps from raw data captured by employing lensless cameras. This pipeline structure consisted of the lensless imaging model U-Net, the text detection model connectionist text proposal network (CTPN), and the text recognition model convolutional recurrent neural network (CRNN). Compared with the method focusing only on image reconstruction, UNet in the pipeline was able to supplement the imaging details by enhancing factors related to character categories in the reconstruction process, so the textual information can be more effectively detected and recognized by CTPN and CRNN with fewer artifacts and high-clarity reconstructed lensless images. By performing experiments on datasets of different complexities, the applicability to text detection and recognition on lensless cameras was verified. This study reasonably demonstrates text detection and recognition tasks in the lensless camera system,and develops a basic method for novel applications.
Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising
May 24, 2021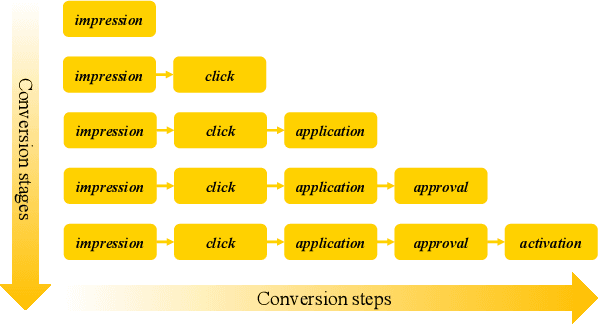

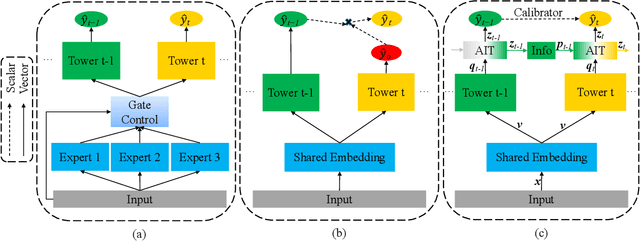
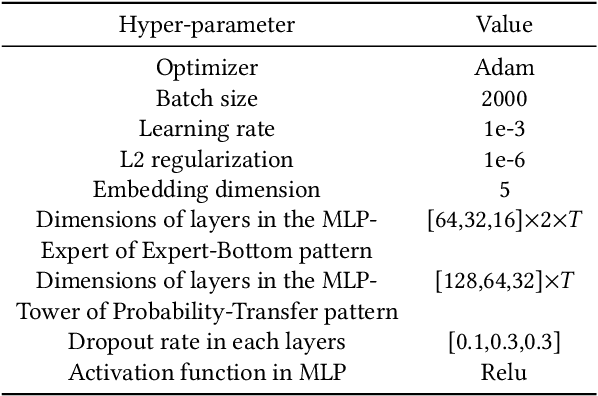
In most real-world large-scale online applications (e.g., e-commerce or finance), customer acquisition is usually a multi-step conversion process of audiences. For example, an impression->click->purchase process is usually performed of audiences for e-commerce platforms. However, it is more difficult to acquire customers in financial advertising (e.g., credit card advertising) than in traditional advertising. On the one hand, the audience multi-step conversion path is longer. On the other hand, the positive feedback is sparser (class imbalance) step by step, and it is difficult to obtain the final positive feedback due to the delayed feedback of activation. Multi-task learning is a typical solution in this direction. While considerable multi-task efforts have been made in this direction, a long-standing challenge is how to explicitly model the long-path sequential dependence among audience multi-step conversions for improving the end-to-end conversion. In this paper, we propose an Adaptive Information Transfer Multi-task (AITM) framework, which models the sequential dependence among audience multi-step conversions via the Adaptive Information Transfer (AIT) module. The AIT module can adaptively learn what and how much information to transfer for different conversion stages. Besides, by combining the Behavioral Expectation Calibrator in the loss function, the AITM framework can yield more accurate end-to-end conversion identification. The proposed framework is deployed in Meituan app, which utilizes it to real-timely show a banner to the audience with a high end-to-end conversion rate for Meituan Co-Branded Credit Cards. Offline experimental results on both industrial and public real-world datasets clearly demonstrate that the proposed framework achieves significantly better performance compared with state-of-the-art baselines.