 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Jun 19, 2024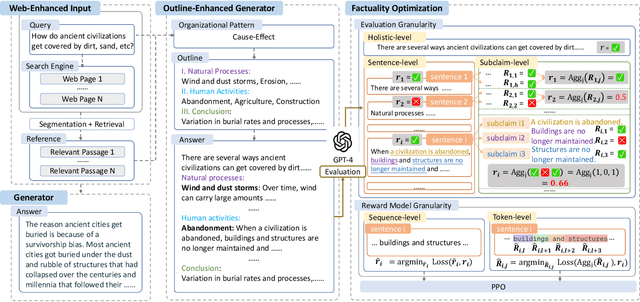
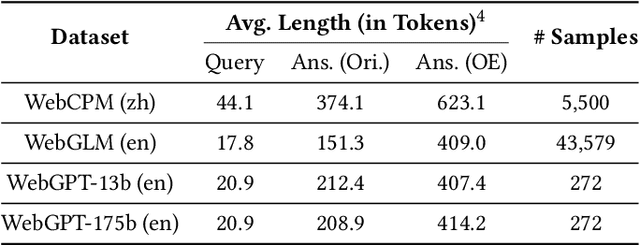

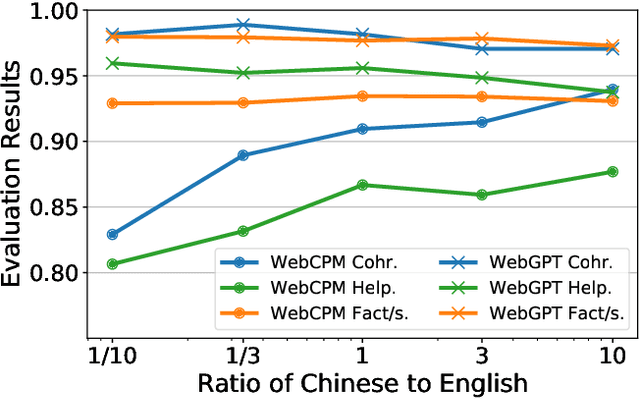
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed \textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.
A novel three-stage training strategy for long-tailed classification
Apr 20, 2021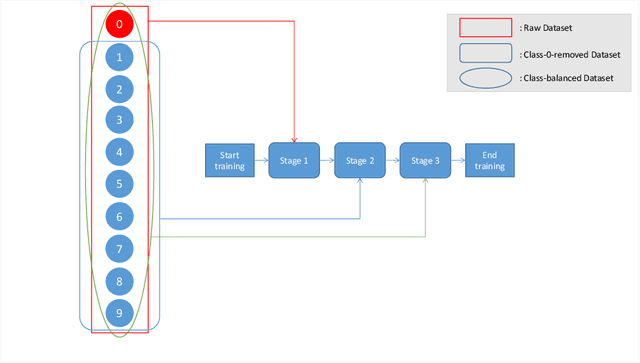
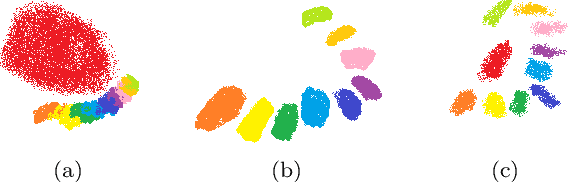
The long-tailed distribution datasets poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balacing strategies or transfer learing from head- to tail-classes or use two-stages learning strategy to re-train the classifier. However, the existing methods are difficult to solve the low quality problem when images are obtained by SAR. To address this problem, we establish a novel three-stages training strategy, which has excellent results for processing SAR image datasets with long-tailed distribution. Specifically, we divide training procedure into three stages. The first stage is to use all kinds of images for rough-training, so as to get the rough-training model with rich content. The second stage is to make the rough model learn the feature expression by using the residual dataset with the class 0 removed. The third stage is to fine tune the model using class-balanced datasets with all 10 classes (including the overall model fine tuning and classifier re-optimization). Through this new training strategy, we only use the information of SAR image dataset and the network model with very small parameters to achieve the top 1 accuracy of 22.34 in development phase.
Unsupervised domain adaptation with exploring more statistics and discriminative information
Mar 26, 2020


Unsupervised domain adaptation aims at transferring knowledge from the labeled source domain to the unlabeled target domain. Previous methods mainly learn a domain-invariant feature transformation, where the cross-domain discrepancy can be reduced. Maximum Mean Discrepancy(MMD) is the most popular statistic to measure domain discrepancy. However, these methods may suffer from two challenges. 1) MMD-based methods only measure the first-order statistic information across domains, while other useful information such as second-order statistic information has been ignored. 2) The classifier trained on the source domain may confuse to distinguish the correct class from a similar class, and the phenomenon is called class confusion. In this paper, we propose a method called \emph{Unsupervised domain adaptation with exploring more statistics and discriminative information}(MSDI), which tackle these two problems in the principle of structural risk minimization. We adopt the recently proposed statistic called MMCD to measure domain discrepancy which can capture both first-order and second-order statistics simultaneously in RKHS. Besides, we proposed to learn more discriminative features to avoid class confusion, where the inner of the classifier predictions with their transposes are used to reflect the confusion relationship between different classes. Moreover, we minimizing source empirical risk and adopt manifold regularization to explore geometry information in the target domain. MSDI learns a domain-invariant classifier in a unified learning framework incorporating the above objectives. We conduct comprehensive experiments on five real-world datasets and the results verify the effectiveness of the proposed method.
Dual Adversarial Domain Adaptation
Jan 01, 2020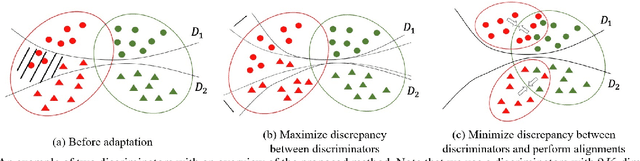
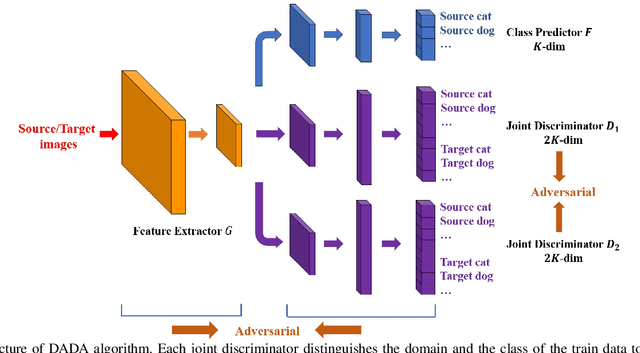

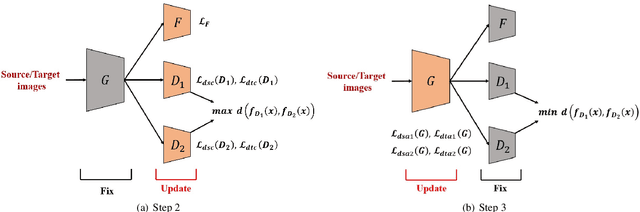
Unsupervised domain adaptation aims at transferring knowledge from the labeled source domain to the unlabeled target domain. Previous adversarial domain adaptation methods mostly adopt the discriminator with binary or $K$-dimensional output to perform marginal or conditional alignment independently. Recent experiments have shown that when the discriminator is provided with domain information in both domains and label information in the source domain, it is able to preserve the complex multimodal information and high semantic information in both domains. Following this idea, we adopt a discriminator with $2K$-dimensional output to perform both domain-level and class-level alignments simultaneously in a single discriminator. However, a single discriminator can not capture all the useful information across domains and the relationships between the examples and the decision boundary are rarely explored before. Inspired by multi-view learning and latest advances in domain adaptation, besides the adversarial process between the discriminator and the feature extractor, we also design a novel mechanism to make two discriminators pit against each other, so that they can provide diverse information for each other and avoid generating target features outside the support of the source domain. To the best of our knowledge, it is the first time to explore a dual adversarial strategy in domain adaptation. Moreover, we also use the semi-supervised learning regularization to make the representations more discriminative. Comprehensive experiments on two real-world datasets verify that our method outperforms several state-of-the-art domain adaptation methods.
Homogeneous Online Transfer Learning with Online Distribution Discrepancy Minimization
Dec 31, 2019
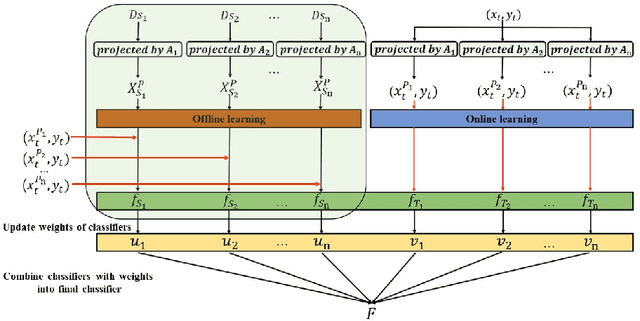
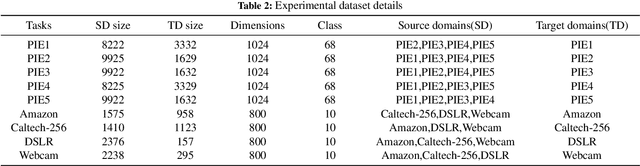

Transfer learning has been demonstrated to be successful and essential in diverse applications, which transfers knowledge from related but different source domains to the target domain. Online transfer learning(OTL) is a more challenging problem where the target data arrive in an online manner. Most OTL methods combine source classifier and target classifier directly by assigning a weight to each classifier, and adjust the weights constantly. However, these methods pay little attention to reducing the distribution discrepancy between domains. In this paper, we propose a novel online transfer learning method which seeks to find a new feature representation, so that the marginal distribution and conditional distribution discrepancy can be online reduced simultaneously. We focus on online transfer learning with multiple source domains and use the Hedge strategy to leverage knowledge from source domains. We analyze the theoretical properties of the proposed algorithm and provide an upper mistake bound. Comprehensive experiments on two real-world datasets show that our method outperforms state-of-the-art methods by a large margin.