 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapt CLIP as Aggregation Instructor for Image Dehazing
Aug 22, 2024



Most dehazing methods suffer from limited receptive field and do not explore the rich semantic prior encapsulated in vision-language models, which have proven effective in downstream tasks. In this paper, we introduce CLIPHaze, a pioneering hybrid framework that synergizes the efficient global modeling of Mamba with the prior knowledge and zero-shot capabilities of CLIP to address both issues simultaneously. Specifically, our method employs parallel state space model and window-based self-attention to obtain global contextual dependency and local fine-grained perception, respectively. To seamlessly aggregate information from both paths, we introduce CLIP-instructed Aggregation Module (CAM). For non-homogeneous and homogeneous haze, CAM leverages zero-shot estimated haze density map and high-quality image embedding without degradation information to explicitly and implicitly determine the optimal neural operation range for each pixel, thereby adaptively fusing two paths with different receptive fields. Extensive experiments on various benchmarks demonstrate that CLIPHaze achieves state-of-the-art (SOTA) performance, particularly in non-homogeneous haze. Code will be publicly after acceptance.
A novel three-stage training strategy for long-tailed classification
Apr 20, 2021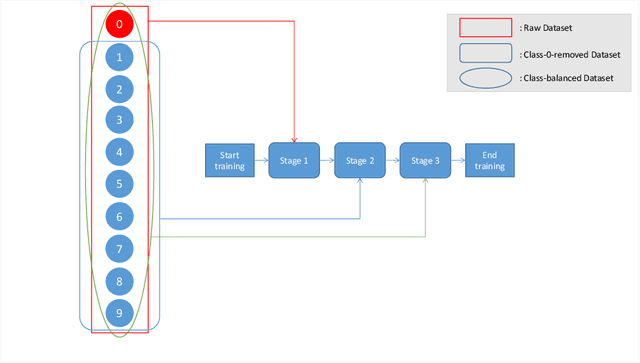
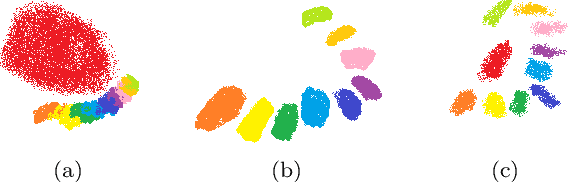
The long-tailed distribution datasets poses great challenges for deep learning based classification models on how to handle the class imbalance problem. Existing solutions usually involve class-balacing strategies or transfer learing from head- to tail-classes or use two-stages learning strategy to re-train the classifier. However, the existing methods are difficult to solve the low quality problem when images are obtained by SAR. To address this problem, we establish a novel three-stages training strategy, which has excellent results for processing SAR image datasets with long-tailed distribution. Specifically, we divide training procedure into three stages. The first stage is to use all kinds of images for rough-training, so as to get the rough-training model with rich content. The second stage is to make the rough model learn the feature expression by using the residual dataset with the class 0 removed. The third stage is to fine tune the model using class-balanced datasets with all 10 classes (including the overall model fine tuning and classifier re-optimization). Through this new training strategy, we only use the information of SAR image dataset and the network model with very small parameters to achieve the top 1 accuracy of 22.34 in development phase.