 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace4RAG: Factual Consistency Evaluation for Retrieval Augmented Generation in Chinese
Jul 01, 2024



The prevailing issue of factual inconsistency errors in conventional Retrieval Augmented Generation (RAG) motivates the study of Factual Consistency Evaluation (FCE). Despite the various FCE methods proposed earlier, these methods are evaluated on datasets generated by specific Large Language Models (LLMs). Without a comprehensive benchmark, it remains unexplored how these FCE methods perform on other LLMs with different error distributions or even unseen error types, as these methods may fail to detect the error types generated by other LLMs. To fill this gap, in this paper, we propose the first comprehensive FCE benchmark \emph{Face4RAG} for RAG independent of the underlying LLM. Our benchmark consists of a synthetic dataset built upon a carefully designed typology for factuality inconsistency error and a real-world dataset constructed from six commonly used LLMs, enabling evaluation of FCE methods on specific error types or real-world error distributions. On the proposed benchmark, we discover the failure of existing FCE methods to detect the logical fallacy, which refers to a mismatch of logic structures between the answer and the retrieved reference. To fix this issue, we further propose a new method called \emph{L-Face4RAG} with two novel designs of logic-preserving answer decomposition and fact-logic FCE. Extensive experiments show L-Face4RAG substantially outperforms previous methods for factual inconsistency detection on a wide range of tasks, notably beyond the RAG task from which it is originally motivated. Both the benchmark and our proposed method are publicly available.\footnote{\url{https://huggingface.co/datasets/yq27/Face4RAG}\label{link_face4rag}}
FoRAG: Factuality-optimized Retrieval Augmented Generation for Web-enhanced Long-form Question Answering
Jun 19, 2024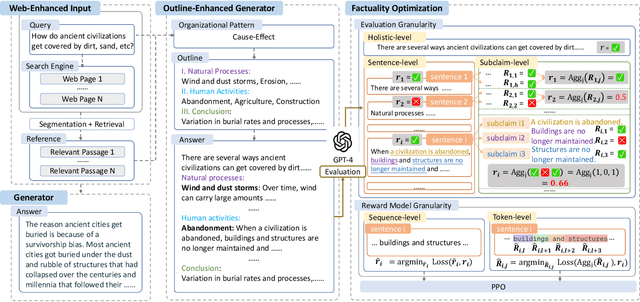
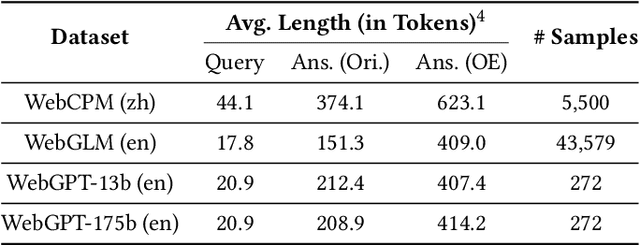

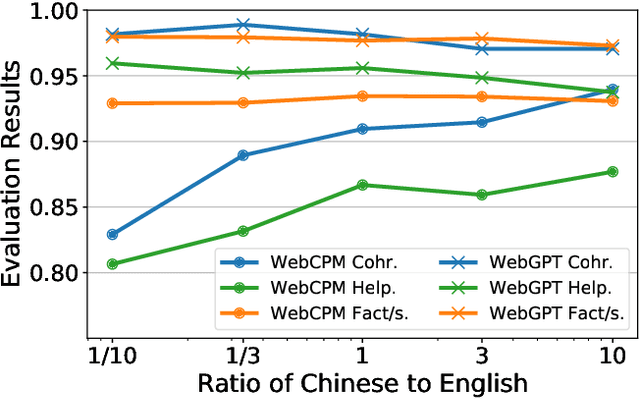
Retrieval Augmented Generation (RAG) has become prevalent in question-answering (QA) tasks due to its ability of utilizing search engine to enhance the quality of long-form question-answering (LFQA). Despite the emergence of various open source methods and web-enhanced commercial systems such as Bing Chat, two critical problems remain unsolved, i.e., the lack of factuality and clear logic in the generated long-form answers. In this paper, we remedy these issues via a systematic study on answer generation in web-enhanced LFQA. Specifically, we first propose a novel outline-enhanced generator to achieve clear logic in the generation of multifaceted answers and construct two datasets accordingly. Then we propose a factuality optimization method based on a carefully designed doubly fine-grained RLHF framework, which contains automatic evaluation and reward modeling in different levels of granularity. Our generic framework comprises conventional fine-grained RLHF methods as special cases. Extensive experiments verify the superiority of our proposed \textit{Factuality-optimized RAG (FoRAG)} method on both English and Chinese benchmarks. In particular, when applying our method to Llama2-7B-chat, the derived model FoRAG-L-7B outperforms WebGPT-175B in terms of three commonly used metrics (i.e., coherence, helpfulness, and factuality), while the number of parameters is much smaller (only 1/24 of that of WebGPT-175B). Our datasets and models are made publicly available for better reproducibility: https://huggingface.co/forag.