 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeV2P: Visual Attention Calibration for GUI Grounding via Background Suppression and Center Peaking
Jan 11, 2026Precise localization of GUI elements is crucial for the development of GUI agents. Traditional methods rely on bounding box or center-point regression, neglecting spatial interaction uncertainty and visual-semantic hierarchies. Recent methods incorporate attention mechanisms but still face two key issues: (1) ignoring processing background regions causes attention drift from the desired area, and (2) uniform modeling the target UI element fails to distinguish between its center and edges, leading to click imprecision. Inspired by how humans visually process and interact with GUI elements, we propose the Valley-to-Peak (V2P) method to address these issues. To mitigate background distractions, V2P introduces a suppression attention mechanism that minimizes the model's focus on irrelevant regions to highlight the intended region. For the issue of center-edge distinction, V2P applies a Fitts' Law-inspired approach by modeling GUI interactions as 2D Gaussian heatmaps where the weight gradually decreases from the center towards the edges. The weight distribution follows a Gaussian function, with the variance determined by the target's size. Consequently, V2P effectively isolates the target area and teaches the model to concentrate on the most essential point of the UI element. The model trained by V2P achieves the performance with 92.4\% and 52.5\% on two benchmarks ScreenSpot-v2 and ScreenSpot-Pro (see Fig.~\ref{fig:main_results_charts}). Ablations further confirm each component's contribution, underscoring V2P's generalizability in precise GUI grounding tasks and its potential for real-world deployment in future GUI agents.
MedDialogRubrics: A Comprehensive Benchmark and Evaluation Framework for Multi-turn Medical Consultations in Large Language Models
Jan 07, 2026Medical conversational AI (AI) plays a pivotal role in the development of safer and more effective medical dialogue systems. However, existing benchmarks and evaluation frameworks for assessing the information-gathering and diagnostic reasoning abilities of medical large language models (LLMs) have not been rigorously evaluated. To address these gaps, we present MedDialogRubrics, a novel benchmark comprising 5,200 synthetically constructed patient cases and over 60,000 fine-grained evaluation rubrics generated by LLMs and subsequently refined by clinical experts, specifically designed to assess the multi-turn diagnostic capabilities of LLM. Our framework employs a multi-agent system to synthesize realistic patient records and chief complaints from underlying disease knowledge without accessing real-world electronic health records, thereby mitigating privacy and data-governance concerns. We design a robust Patient Agent that is limited to a set of atomic medical facts and augmented with a dynamic guidance mechanism that continuously detects and corrects hallucinations throughout the dialogue, ensuring internal coherence and clinical plausibility of the simulated cases. Furthermore, we propose a structured LLM-based and expert-annotated rubric-generation pipeline that retrieves Evidence-Based Medicine (EBM) guidelines and utilizes the reject sampling to derive a prioritized set of rubric items ("must-ask" items) for each case. We perform a comprehensive evaluation of state-of-the-art models and demonstrate that, across multiple assessment dimensions, current models face substantial challenges. Our results indicate that improving medical dialogue will require advances in dialogue management architectures, not just incremental tuning of the base-model.
Perplexity-Aware Data Scaling Law: Perplexity Landscapes Predict Performance for Continual Pre-training
Dec 25, 2025Continual Pre-training (CPT) serves as a fundamental approach for adapting foundation models to domain-specific applications. Scaling laws for pre-training define a power-law relationship between dataset size and the test loss of an LLM. However, the marginal gains from simply increasing data for CPT diminish rapidly, yielding suboptimal data utilization and inefficient training. To address this challenge, we propose a novel perplexity-aware data scaling law to establish a predictive relationship between the perplexity landscape of domain-specific data and the test loss. Our approach leverages the perplexity derived from the pre-trained model on domain data as a proxy for estimating the knowledge gap, effectively quantifying the informational perplexity landscape of candidate training samples. By fitting this scaling law across diverse perplexity regimes, we enable adaptive selection of high-utility data subsets, prioritizing content that maximizes knowledge absorption while minimizing redundancy and noise. Extensive experiments demonstrate that our method consistently identifies near-optimal training subsets and achieves superior performance on both medical and general-domain benchmarks.
Multi-Agent Deep Research: Training Multi-Agent Systems with M-GRPO
Nov 18, 2025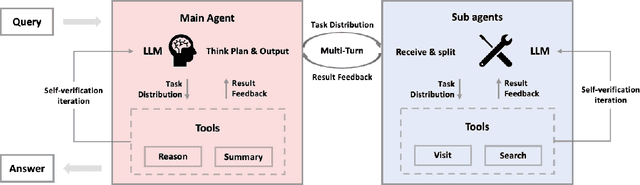
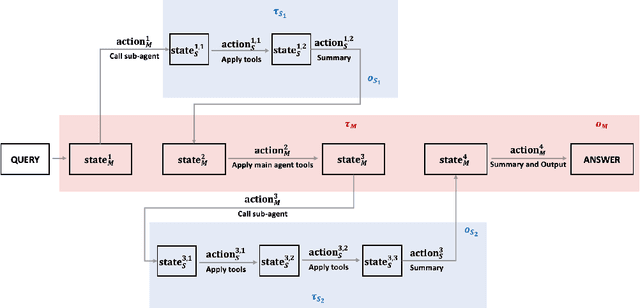
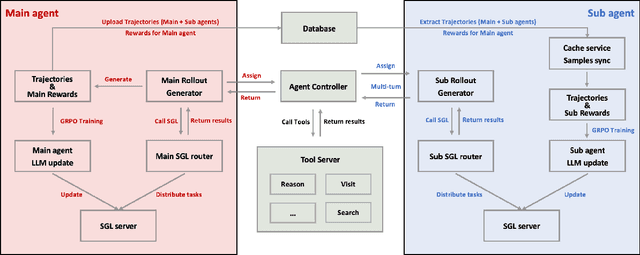
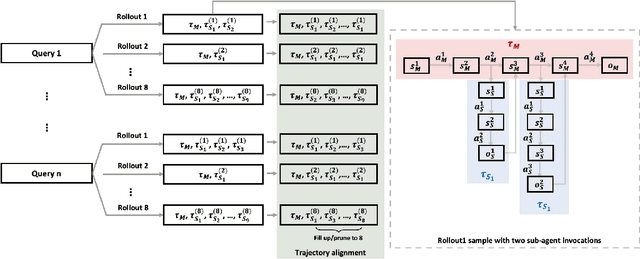
Multi-agent systems perform well on general reasoning tasks. However, the lack of training in specialized areas hinders their accuracy. Current training methods train a unified large language model (LLM) for all agents in the system. This may limit the performances due to different distributions underlying for different agents. Therefore, training multi-agent systems with distinct LLMs should be the next step to solve. However, this approach introduces optimization challenges. For example, agents operate at different frequencies, rollouts involve varying sub-agent invocations, and agents are often deployed across separate servers, disrupting end-to-end gradient flow. To address these issues, we propose M-GRPO, a hierarchical extension of Group Relative Policy Optimization designed for vertical Multi-agent systems with a main agent (planner) and multiple sub-agents (multi-turn tool executors). M-GRPO computes group-relative advantages for both main and sub-agents, maintaining hierarchical credit assignment. It also introduces a trajectory-alignment scheme that generates fixed-size batches despite variable sub-agent invocations. We deploy a decoupled training pipeline in which agents run on separate servers and exchange minimal statistics via a shared store. This enables scalable training without cross-server backpropagation. In experiments on real-world benchmarks (e.g., GAIA, XBench-DeepSearch, and WebWalkerQA), M-GRPO consistently outperforms both single-agent GRPO and multi-agent GRPO with frozen sub-agents, demonstrating improved stability and sample efficiency. These results show that aligning heterogeneous trajectories and decoupling optimization across specialized agents enhances tool-augmented reasoning tasks.
GroupRank: A Groupwise Reranking Paradigm Driven by Reinforcement Learning
Nov 10, 2025Large Language Models have shown strong potential as rerankers to enhance the overall performance of RAG systems. However, existing reranking paradigms are constrained by a core theoretical and practical dilemma: Pointwise methods, while simple and highly flexible, evaluate documents independently, making them prone to the Ranking Myopia Trap, overlooking the relative importance between documents. In contrast, Listwise methods can perceive the global ranking context, but suffer from inherent List Rigidity, leading to severe scalability and flexibility issues when handling large candidate sets. To address these challenges, we propose Groupwise, a novel reranking paradigm. In this approach, the query and a group of candidate documents are jointly fed into the model, which performs within-group comparisons to assign individual relevance scores to each document. This design retains the flexibility of Pointwise methods while enabling the comparative capability of Listwise methods. We further adopt GRPO for model training, equipped with a heterogeneous reward function that integrates ranking metrics with a distributional reward aimed at aligning score distributions across groups. To overcome the bottleneck caused by the scarcity of high quality labeled data, we further propose an innovative pipeline for synthesizing high quality retrieval and ranking data. The resulting data can be leveraged not only for training the reranker but also for training the retriever. Extensive experiments validate the effectiveness of our approach. On two reasoning intensive retrieval benchmarks, BRIGHT and R2MED.
HAD: HAllucination Detection Language Models Based on a Comprehensive Hallucination Taxonomy
Oct 22, 2025The increasing reliance on natural language generation (NLG) models, particularly large language models, has raised concerns about the reliability and accuracy of their outputs. A key challenge is hallucination, where models produce plausible but incorrect information. As a result, hallucination detection has become a critical task. In this work, we introduce a comprehensive hallucination taxonomy with 11 categories across various NLG tasks and propose the HAllucination Detection (HAD) models https://github.com/pku0xff/HAD, which integrate hallucination detection, span-level identification, and correction into a single inference process. Trained on an elaborate synthetic dataset of about 90K samples, our HAD models are versatile and can be applied to various NLG tasks. We also carefully annotate a test set for hallucination detection, called HADTest, which contains 2,248 samples. Evaluations on in-domain and out-of-domain test sets show that our HAD models generally outperform the existing baselines, achieving state-of-the-art results on HaluEval, FactCHD, and FaithBench, confirming their robustness and versatility.
MedReseacher-R1: Expert-Level Medical Deep Researcher via A Knowledge-Informed Trajectory Synthesis Framework
Aug 20, 2025Recent developments in Large Language Model (LLM)-based agents have shown impressive capabilities spanning multiple domains, exemplified by deep research systems that demonstrate superior performance on complex information-seeking and synthesis tasks. While general-purpose deep research agents have shown impressive capabilities, they struggle significantly with medical domain challenges, as evidenced by leading proprietary systems achieving limited accuracy on complex medical benchmarks. The key limitations are: (1) the model lacks sufficient dense medical knowledge for clinical reasoning, and (2) the framework is constrained by the absence of specialized retrieval tools tailored for medical contexts.We present a medical deep research agent that addresses these challenges through two core innovations. First, we develop a novel data synthesis framework using medical knowledge graphs, extracting the longest chains from subgraphs around rare medical entities to generate complex multi-hop question-answer pairs. Second, we integrate a custom-built private medical retrieval engine alongside general-purpose tools, enabling accurate medical information synthesis. Our approach generates 2100+ diverse trajectories across 12 medical specialties, each averaging 4.2 tool interactions.Through a two-stage training paradigm combining supervised fine-tuning and online reinforcement learning with composite rewards, our MedResearcher-R1-32B model demonstrates exceptional performance, establishing new state-of-the-art results on medical benchmarks while maintaining competitive performance on general deep research tasks. Our work demonstrates that strategic domain-specific innovations in architecture, tool design, and training data construction can enable smaller open-source models to outperform much larger proprietary systems in specialized domains.
AWorld: Dynamic Multi-Agent System with Stable Maneuvering for Robust GAIA Problem Solving
Aug 13, 2025The rapid advancement of large language models (LLMs) has empowered intelligent agents to leverage diverse external tools for solving complex real-world problems. However, as agents increasingly depend on multiple tools, they encounter new challenges: extended contexts from disparate sources and noisy or irrelevant tool outputs can undermine system reliability and accuracy. These challenges underscore the necessity for enhanced stability in agent-based systems. To address this, we introduce dynamic supervision and maneuvering mechanisms, constructing a robust and dynamic Multi-Agent System (MAS) architecture within the AWorld framework. In our approach, the Execution Agent invokes the Guard Agent at critical steps to verify and correct the reasoning process, effectively reducing errors arising from noise and bolstering problem-solving robustness. Extensive experiments on the GAIA test dataset reveal that our dynamic maneuvering mechanism significantly improves both the effectiveness and stability of solutions, outperforming single-agent system (SAS) and standard tool-augmented systems. As a result, our dynamic MAS system achieved first place among open-source projects on the prestigious GAIA leaderboard. These findings highlight the practical value of collaborative agent roles in developing more reliable and trustworthy intelligent systems.
DIVER: A Multi-Stage Approach for Reasoning-intensive Information Retrieval
Aug 12, 2025Retrieval-augmented generation has achieved strong performance on knowledge-intensive tasks where query-document relevance can be identified through direct lexical or semantic matches. However, many real-world queries involve abstract reasoning, analogical thinking, or multi-step inference, which existing retrievers often struggle to capture. To address this challenge, we present \textbf{DIVER}, a retrieval pipeline tailored for reasoning-intensive information retrieval. DIVER consists of four components: document processing to improve input quality, LLM-driven query expansion via iterative document interaction, a reasoning-enhanced retriever fine-tuned on synthetic multi-domain data with hard negatives, and a pointwise reranker that combines LLM-assigned helpfulness scores with retrieval scores. On the BRIGHT benchmark, DIVER achieves state-of-the-art nDCG@10 scores of 41.6 and 28.9 on original queries, consistently outperforming competitive reasoning-aware models. These results demonstrate the effectiveness of reasoning-aware retrieval strategies in complex real-world tasks. Our code and retrieval model will be released soon.
Learning to Align, Aligning to Learn: A Unified Approach for Self-Optimized Alignment
Aug 11, 2025



Alignment methodologies have emerged as a critical pathway for enhancing language model alignment capabilities. While SFT (supervised fine-tuning) accelerates convergence through direct token-level loss intervention, its efficacy is constrained by offline policy trajectory. In contrast, RL(reinforcement learning) facilitates exploratory policy optimization, but suffers from low sample efficiency and stringent dependency on high-quality base models. To address these dual challenges, we propose GRAO (Group Relative Alignment Optimization), a unified framework that synergizes the respective strengths of SFT and RL through three key innovations: 1) A multi-sample generation strategy enabling comparative quality assessment via reward feedback; 2) A novel Group Direct Alignment Loss formulation leveraging intra-group relative advantage weighting; 3) Reference-aware parameter updates guided by pairwise preference dynamics. Our theoretical analysis establishes GRAO's convergence guarantees and sample efficiency advantages over conventional approaches. Comprehensive evaluations across complex human alignment tasks demonstrate GRAO's superior performance, achieving 57.70\%,17.65\% 7.95\% and 5.18\% relative improvements over SFT, DPO, PPO and GRPO baselines respectively. This work provides both a theoretically grounded alignment framework and empirical evidence for efficient capability evolution in language models.