 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRetrofit: Continual Learning with Bounded Forgetting for Security Applications
Nov 14, 2025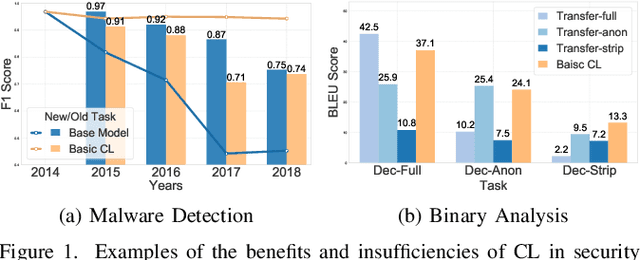
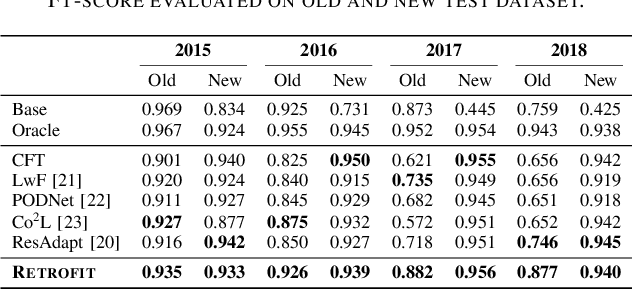

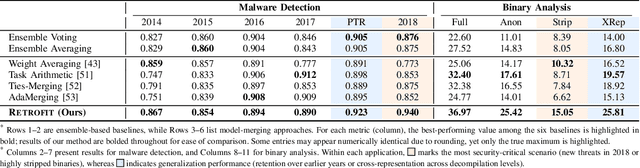
Modern security analytics are increasingly powered by deep learning models, but their performance often degrades as threat landscapes evolve and data representations shift. While continual learning (CL) offers a promising paradigm to maintain model effectiveness, many approaches rely on full retraining or data replay, which are infeasible in data-sensitive environments. Moreover, existing methods remain inadequate for security-critical scenarios, facing two coupled challenges in knowledge transfer: preserving prior knowledge without old data and integrating new knowledge with minimal interference. We propose RETROFIT, a data retrospective-free continual learning method that achieves bounded forgetting for effective knowledge transfer. Our key idea is to consolidate previously trained and newly fine-tuned models, serving as teachers of old and new knowledge, through parameter-level merging that eliminates the need for historical data. To mitigate interference, we apply low-rank and sparse updates that confine parameter changes to independent subspaces, while a knowledge arbitration dynamically balances the teacher contributions guided by model confidence. Our evaluation on two representative applications demonstrates that RETROFIT consistently mitigates forgetting while maintaining adaptability. In malware detection under temporal drift, it substantially improves the retention score, from 20.2% to 38.6% over CL baselines, and exceeds the oracle upper bound on new data. In binary summarization across decompilation levels, where analyzing stripped binaries is especially challenging, RETROFIT achieves around twice the BLEU score of transfer learning used in prior work and surpasses all baselines in cross-representation generalization.
A Survey on Medical Large Language Models: Technology, Application, Trustworthiness, and Future Directions
Jun 06, 2024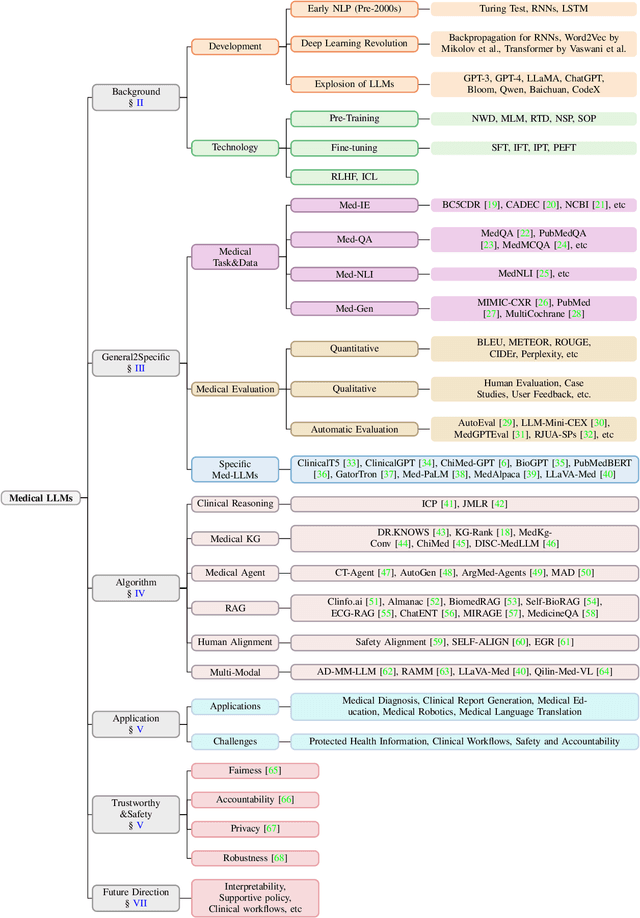
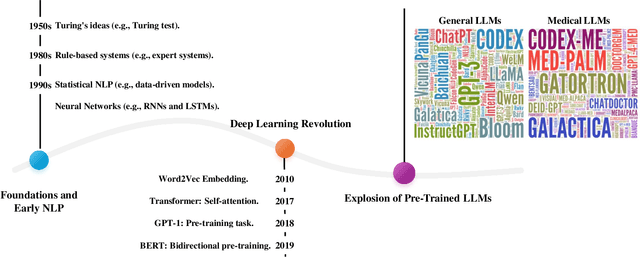


Large language models (LLMs), such as GPT series models, have received substantial attention due to their impressive capabilities for generating and understanding human-level language. More recently, LLMs have emerged as an innovative and powerful adjunct in the medical field, transforming traditional practices and heralding a new era of enhanced healthcare services. This survey provides a comprehensive overview of Medical Large Language Models (Med-LLMs), outlining their evolution from general to the medical-specific domain (i.e, Technology and Application), as well as their transformative impact on healthcare (e.g., Trustworthiness and Safety). Concretely, starting from the fundamental history and technology of LLMs, we first delve into the progressive adaptation and refinements of general LLM models in the medical domain, especially emphasizing the advanced algorithms that boost the LLMs' performance in handling complicated medical environments, including clinical reasoning, knowledge graph, retrieval-augmented generation, human alignment, and multi-modal learning. Secondly, we explore the extensive applications of Med-LLMs across domains such as clinical decision support, report generation, and medical education, illustrating their potential to streamline healthcare services and augment patient outcomes. Finally, recognizing the imperative and responsible innovation, we discuss the challenges of ensuring fairness, accountability, privacy, and robustness in Med-LLMs applications. Finally, we conduct a concise discussion for anticipating possible future trajectories of Med-LLMs, identifying avenues for the prudent expansion of Med-LLMs. By consolidating above-mentioned insights, this review seeks to provide a comprehensive investigation of the potential strengths and limitations of Med-LLMs for professionals and researchers, ensuring a responsible landscape in the healthcare setting.
Going Proactive and Explanatory Against Malware Concept Drift
May 07, 2024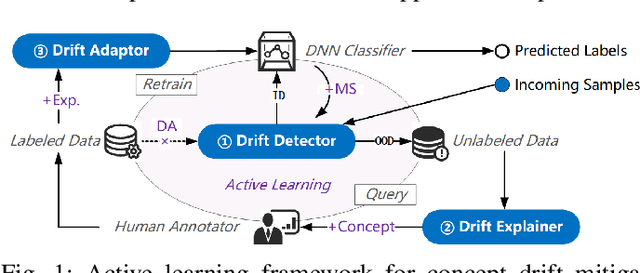
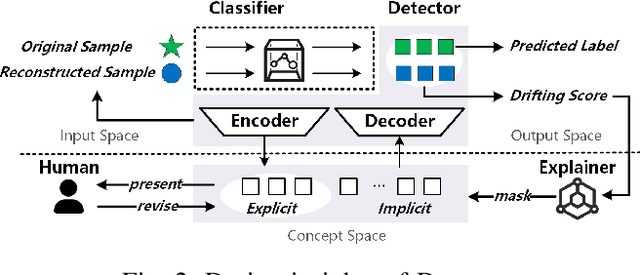
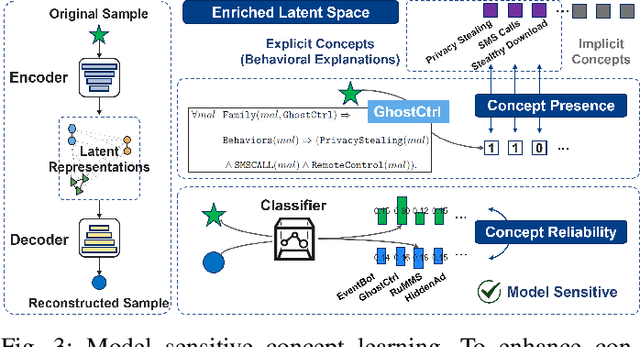
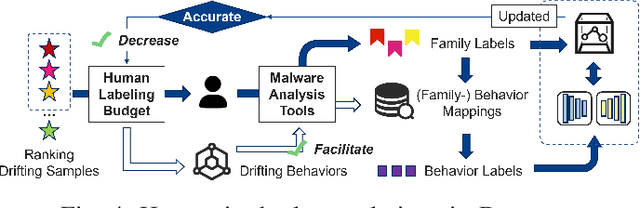
Deep learning-based malware classifiers face significant challenges due to concept drift. The rapid evolution of malware, especially with new families, can depress classification accuracy to near-random levels. Previous research has primarily focused on detecting drift samples, relying on expert-led analysis and labeling for model retraining. However, these methods often lack a comprehensive understanding of malware concepts and provide limited guidance for effective drift adaptation, leading to unstable detection performance and high human labeling costs. To address these limitations, we introduce DREAM, a novel system designed to surpass the capabilities of existing drift detectors and to establish an explanatory drift adaptation process. DREAM enhances drift detection through model sensitivity and data autonomy. The detector, trained in a semi-supervised approach, proactively captures malware behavior concepts through classifier feedback. During testing, it utilizes samples generated by the detector itself, eliminating reliance on extensive training data. For drift adaptation, DREAM enlarges human intervention, enabling revisions of malware labels and concept explanations embedded within the detector's latent space. To ensure a comprehensive response to concept drift, it facilitates a coordinated update process for both the classifier and the detector. Our evaluation shows that DREAM can effectively improve the drift detection accuracy and reduce the expert analysis effort in adaptation across different malware datasets and classifiers.