 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Steering Works: Toward a Unified View of Language Model Parameter Dynamics
Feb 02, 2026Methods for controlling large language models (LLMs), including local weight fine-tuning, LoRA-based adaptation, and activation-based interventions, are often studied in isolation, obscuring their connections and making comparison difficult. In this work, we present a unified view that frames these interventions as dynamic weight updates induced by a control signal, placing them within a single conceptual framework. Building on this view, we propose a unified preference-utility analysis that separates control effects into preference, defined as the tendency toward a target concept, and utility, defined as coherent and task-valid generation, and measures both on a shared log-odds scale using polarity-paired contrastive examples. Across methods, we observe a consistent trade-off between preference and utility: stronger control increases preference while predictably reducing utility. We further explain this behavior through an activation manifold perspective, in which control shifts representations along target-concept directions to enhance preference, while utility declines primarily when interventions push representations off the model's valid-generation manifold. Finally, we introduce a new steering approach SPLIT guided by this analysis that improves preference while better preserving utility. Code is available at https://github.com/zjunlp/EasyEdit/blob/main/examples/SPLIT.md.
A Causal Perspective for Enhancing Jailbreak Attack and Defense
Jan 31, 2026Uncovering the mechanisms behind "jailbreaks" in large language models (LLMs) is crucial for enhancing their safety and reliability, yet these mechanisms remain poorly understood. Existing studies predominantly analyze jailbreak prompts by probing latent representations, often overlooking the causal relationships between interpretable prompt features and jailbreak occurrences. In this work, we propose Causal Analyst, a framework that integrates LLMs into data-driven causal discovery to identify the direct causes of jailbreaks and leverage them for both attack and defense. We introduce a comprehensive dataset comprising 35k jailbreak attempts across seven LLMs, systematically constructed from 100 attack templates and 50 harmful queries, annotated with 37 meticulously designed human-readable prompt features. By jointly training LLM-based prompt encoding and GNN-based causal graph learning, we reconstruct causal pathways linking prompt features to jailbreak responses. Our analysis reveals that specific features, such as "Positive Character" and "Number of Task Steps", act as direct causal drivers of jailbreaks. We demonstrate the practical utility of these insights through two applications: (1) a Jailbreaking Enhancer that targets identified causal features to significantly boost attack success rates on public benchmarks, and (2) a Guardrail Advisor that utilizes the learned causal graph to extract true malicious intent from obfuscated queries. Extensive experiments, including baseline comparisons and causal structure validation, confirm the robustness of our causal analysis and its superiority over non-causal approaches. Our results suggest that analyzing jailbreak features from a causal perspective is an effective and interpretable approach for improving LLM reliability. Our code is available at https://github.com/Master-PLC/Causal-Analyst.
Deep Time-series Forecasting Needs Kernelized Moment Balancing
Jan 31, 2026Deep time-series forecasting can be formulated as a distribution balancing problem aimed at aligning the distribution of the forecasts and ground truths. According to Imbens' criterion, true distribution balance requires matching the first moments with respect to any balancing function. We demonstrate that existing objectives fail to meet this criterion, as they enforce moment matching only for one or two predefined balancing functions, thus failing to achieve full distribution balance. To address this limitation, we propose direct forecasting with kernelized moment balancing (KMB-DF). Unlike existing objectives, KMB-DF adaptively selects the most informative balancing functions from a reproducing kernel hilbert space (RKHS) to enforce sufficient distribution balancing. We derive a tractable and differentiable objective that enables efficient estimation from empirical samples and seamless integration into gradient-based training pipelines. Extensive experiments across multiple models and datasets show that KMB-DF consistently improves forecasting accuracy and achieves state-of-the-art performance. Code is available at https://anonymous.4open.science/r/KMB-DF-403C.
V2P: Visual Attention Calibration for GUI Grounding via Background Suppression and Center Peaking
Jan 11, 2026Precise localization of GUI elements is crucial for the development of GUI agents. Traditional methods rely on bounding box or center-point regression, neglecting spatial interaction uncertainty and visual-semantic hierarchies. Recent methods incorporate attention mechanisms but still face two key issues: (1) ignoring processing background regions causes attention drift from the desired area, and (2) uniform modeling the target UI element fails to distinguish between its center and edges, leading to click imprecision. Inspired by how humans visually process and interact with GUI elements, we propose the Valley-to-Peak (V2P) method to address these issues. To mitigate background distractions, V2P introduces a suppression attention mechanism that minimizes the model's focus on irrelevant regions to highlight the intended region. For the issue of center-edge distinction, V2P applies a Fitts' Law-inspired approach by modeling GUI interactions as 2D Gaussian heatmaps where the weight gradually decreases from the center towards the edges. The weight distribution follows a Gaussian function, with the variance determined by the target's size. Consequently, V2P effectively isolates the target area and teaches the model to concentrate on the most essential point of the UI element. The model trained by V2P achieves the performance with 92.4\% and 52.5\% on two benchmarks ScreenSpot-v2 and ScreenSpot-Pro (see Fig.~\ref{fig:main_results_charts}). Ablations further confirm each component's contribution, underscoring V2P's generalizability in precise GUI grounding tasks and its potential for real-world deployment in future GUI agents.
Perplexity-Aware Data Scaling Law: Perplexity Landscapes Predict Performance for Continual Pre-training
Dec 25, 2025Continual Pre-training (CPT) serves as a fundamental approach for adapting foundation models to domain-specific applications. Scaling laws for pre-training define a power-law relationship between dataset size and the test loss of an LLM. However, the marginal gains from simply increasing data for CPT diminish rapidly, yielding suboptimal data utilization and inefficient training. To address this challenge, we propose a novel perplexity-aware data scaling law to establish a predictive relationship between the perplexity landscape of domain-specific data and the test loss. Our approach leverages the perplexity derived from the pre-trained model on domain data as a proxy for estimating the knowledge gap, effectively quantifying the informational perplexity landscape of candidate training samples. By fitting this scaling law across diverse perplexity regimes, we enable adaptive selection of high-utility data subsets, prioritizing content that maximizes knowledge absorption while minimizing redundancy and noise. Extensive experiments demonstrate that our method consistently identifies near-optimal training subsets and achieves superior performance on both medical and general-domain benchmarks.
SWAP: Towards Copyright Auditing of Soft Prompts via Sequential Watermarking
Nov 05, 2025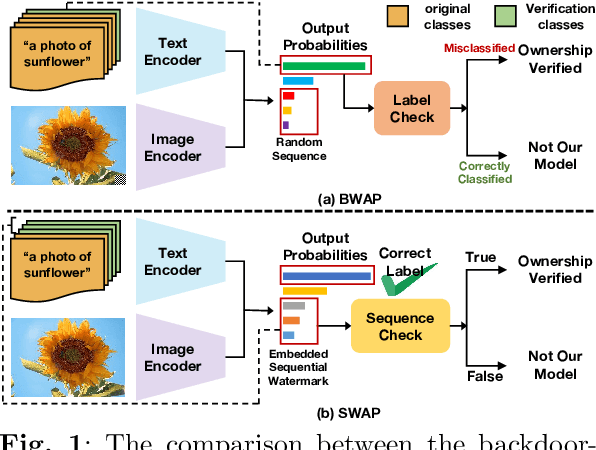
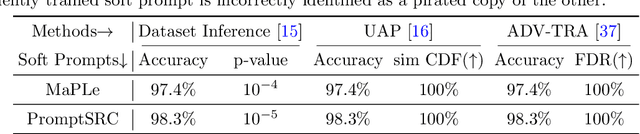
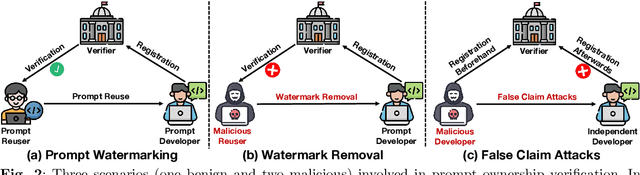
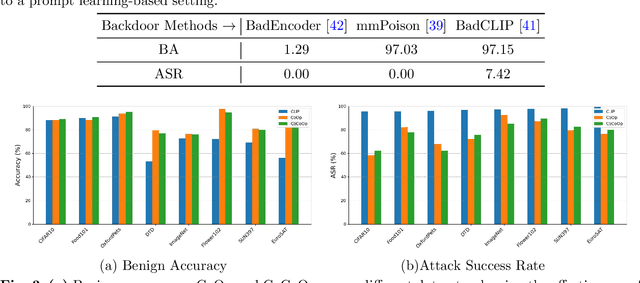
Large-scale vision-language models, especially CLIP, have demonstrated remarkable performance across diverse downstream tasks. Soft prompts, as carefully crafted modules that efficiently adapt vision-language models to specific tasks, necessitate effective copyright protection. In this paper, we investigate model copyright protection by auditing whether suspicious third-party models incorporate protected soft prompts. While this can be viewed as a special case of model ownership auditing, our analysis shows that existing techniques are ineffective due to prompt learning's unique characteristics. Non-intrusive auditing is inherently prone to false positives when independent models share similar data distributions with victim models. Intrusive approaches also fail: backdoor methods designed for CLIP cannot embed functional triggers, while extending traditional DNN backdoor techniques to prompt learning suffers from harmfulness and ambiguity challenges. We find that these failures in intrusive auditing stem from the same fundamental reason: watermarking operates within the same decision space as the primary task yet pursues opposing objectives. Motivated by these findings, we propose sequential watermarking for soft prompts (SWAP), which implants watermarks into a different and more complex space. SWAP encodes watermarks through a specific order of defender-specified out-of-distribution classes, inspired by the zero-shot prediction capability of CLIP. This watermark, which is embedded in a more complex space, keeps the original prediction label unchanged, making it less opposed to the primary task. We further design a hypothesis-test-guided verification protocol for SWAP and provide theoretical analyses of success conditions. Extensive experiments on 11 datasets demonstrate SWAP's effectiveness, harmlessness, and robustness against potential adaptive attacks.
Understanding and Mitigating Overrefusal in LLMs from an Unveiling Perspective of Safety Decision Boundary
May 23, 2025Large language models (LLMs) have demonstrated remarkable capabilities across a wide range of tasks, yet they often refuse to answer legitimate queries-a phenomenon known as overrefusal. Overrefusal typically stems from over-conservative safety alignment, causing models to treat many reasonable prompts as potentially risky. To systematically understand this issue, we probe and leverage the models'safety decision boundaries to analyze and mitigate overrefusal. Our findings reveal that overrefusal is closely tied to misalignment at these boundary regions, where models struggle to distinguish subtle differences between benign and harmful content. Building on these insights, we present RASS, an automated framework for prompt generation and selection that strategically targets overrefusal prompts near the safety boundary. By harnessing steering vectors in the representation space, RASS efficiently identifies and curates boundary-aligned prompts, enabling more effective and targeted mitigation of overrefusal. This approach not only provides a more precise and interpretable view of model safety decisions but also seamlessly extends to multilingual scenarios.We have explored the safety decision boundaries of various LLMs and construct the MORBench evaluation set to facilitate robust assessment of model safety and helpfulness across multiple languages. Code and datasets will be released at https://anonymous.4open.science/r/RASS-80D3.
Mitigating Social Bias in Large Language Models: A Multi-Objective Approach within a Multi-Agent Framework
Dec 20, 2024



Natural language processing (NLP) has seen remarkable advancements with the development of large language models (LLMs). Despite these advancements, LLMs often produce socially biased outputs. Recent studies have mainly addressed this problem by prompting LLMs to behave ethically, but this approach results in unacceptable performance degradation. In this paper, we propose a multi-objective approach within a multi-agent framework (MOMA) to mitigate social bias in LLMs without significantly compromising their performance. The key idea of MOMA involves deploying multiple agents to perform causal interventions on bias-related contents of the input questions, breaking the shortcut connection between these contents and the corresponding answers. Unlike traditional debiasing techniques leading to performance degradation, MOMA substantially reduces bias while maintaining accuracy in downstream tasks. Our experiments conducted on two datasets and two models demonstrate that MOMA reduces bias scores by up to 87.7%, with only a marginal performance degradation of up to 6.8% in the BBQ dataset. Additionally, it significantly enhances the multi-objective metric icat in the StereoSet dataset by up to 58.1%. Code will be made available at https://github.com/Cortantse/MOMA.
Explainable Behavior Cloning: Teaching Large Language Model Agents through Learning by Demonstration
Oct 30, 2024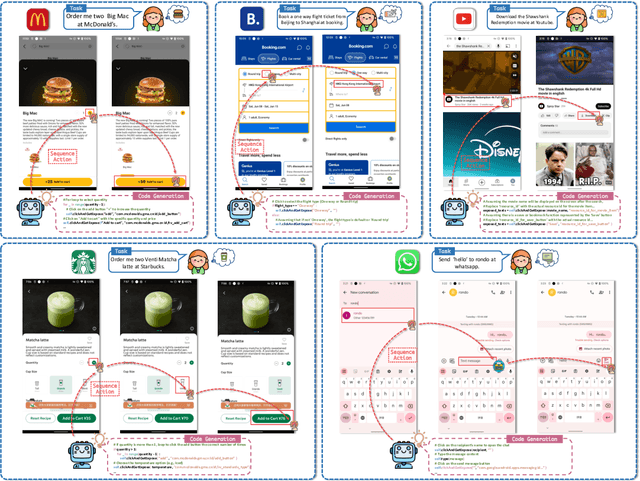
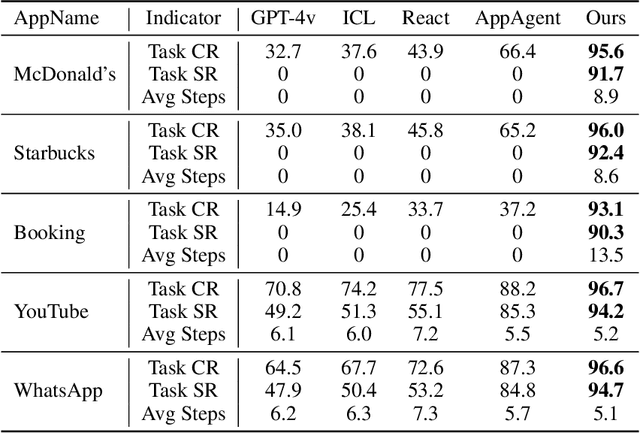
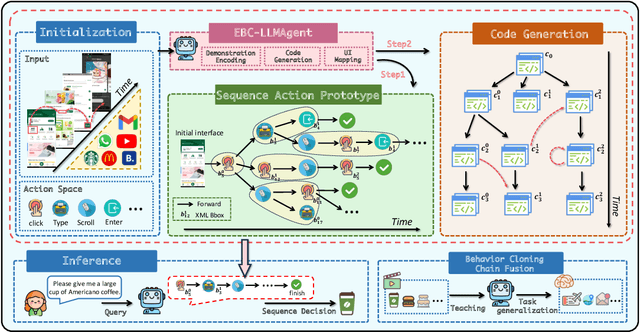
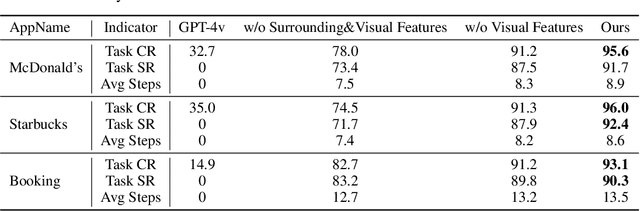
Autonomous mobile app interaction has become increasingly important with growing complexity of mobile applications. Developing intelligent agents that can effectively navigate and interact with mobile apps remains a significant challenge. In this paper, we propose an Explainable Behavior Cloning LLM Agent (EBC-LLMAgent), a novel approach that combines large language models (LLMs) with behavior cloning by learning demonstrations to create intelligent and explainable agents for autonomous mobile app interaction. EBC-LLMAgent consists of three core modules: Demonstration Encoding, Code Generation, and UI Mapping, which work synergistically to capture user demonstrations, generate executable codes, and establish accurate correspondence between code and UI elements. We introduce the Behavior Cloning Chain Fusion technique to enhance the generalization capabilities of the agent. Extensive experiments on five popular mobile applications from diverse domains demonstrate the superior performance of EBC-LLMAgent, achieving high success rates in task completion, efficient generalization to unseen scenarios, and the generation of meaningful explanations.
TimeMixer++: A General Time Series Pattern Machine for Universal Predictive Analysis
Oct 21, 2024



Time series analysis plays a critical role in numerous applications, supporting tasks such as forecasting, classification, anomaly detection, and imputation. In this work, we present the time series pattern machine (TSPM), a model designed to excel in a broad range of time series tasks through powerful representation and pattern extraction capabilities. Traditional time series models often struggle to capture universal patterns, limiting their effectiveness across diverse tasks. To address this, we define multiple scales in the time domain and various resolutions in the frequency domain, employing various mixing strategies to extract intricate, task-adaptive time series patterns. Specifically, we introduce a general-purpose TSPM that processes multi-scale time series using (1) multi-resolution time imaging (MRTI), (2) time image decomposition (TID), (3) multi-scale mixing (MCM), and (4) multi-resolution mixing (MRM) to extract comprehensive temporal patterns. MRTI transforms multi-scale time series into multi-resolution time images, capturing patterns across both temporal and frequency domains. TID leverages dual-axis attention to extract seasonal and trend patterns, while MCM hierarchically aggregates these patterns across scales. MRM adaptively integrates all representations across resolutions. This method achieves state-of-the-art performance across 8 time series analytical tasks, consistently surpassing both general-purpose and task-specific models. Our work marks a promising step toward the next generation of TSPMs, paving the way for further advancements in time series analysis.