 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWAP: Towards Copyright Auditing of Soft Prompts via Sequential Watermarking
Nov 05, 2025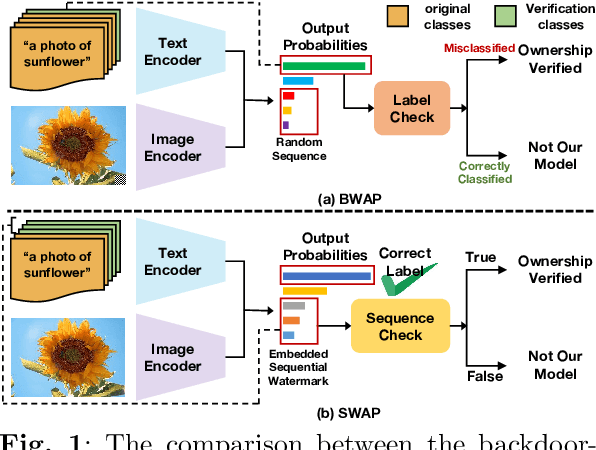
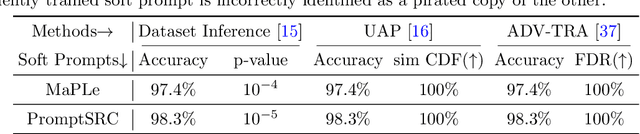
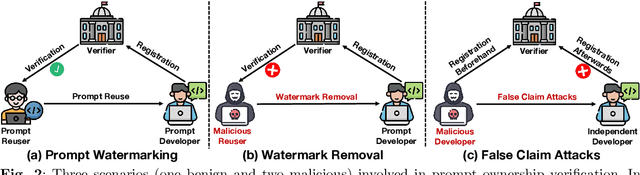
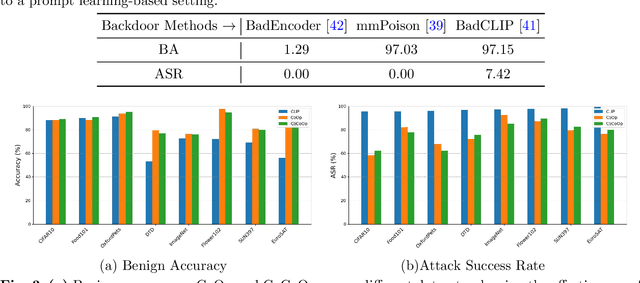
Large-scale vision-language models, especially CLIP, have demonstrated remarkable performance across diverse downstream tasks. Soft prompts, as carefully crafted modules that efficiently adapt vision-language models to specific tasks, necessitate effective copyright protection. In this paper, we investigate model copyright protection by auditing whether suspicious third-party models incorporate protected soft prompts. While this can be viewed as a special case of model ownership auditing, our analysis shows that existing techniques are ineffective due to prompt learning's unique characteristics. Non-intrusive auditing is inherently prone to false positives when independent models share similar data distributions with victim models. Intrusive approaches also fail: backdoor methods designed for CLIP cannot embed functional triggers, while extending traditional DNN backdoor techniques to prompt learning suffers from harmfulness and ambiguity challenges. We find that these failures in intrusive auditing stem from the same fundamental reason: watermarking operates within the same decision space as the primary task yet pursues opposing objectives. Motivated by these findings, we propose sequential watermarking for soft prompts (SWAP), which implants watermarks into a different and more complex space. SWAP encodes watermarks through a specific order of defender-specified out-of-distribution classes, inspired by the zero-shot prediction capability of CLIP. This watermark, which is embedded in a more complex space, keeps the original prediction label unchanged, making it less opposed to the primary task. We further design a hypothesis-test-guided verification protocol for SWAP and provide theoretical analyses of success conditions. Extensive experiments on 11 datasets demonstrate SWAP's effectiveness, harmlessness, and robustness against potential adaptive attacks.
Prompt-Consistency Image Generation (PCIG): A Unified Framework Integrating LLMs, Knowledge Graphs, and Controllable Diffusion Models
Jun 24, 2024



The rapid advancement of Text-to-Image(T2I) generative models has enabled the synthesis of high-quality images guided by textual descriptions. Despite this significant progress, these models are often susceptible in generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this problem, we introduce a novel diffusion-based framework to significantly enhance the alignment of generated images with their corresponding descriptions, addressing the inconsistency between visual output and textual input. Our framework is built upon a comprehensive analysis of inconsistency phenomena, categorizing them based on their manifestation in the image. Leveraging a state-of-the-art large language module, we first extract objects and construct a knowledge graph to predict the locations of these objects in potentially generated images. We then integrate a state-of-the-art controllable image generation model with a visual text generation module to generate an image that is consistent with the original prompt, guided by the predicted object locations. Through extensive experiments on an advanced multimodal hallucination benchmark, we demonstrate the efficacy of our approach in accurately generating the images without the inconsistency with the original prompt. The code can be accessed via https://github.com/TruthAI-Lab/PCIG.
Sora Detector: A Unified Hallucination Detection for Large Text-to-Video Models
May 07, 2024



The rapid advancement in text-to-video (T2V) generative models has enabled the synthesis of high-fidelity video content guided by textual descriptions. Despite this significant progress, these models are often susceptible to hallucination, generating contents that contradict the input text, which poses a challenge to their reliability and practical deployment. To address this critical issue, we introduce the SoraDetector, a novel unified framework designed to detect hallucinations across diverse large T2V models, including the cutting-edge Sora model. Our framework is built upon a comprehensive analysis of hallucination phenomena, categorizing them based on their manifestation in the video content. Leveraging the state-of-the-art keyframe extraction techniques and multimodal large language models, SoraDetector first evaluates the consistency between extracted video content summary and textual prompts, then constructs static and dynamic knowledge graphs (KGs) from frames to detect hallucination both in single frames and across frames. Sora Detector provides a robust and quantifiable measure of consistency, static and dynamic hallucination. In addition, we have developed the Sora Detector Agent to automate the hallucination detection process and generate a complete video quality report for each input video. Lastly, we present a novel meta-evaluation benchmark, T2VHaluBench, meticulously crafted to facilitate the evaluation of advancements in T2V hallucination detection. Through extensive experiments on videos generated by Sora and other large T2V models, we demonstrate the efficacy of our approach in accurately detecting hallucinations. The code and dataset can be accessed via GitHub.