 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmoZone-Talker: Regional Semantic Control of Audio-Driven 3DGS Talking Heads via Facial Action Units
Jun 14, 20263D Gaussian Splatting (3DGS) has shown strong potential for high-fidelity talking head synthesis. However, enabling fine-grained, interpretable, and editable facial expression control remains fundamentally challenging due to intrinsic conflicts between speech-driven facial dynamics and explicit expression signals. Existing methods rely on implicit multimodal fusion, leading to spatial entanglement and temporal instability. We present EmoZone-Talker, a novel framework that reformulates audio-driven facial animation as a structured spatial-temporal coordination problem under cross-modal conflicts. Our approach introduces an explicit spatial disentanglement and temporal dynamics modeling of facial motion. Specifically, we propose Synergy Zones with Prioritized Attention Bias (SZ-PAB) to explicitly decouple modality contributions via region-wise constraints guided by anatomical priors, and a Channel-Independent Temporal AU Encoder (CIT-AE) to model temporally coherent AU dynamics. By integrating these representations into 3D Gaussian deformation, EmoZone-Talker enables precise and interpretable control over facial expressions. Extensive experiments demonstrate that our method improves expression controllability and realism, with notable gains in upper-face accuracy and temporal coherence, while preserving high rendering quality and accurate lip synchronization. Code will be publicly released to facilitate reproducibility and further research.
WeatherReasonSeg: A Benchmark for Weather-Aware Reasoning Segmentation in Visual Language Models
Mar 18, 2026Existing vision-language models (VLMs) have demonstrated impressive performance in reasoning-based segmentation. However, current benchmarks are primarily constructed from high-quality images captured under idealized conditions. This raises a critical question: when visual cues are severely degraded by adverse weather conditions such as rain, snow, or fog, can VLMs sustain reliable reasoning segmentation capabilities? In response to this challenge, we introduce WeatherReasonSeg, a benchmark designed to evaluate VLM performance in reasoning-based segmentation under adverse weather conditions. It consists of two complementary components. First, we construct a controllable reasoning dataset by applying synthetic weather with varying severity levels to existing segmentation datasets, enabling fine-grained robustness analysis. Second, to capture real-world complexity, we curate a real-world adverse-weather reasoning segmentation dataset with semantically consistent queries generated via mask-guided LLM prompting. We further broaden the evaluation scope across five reasoning dimensions, including functionality, application scenarios, structural attributes, interactions, and requirement matching. Extensive experiments across diverse VLMs reveal two key findings: (1) VLM performance degrades monotonically with increasing weather severity, and (2) different weather types induce distinct vulnerability patterns. We hope WeatherReasonSeg will serve as a foundation for advancing robust, weather-aware reasoning.
Sequential Service Region Design with Capacity-Constrained Investment and Spillover Effect
Mar 09, 2026Service region design determines the geographic coverage of service networks, shaping long-term operational performance. Capital and operational constraints preclude simultaneous large-scale deployment, requiring expansion to proceed sequentially. The resulting challenge is to determine when and where to invest under demand uncertainty, balancing intertemporal trade-offs between early and delayed investment and accounting for network effects whereby each deployment reshapes future demand through inter-regional connectivity. This study addresses a sequential service region design (SSRD) problem incorporating two practical yet underexplored factors: a $k$-region constraint that limits the number of regions investable per period and a stochastic spillover effect linking investment decisions to demand evolution. The resulting problem requires sequencing regional portfolios under uncertainty, leading to a combinatorial explosion in feasible investment sequences. To address this challenge, we propose a solution framework that integrates real options analysis (ROA) with a Transformer-based Proximal Policy Optimization (TPPO) algorithm. ROA evaluates the intertemporal option value of investment sequences, while TPPO learns sequential policies that directly generate high option-value sequences without exhaustive enumeration. Numerical experiments on realistic multi-region settings demonstrate that TPPO converges faster than benchmark DRL methods and consistently identifies sequences with superior option value. Case studies and sensitivity analyses further confirm robustness and provide insights on investment concurrency, regional prioritization, and the increasing benefits of adaptive expansion via our approach under stronger spillovers and dynamic market conditions.
AI-generated data contamination erodes pathological variability and diagnostic reliability
Jan 21, 2026Generative artificial intelligence (AI) is rapidly populating medical records with synthetic content, creating a feedback loop where future models are increasingly at risk of training on uncurated AI-generated data. However, the clinical consequences of this AI-generated data contamination remain unexplored. Here, we show that in the absence of mandatory human verification, this self-referential cycle drives a rapid erosion of pathological variability and diagnostic reliability. By analysing more than 800,000 synthetic data points across clinical text generation, vision-language reporting, and medical image synthesis, we find that models progressively converge toward generic phenotypes regardless of the model architecture. Specifically, rare but critical findings, including pneumothorax and effusions, vanish from the synthetic content generated by AI models, while demographic representations skew heavily toward middle-aged male phenotypes. Crucially, this degradation is masked by false diagnostic confidence; models continue to issue reassuring reports while failing to detect life-threatening pathology, with false reassurance rates tripling to 40%. Blinded physician evaluation confirms that this decoupling of confidence and accuracy renders AI-generated documentation clinically useless after just two generations. We systematically evaluate three mitigation strategies, finding that while synthetic volume scaling fails to prevent collapse, mixing real data with quality-aware filtering effectively preserves diversity. Ultimately, our results suggest that without policy-mandated human oversight, the deployment of generative AI threatens to degrade the very healthcare data ecosystems it relies upon.
RGB-to-Polarization Estimation: A New Task and Benchmark Study
May 19, 2025Polarization images provide rich physical information that is fundamentally absent from standard RGB images, benefiting a wide range of computer vision applications such as reflection separation and material classification. However, the acquisition of polarization images typically requires additional optical components, which increases both the cost and the complexity of the applications. To bridge this gap, we introduce a new task: RGB-to-polarization image estimation, which aims to infer polarization information directly from RGB images. In this work, we establish the first comprehensive benchmark for this task by leveraging existing polarization datasets and evaluating a diverse set of state-of-the-art deep learning models, including both restoration-oriented and generative architectures. Through extensive quantitative and qualitative analysis, our benchmark not only establishes the current performance ceiling of RGB-to-polarization estimation, but also systematically reveals the respective strengths and limitations of different model families -- such as direct reconstruction versus generative synthesis, and task-specific training versus large-scale pre-training. In addition, we provide some potential directions for future research on polarization estimation. This benchmark is intended to serve as a foundational resource to facilitate the design and evaluation of future methods for polarization estimation from standard RGB inputs.
Auto-Bench: An Automated Benchmark for Scientific Discovery in LLMs
Feb 21, 2025Given the remarkable performance of Large Language Models (LLMs), an important question arises: Can LLMs conduct human-like scientific research and discover new knowledge, and act as an AI scientist? Scientific discovery is an iterative process that demands efficient knowledge updating and encoding. It involves understanding the environment, identifying new hypotheses, and reasoning about actions; however, no standardized benchmark specifically designed for scientific discovery exists for LLM agents. In response to these limitations, we introduce a novel benchmark, \textit{Auto-Bench}, that encompasses necessary aspects to evaluate LLMs for scientific discovery in both natural and social sciences. Our benchmark is based on the principles of causal graph discovery. It challenges models to uncover hidden structures and make optimal decisions, which includes generating valid justifications. By engaging interactively with an oracle, the models iteratively refine their understanding of underlying interactions, the chemistry and social interactions, through strategic interventions. We evaluate state-of-the-art LLMs, including GPT-4, Gemini, Qwen, Claude, and Llama, and observe a significant performance drop as the problem complexity increases, which suggests an important gap between machine and human intelligence that future development of LLMs need to take into consideration.
A Survey of Embodied AI in Healthcare: Techniques, Applications, and Opportunities
Jan 13, 2025



Healthcare systems worldwide face persistent challenges in efficiency, accessibility, and personalization. Powered by modern AI technologies such as multimodal large language models and world models, Embodied AI (EmAI) represents a transformative frontier, offering enhanced autonomy and the ability to interact with the physical world to address these challenges. As an interdisciplinary and rapidly evolving research domain, "EmAI in healthcare" spans diverse fields such as algorithms, robotics, and biomedicine. This complexity underscores the importance of timely reviews and analyses to track advancements, address challenges, and foster cross-disciplinary collaboration. In this paper, we provide a comprehensive overview of the "brain" of EmAI for healthcare, wherein we introduce foundational AI algorithms for perception, actuation, planning, and memory, and focus on presenting the healthcare applications spanning clinical interventions, daily care & companionship, infrastructure support, and biomedical research. Despite its promise, the development of EmAI for healthcare is hindered by critical challenges such as safety concerns, gaps between simulation platforms and real-world applications, the absence of standardized benchmarks, and uneven progress across interdisciplinary domains. We discuss the technical barriers and explore ethical considerations, offering a forward-looking perspective on the future of EmAI in healthcare. A hierarchical framework of intelligent levels for EmAI systems is also introduced to guide further development. By providing systematic insights, this work aims to inspire innovation and practical applications, paving the way for a new era of intelligent, patient-centered healthcare.
FAMMA: A Benchmark for Financial Domain Multilingual Multimodal Question Answering
Oct 06, 2024



In this paper, we introduce FAMMA, an open-source benchmark for financial multilingual multimodal question answering (QA). Our benchmark aims to evaluate the abilities of multimodal large language models (MLLMs) in answering questions that require advanced financial knowledge and sophisticated reasoning. It includes 1,758 meticulously collected question-answer pairs from university textbooks and exams, spanning 8 major subfields in finance including corporate finance, asset management, and financial engineering. Some of the QA pairs are written in Chinese or French, while a majority of them are in English. These questions are presented in a mixed format combining text and heterogeneous image types, such as charts, tables, and diagrams. We evaluate a range of state-of-the-art MLLMs on our benchmark, and our analysis shows that FAMMA poses a significant challenge for these models. Even advanced systems like GPT-4o and Claude-35-Sonnet achieve only 42\% accuracy. Additionally, the open-source Qwen2-VL lags notably behind its proprietary counterparts. Lastly, we explore GPT o1-style reasoning chains to enhance the models' reasoning capabilities, which significantly improve error correction. Our FAMMA benchmark will facilitate future research to develop expert systems in financial QA. The leaderboard is available at https://famma-bench.github.io/famma/ .
Predicting Rental Price of Lane Houses in Shanghai with Machine Learning Methods and Large Language Models
May 26, 2024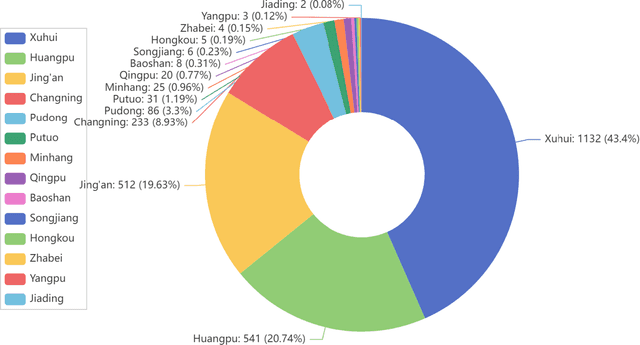
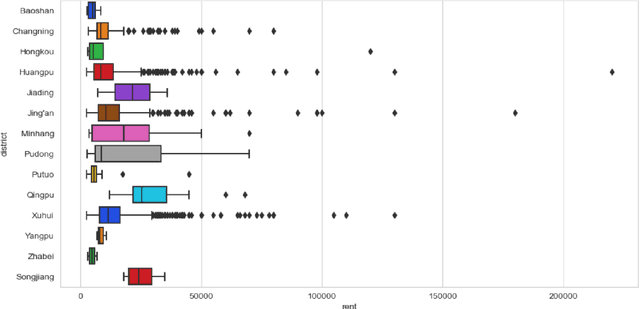
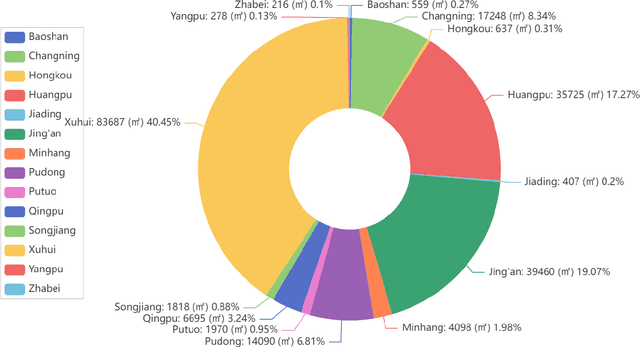
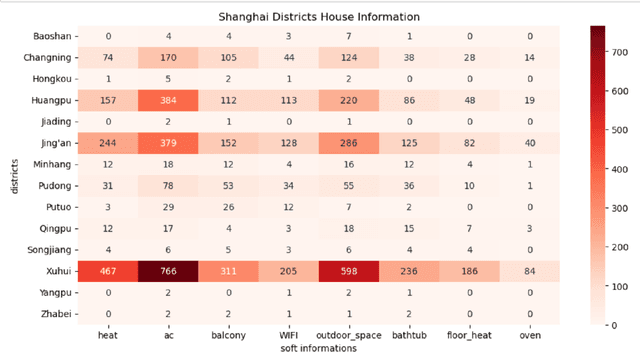
Housing has emerged as a crucial concern among young individuals residing in major cities, including Shanghai. Given the unprecedented surge in property prices in this metropolis, young people have increasingly resorted to the rental market to address their housing needs. This study utilizes five traditional machine learning methods: multiple linear regression (MLR), ridge regression (RR), lasso regression (LR), decision tree (DT), and random forest (RF), along with a Large Language Model (LLM) approach using ChatGPT, for predicting the rental prices of lane houses in Shanghai. It applies these methods to examine a public data sample of about 2,609 lane house rental transactions in 2021 in Shanghai, and then compares the results of these methods. In terms of predictive power, RF has achieved the best performance among the traditional methods. However, the LLM approach, particularly in the 10-shot scenario, shows promising results that surpass traditional methods in terms of R-Squared value. The three performance metrics: mean squared error (MSE), mean absolute error (MAE), and R-Squared, are used to evaluate the models. Our conclusion is that while traditional machine learning models offer robust techniques for rental price prediction, the integration of LLM such as ChatGPT holds significant potential for enhancing predictive accuracy.
PoCo: A Self-Supervised Approach via Polar Transformation Based Progressive Contrastive Learning for Ophthalmic Disease Diagnosis
Mar 28, 2024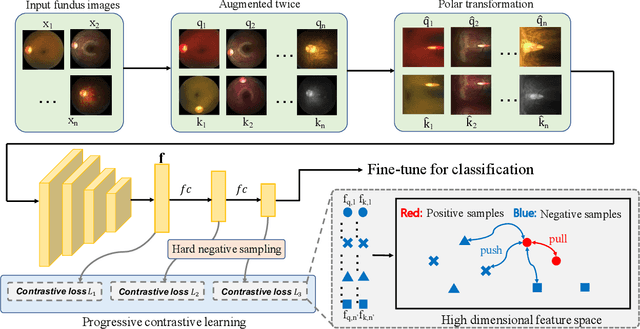
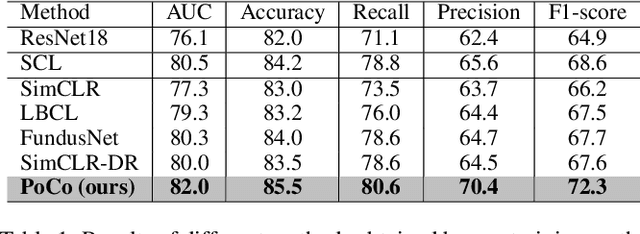


Automatic ophthalmic disease diagnosis on fundus images is important in clinical practice. However, due to complex fundus textures and limited annotated data, developing an effective automatic method for this problem is still challenging. In this paper, we present a self-supervised method via polar transformation based progressive contrastive learning, called PoCo, for ophthalmic disease diagnosis. Specifically, we novelly inject the polar transformation into contrastive learning to 1) promote contrastive learning pre-training to be faster and more stable and 2) naturally capture task-free and rotation-related textures, which provides insights into disease recognition on fundus images. Beneficially, simple normal translation-invariant convolution on transformed images can equivalently replace the complex rotation-invariant and sector convolution on raw images. After that, we develop a progressive contrastive learning method to efficiently utilize large unannotated images and a novel progressive hard negative sampling scheme to gradually reduce the negative sample number for efficient training and performance enhancement. Extensive experiments on three public ophthalmic disease datasets show that our PoCo achieves state-of-the-art performance with good generalization ability, validating that our method can reduce annotation efforts and provide reliable diagnosis. Codes are available at \url{https://github.com/wjh892521292/PoCo}.