 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHDMoE: A Hierarchical Decoupling-Fusion Mixture-of-Experts Framework for Multimodal Cancer Survival Prediction
May 20, 2026Multimodal survival prediction, a crucial yet challenging task, demands the integration of multimodal medical data (\eg Whole Slide Images (WSIs) and Genomic Profiles) to achieve accurate prognostic modeling. Given the inherent heterogeneity across modalities, the feature decoupling-fusion paradigm has emerged as a dominant approach. However, these methods have the following shortcomings: (1) fail to reduce the redundant information of modality features before decoupling, which negatively affects the feature decoupling and fusion effect;(2) lack the ability to model the fine-grained relationships of the features and capture the local information interactions between intra- and inter-modality features. To address these issues, we propose a \underline{H}ierarchical \underline{D}ecoupling-Fusion \underline{M}ixture-\underline{o}f-\underline{E}xperts (HDMoE) framework with two levels of MoE and \underline{R}andom \underline{F}eature \underline{R}eorganization (RFR) modules.In the first-level MoE, shared experts and routed experts are employed to remove redundant information and extract fine-grained specific features within each modality, while the second-level MoE facilitates fine-grained inter-modality feature decoupling. Besides, we design two RFR modules following each level of MoE to finely fuse intra- and inter-modality features, which can help the model capture more fine-grained relationships between modalities. Extensive experimental results on our private Liver Cancer (LC) and three TCGA public datasets confirm the effectiveness of our proposed method. Codes are available at https://github.com/ZJUMAI/HDMoE.
Versatile and Risk-Sensitive Cardiac Diagnosis via Graph-Based ECG Signal Representation
Nov 11, 2025Despite the rapid advancements of electrocardiogram (ECG) signal diagnosis and analysis methods through deep learning, two major hurdles still limit their clinical adoption: the lack of versatility in processing ECG signals with diverse configurations, and the inadequate detection of risk signals due to sample imbalances. Addressing these challenges, we introduce VersAtile and Risk-Sensitive cardiac diagnosis (VARS), an innovative approach that employs a graph-based representation to uniformly model heterogeneous ECG signals. VARS stands out by transforming ECG signals into versatile graph structures that capture critical diagnostic features, irrespective of signal diversity in the lead count, sampling frequency, and duration. This graph-centric formulation also enhances diagnostic sensitivity, enabling precise localization and identification of abnormal ECG patterns that often elude standard analysis methods. To facilitate representation transformation, our approach integrates denoising reconstruction with contrastive learning to preserve raw ECG information while highlighting pathognomonic patterns. We rigorously evaluate the efficacy of VARS on three distinct ECG datasets, encompassing a range of structural variations. The results demonstrate that VARS not only consistently surpasses existing state-of-the-art models across all these datasets but also exhibits substantial improvement in identifying risk signals. Additionally, VARS offers interpretability by pinpointing the exact waveforms that lead to specific model outputs, thereby assisting clinicians in making informed decisions. These findings suggest that our VARS will likely emerge as an invaluable tool for comprehensive cardiac health assessment.
SSPO: Self-traced Step-wise Preference Optimization for Process Supervision and Reasoning Compression
Aug 18, 2025Test-time scaling has proven effective in further enhancing the performance of pretrained Large Language Models (LLMs). However, mainstream post-training methods (i.e., reinforcement learning (RL) with chain-of-thought (CoT) reasoning) often incur substantial computational overhead due to auxiliary models and overthinking. In this paper, we empirically reveal that the incorrect answers partially stem from verbose reasoning processes lacking correct self-fix, where errors accumulate across multiple reasoning steps. To this end, we propose Self-traced Step-wise Preference Optimization (SSPO), a pluggable RL process supervision framework that enables fine-grained optimization of each reasoning step. Specifically, SSPO requires neither auxiliary models nor stepwise manual annotations. Instead, it leverages step-wise preference signals generated by the model itself to guide the optimization process for reasoning compression. Experiments demonstrate that the generated reasoning sequences from SSPO are both accurate and succinct, effectively mitigating overthinking behaviors without compromising model performance across diverse domains and languages.
Large language models could be rote learners
Apr 15, 2025
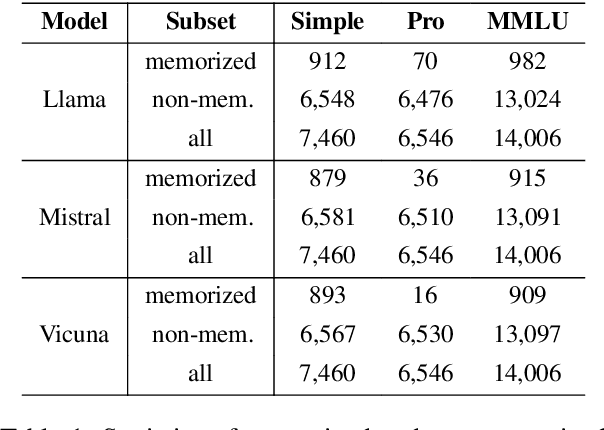
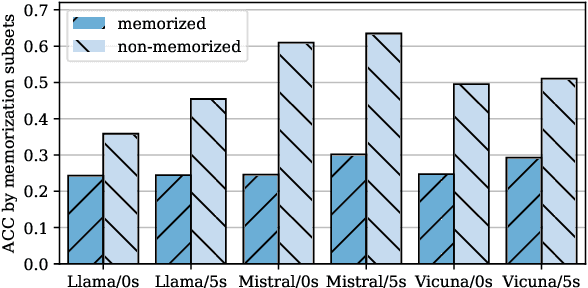

Multiple-choice question (MCQ) benchmarks are widely used for evaluating Large Language Models (LLMs), yet their reliability is undermined by benchmark contamination. In this study, we reframe contamination as an inherent aspect of learning and seek to disentangle genuine capability acquisition from superficial memorization in LLM evaluation. First, by analyzing model performance under different memorization conditions, we uncover a counterintuitive trend: LLMs perform worse on memorized MCQs than on non-memorized ones, indicating the coexistence of two distinct learning phenomena, i.e., rote memorization and genuine capability learning. To disentangle them, we propose TrinEval, a novel evaluation framework that reformulates MCQs into an alternative trinity format, reducing memorization while preserving knowledge assessment. Experiments validate TrinEval's effectiveness in reformulation, and its evaluation reveals that common LLMs may memorize by rote 20.5% of knowledge points (in MMLU on average).
LLMs Can Simulate Standardized Patients via Agent Coevolution
Dec 16, 2024Training medical personnel using standardized patients (SPs) remains a complex challenge, requiring extensive domain expertise and role-specific practice. Most research on Large Language Model (LLM)-based simulated patients focuses on improving data retrieval accuracy or adjusting prompts through human feedback. However, this focus has overlooked the critical need for patient agents to learn a standardized presentation pattern that transforms data into human-like patient responses through unsupervised simulations. To address this gap, we propose EvoPatient, a novel simulated patient framework in which a patient agent and doctor agents simulate the diagnostic process through multi-turn dialogues, simultaneously gathering experience to improve the quality of both questions and answers, ultimately enabling human doctor training. Extensive experiments on various cases demonstrate that, by providing only overall SP requirements, our framework improves over existing reasoning methods by more than 10% in requirement alignment and better human preference, while achieving an optimal balance of resource consumption after evolving over 200 cases for 10 hours, with excellent generalizability. The code will be available at https://github.com/ZJUMAI/EvoPatient.
Fair Evaluation of Federated Learning Algorithms for Automated Breast Density Classification: The Results of the 2022 ACR-NCI-NVIDIA Federated Learning Challenge
May 22, 2024The correct interpretation of breast density is important in the assessment of breast cancer risk. AI has been shown capable of accurately predicting breast density, however, due to the differences in imaging characteristics across mammography systems, models built using data from one system do not generalize well to other systems. Though federated learning (FL) has emerged as a way to improve the generalizability of AI without the need to share data, the best way to preserve features from all training data during FL is an active area of research. To explore FL methodology, the breast density classification FL challenge was hosted in partnership with the American College of Radiology, Harvard Medical School's Mass General Brigham, University of Colorado, NVIDIA, and the National Institutes of Health National Cancer Institute. Challenge participants were able to submit docker containers capable of implementing FL on three simulated medical facilities, each containing a unique large mammography dataset. The breast density FL challenge ran from June 15 to September 5, 2022, attracting seven finalists from around the world. The winning FL submission reached a linear kappa score of 0.653 on the challenge test data and 0.413 on an external testing dataset, scoring comparably to a model trained on the same data in a central location.
* 16 pages, 9 figures
PoCo: A Self-Supervised Approach via Polar Transformation Based Progressive Contrastive Learning for Ophthalmic Disease Diagnosis
Mar 28, 2024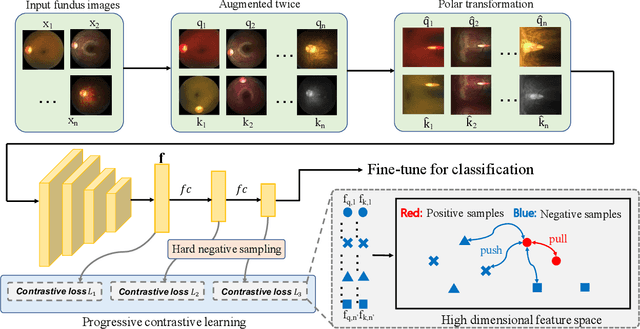
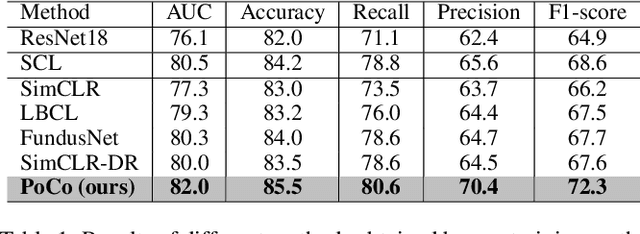


Automatic ophthalmic disease diagnosis on fundus images is important in clinical practice. However, due to complex fundus textures and limited annotated data, developing an effective automatic method for this problem is still challenging. In this paper, we present a self-supervised method via polar transformation based progressive contrastive learning, called PoCo, for ophthalmic disease diagnosis. Specifically, we novelly inject the polar transformation into contrastive learning to 1) promote contrastive learning pre-training to be faster and more stable and 2) naturally capture task-free and rotation-related textures, which provides insights into disease recognition on fundus images. Beneficially, simple normal translation-invariant convolution on transformed images can equivalently replace the complex rotation-invariant and sector convolution on raw images. After that, we develop a progressive contrastive learning method to efficiently utilize large unannotated images and a novel progressive hard negative sampling scheme to gradually reduce the negative sample number for efficient training and performance enhancement. Extensive experiments on three public ophthalmic disease datasets show that our PoCo achieves state-of-the-art performance with good generalization ability, validating that our method can reduce annotation efforts and provide reliable diagnosis. Codes are available at \url{https://github.com/wjh892521292/PoCo}.
SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity
Oct 30, 2023



To address the challenge of increasing network size, researchers have developed sparse models through network pruning. However, maintaining model accuracy while achieving significant speedups on general computing devices remains an open problem. In this paper, we present a novel mobile inference acceleration framework SparseByteNN, which leverages fine-grained kernel sparsity to achieve real-time execution as well as high accuracy. Our framework consists of two parts: (a) A fine-grained kernel sparsity schema with a sparsity granularity between structured pruning and unstructured pruning. It designs multiple sparse patterns for different operators. Combined with our proposed whole network rearrangement strategy, the schema achieves a high compression rate and high precision at the same time. (b) Inference engine co-optimized with the sparse pattern. The conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet-v1 outperform strong dense baselines on the efficiency-accuracy curve. Experimental results on Qualcomm 855 show that for 30% sparse MobileNet-v1, SparseByteNN achieves 1.27x speedup over the dense version and 1.29x speedup over the state-of-the-art sparse inference engine MNN with a slight accuracy drop of 0.224%. The source code of SparseByteNN will be available at https://github.com/lswzjuer/SparseByteNN