 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTAP: A Token-Adaptive Predictor Framework for Training-Free Diffusion Acceleration
Mar 04, 2026Diffusion models achieve strong generative performance but remain slow at inference due to the need for repeated full-model denoising passes. We present Token-Adaptive Predictor (TAP), a training-free, probe-driven framework that adaptively selects a predictor for each token at every sampling step. TAP uses a single full evaluation of the model's first layer as a low-cost probe to compute proxy losses for a compact family of candidate predictors (instantiated primarily with Taylor expansions of varying order and horizon), then assigns each token the predictor with the smallest proxy error. This per-token "probe-then-select" strategy exploits heterogeneous temporal dynamics, requires no additional training, and is compatible with various predictor designs. TAP incurs negligible overhead while enabling large speedups with little or no perceptual quality loss. Extensive experiments across multiple diffusion architectures and generation tasks show that TAP substantially improves the accuracy-efficiency frontier compared to fixed global predictors and caching-only baselines.
S2O: Early Stopping for Sparse Attention via Online Permutation
Feb 26, 2026Attention scales quadratically with sequence length, fundamentally limiting long-context inference. Existing block-granularity sparsification can reduce latency, but coarse blocks impose an intrinsic sparsity ceiling, making further improvements difficult even with carefully engineered designs. We present S2O, which performs early stopping for sparse attention via online permutation. Inspired by virtual-to-physical address mapping in memory systems, S2O revisits and factorizes FlashAttention execution, enabling inference to load non-contiguous tokens rather than a contiguous span in the original order. Motivated by fine-grained structures in attention heatmaps, we transform explicit permutation into an online, index-guided, discrete loading policy; with extremely lightweight preprocessing and index-remapping overhead, it concentrates importance on a small set of high-priority blocks. Building on this importance-guided online permutation for loading, S2O further introduces an early-stopping rule: computation proceeds from high to low importance; once the current block score falls below a threshold, S2O terminates early and skips the remaining low-contribution blocks, thereby increasing effective sparsity and reducing computation under a controlled error budget. As a result, S2O substantially raises the practical sparsity ceiling. On Llama-3.1-8B under a 128K context, S2O reduces single-operator MSE by 3.82$\times$ at matched sparsity, and reduces prefill compute density by 3.31$\times$ at matched MSE; meanwhile, it preserves end-to-end accuracy and achieves 7.51$\times$ attention and 3.81$\times$ end-to-end speedups.
Train Short, Inference Long: Training-free Horizon Extension for Autoregressive Video Generation
Feb 17, 2026Autoregressive video diffusion models have emerged as a scalable paradigm for long video generation. However, they often suffer from severe extrapolation failure, where rapid error accumulation leads to significant temporal degradation when extending beyond training horizons. We identify that this failure primarily stems from the spectral bias of 3D positional embeddings and the lack of dynamic priors in noise sampling. To address these issues, we propose FLEX (Frequency-aware Length EXtension), a training-free inference-time framework that bridges the gap between short-term training and long-term inference. FLEX introduces Frequency-aware RoPE Modulation to adaptively interpolate under-trained low-frequency components while extrapolating high-frequency ones to preserve multi-scale temporal discriminability. This is integrated with Antiphase Noise Sampling (ANS) to inject high-frequency dynamic priors and Inference-only Attention Sink to anchor global structure. Extensive evaluations on VBench demonstrate that FLEX significantly outperforms state-of-the-art models at 6x extrapolation (30s duration) and matches the performance of long-video fine-tuned baselines at 12x scale (60s duration). As a plug-and-play augmentation, FLEX seamlessly integrates into existing inference pipelines for horizon extension. It effectively pushes the generation limits of models such as LongLive, supporting consistent and dynamic video synthesis at a 4-minute scale. Project page is available at https://ga-lee.github.io/FLEX_demo.
NextFlow: Unified Sequential Modeling Activates Multimodal Understanding and Generation
Jan 05, 2026We present NextFlow, a unified decoder-only autoregressive transformer trained on 6 trillion interleaved text-image discrete tokens. By leveraging a unified vision representation within a unified autoregressive architecture, NextFlow natively activates multimodal understanding and generation capabilities, unlocking abilities of image editing, interleaved content and video generation. Motivated by the distinct nature of modalities - where text is strictly sequential and images are inherently hierarchical - we retain next-token prediction for text but adopt next-scale prediction for visual generation. This departs from traditional raster-scan methods, enabling the generation of 1024x1024 images in just 5 seconds - orders of magnitude faster than comparable AR models. We address the instabilities of multi-scale generation through a robust training recipe. Furthermore, we introduce a prefix-tuning strategy for reinforcement learning. Experiments demonstrate that NextFlow achieves state-of-the-art performance among unified models and rivals specialized diffusion baselines in visual quality.
GQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Dec 23, 2024
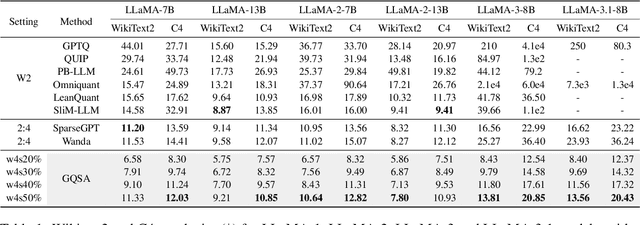
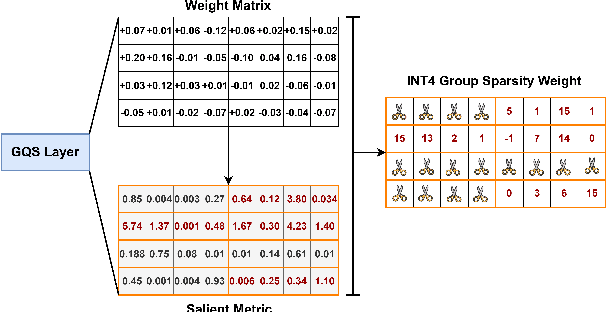
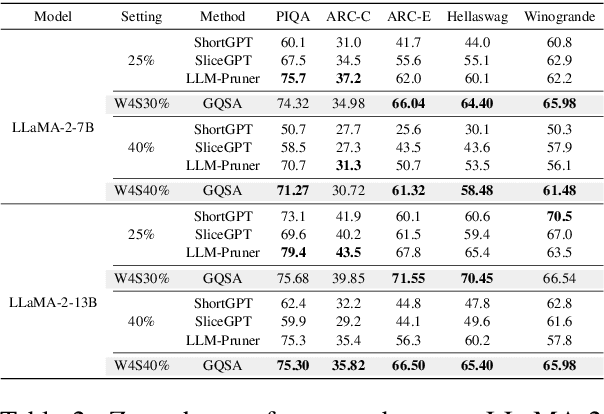
With the rapid growth in the scale and complexity of large language models (LLMs), the costs of training and inference have risen substantially. Model compression has emerged as a mainstream solution to reduce memory usage and computational overhead. This paper presents Group Quantization and Sparse Acceleration (\textbf{GQSA}), a novel compression technique tailored for LLMs. Traditional methods typically focus exclusively on either quantization or sparsification, but relying on a single strategy often results in significant performance loss at high compression rates. In contrast, GQSA integrates quantization and sparsification in a tightly coupled manner, leveraging GPU-friendly structured group sparsity and quantization for efficient acceleration. The proposed method consists of three key steps. First, GQSA applies group structured pruning to adhere to GPU-friendly sparse pattern constraints. Second, a two-stage sparsity-aware training process is employed to maximize performance retention after compression. Finally, the framework adopts the Block Sparse Row (BSR) format to enable practical deployment and efficient execution. Experimental results on the LLaMA model family show that GQSA achieves an excellent balance between model speed and accuracy. Furthermore, on the latest LLaMA-3 and LLaMA-3.1 models, GQSA outperforms existing LLM compression techniques significantly.
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Aug 16, 2024



Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their practical application is constrained by substantial memory and computational demands. Post-training quantization (PTQ) is considered an effective method to accelerate LLM inference. Despite its growing popularity in LLM model compression, PTQ deployment faces two major challenges. First, low-bit quantization leads to performance degradation. Second, restricted by the limited integer computing unit type on GPUs, quantized matrix operations with different precisions cannot be effectively accelerated. To address these issues, we introduce a novel arbitrary-bit quantization algorithm and inference framework, ABQ-LLM. It achieves superior performance across various quantization settings and enables efficient arbitrary-precision quantized inference on the GPU. ABQ-LLM introduces several key innovations: (1) a distribution correction method for transformer blocks to mitigate distribution differences caused by full quantization of weights and activations, improving performance at low bit-widths. (2) the bit balance strategy to counteract performance degradation from asymmetric distribution issues at very low bit-widths (e.g., 2-bit). (3) an innovative quantization acceleration framework that reconstructs the quantization matrix multiplication of arbitrary precision combinations based on BTC (Binary TensorCore) equivalents, gets rid of the limitations of INT4/INT8 computing units. ABQ-LLM can convert each component bit width gain into actual acceleration gain, maximizing performance under mixed precision(e.g., W6A6, W2A8). Based on W2*A8 quantization configuration on LLaMA-7B model, it achieved a WikiText2 perplexity of 7.59 (2.17$\downarrow $ vs 9.76 in AffineQuant). Compared to SmoothQuant, we realized 1.6$\times$ acceleration improvement and 2.7$\times$ memory compression gain.
FoldGPT: Simple and Effective Large Language Model Compression Scheme
Jul 01, 2024The demand for deploying large language models(LLMs) on mobile devices continues to increase, driven by escalating data security concerns and cloud costs. However, network bandwidth and memory limitations pose challenges for deploying billion-level models on mobile devices. In this study, we investigate the outputs of different layers across various scales of LLMs and found that the outputs of most layers exhibit significant similarity. Moreover, this similarity becomes more pronounced as the model size increases, indicating substantial redundancy in the depth direction of the LLMs. Based on this observation, we propose an efficient model volume compression strategy, termed FoldGPT, which combines block removal and block parameter sharing.This strategy consists of three parts: (1) Based on the learnable gating parameters, we determine the block importance ranking while modeling the coupling effect between blocks. Then we delete some redundant layers based on the given removal rate. (2) For the retained blocks, we apply a specially designed group parameter sharing strategy, where blocks within the same group share identical weights, significantly compressing the number of parameters and slightly reducing latency overhead. (3) After sharing these Blocks, we "cure" the mismatch caused by sparsity with a minor amount of fine-tuning and introduce a tail-layer distillation strategy to improve the performance. Experiments demonstrate that FoldGPT outperforms previous state-of-the-art(SOTA) methods in efficient model compression, demonstrating the feasibility of achieving model lightweighting through straightforward block removal and parameter sharing.
SparseByteNN: A Novel Mobile Inference Acceleration Framework Based on Fine-Grained Group Sparsity
Oct 30, 2023



To address the challenge of increasing network size, researchers have developed sparse models through network pruning. However, maintaining model accuracy while achieving significant speedups on general computing devices remains an open problem. In this paper, we present a novel mobile inference acceleration framework SparseByteNN, which leverages fine-grained kernel sparsity to achieve real-time execution as well as high accuracy. Our framework consists of two parts: (a) A fine-grained kernel sparsity schema with a sparsity granularity between structured pruning and unstructured pruning. It designs multiple sparse patterns for different operators. Combined with our proposed whole network rearrangement strategy, the schema achieves a high compression rate and high precision at the same time. (b) Inference engine co-optimized with the sparse pattern. The conventional wisdom is that this reduction in theoretical FLOPs does not translate into real-world efficiency gains. We aim to correct this misconception by introducing a family of efficient sparse kernels for ARM and WebAssembly. Equipped with our efficient implementation of sparse primitives, we show that sparse versions of MobileNet-v1 outperform strong dense baselines on the efficiency-accuracy curve. Experimental results on Qualcomm 855 show that for 30% sparse MobileNet-v1, SparseByteNN achieves 1.27x speedup over the dense version and 1.29x speedup over the state-of-the-art sparse inference engine MNN with a slight accuracy drop of 0.224%. The source code of SparseByteNN will be available at https://github.com/lswzjuer/SparseByteNN
Unfolding Once is Enough: A Deployment-Friendly Transformer Unit for Super-Resolution
Aug 05, 2023



Recent years have witnessed a few attempts of vision transformers for single image super-resolution (SISR). Since the high resolution of intermediate features in SISR models increases memory and computational requirements, efficient SISR transformers are more favored. Based on some popular transformer backbone, many methods have explored reasonable schemes to reduce the computational complexity of the self-attention module while achieving impressive performance. However, these methods only focus on the performance on the training platform (e.g., Pytorch/Tensorflow) without further optimization for the deployment platform (e.g., TensorRT). Therefore, they inevitably contain some redundant operators, posing challenges for subsequent deployment in real-world applications. In this paper, we propose a deployment-friendly transformer unit, namely UFONE (i.e., UnFolding ONce is Enough), to alleviate these problems. In each UFONE, we introduce an Inner-patch Transformer Layer (ITL) to efficiently reconstruct the local structural information from patches and a Spatial-Aware Layer (SAL) to exploit the long-range dependencies between patches. Based on UFONE, we propose a Deployment-friendly Inner-patch Transformer Network (DITN) for the SISR task, which can achieve favorable performance with low latency and memory usage on both training and deployment platforms. Furthermore, to further boost the deployment efficiency of the proposed DITN on TensorRT, we also provide an efficient substitution for layer normalization and propose a fusion optimization strategy for specific operators. Extensive experiments show that our models can achieve competitive results in terms of qualitative and quantitative performance with high deployment efficiency. Code is available at \url{https://github.com/yongliuy/DITN}.
Residual Local Feature Network for Efficient Super-Resolution
May 16, 2022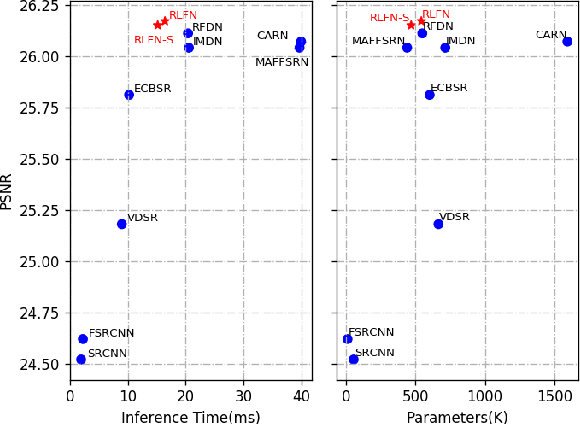
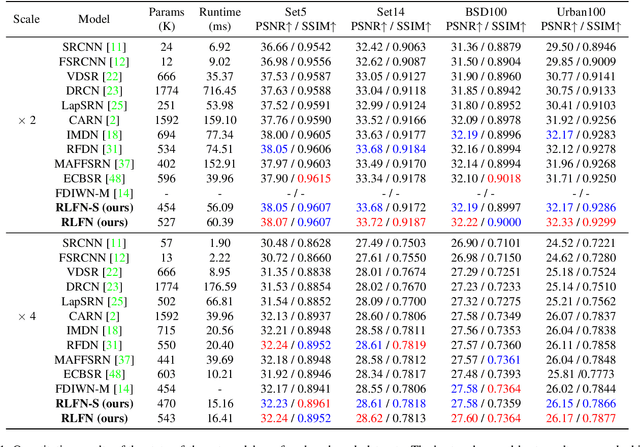
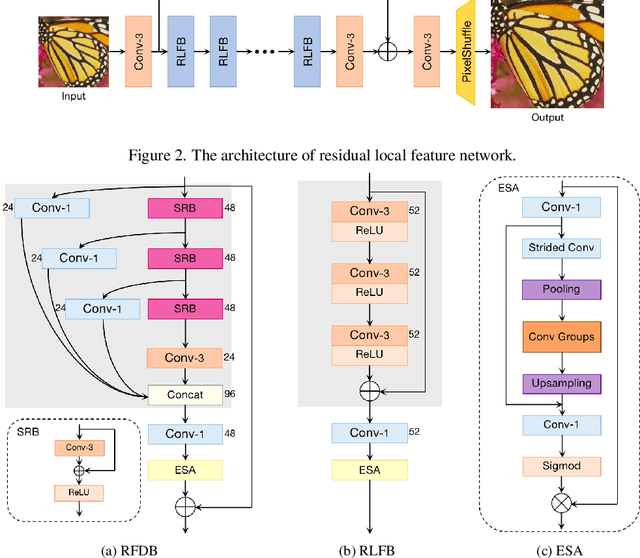
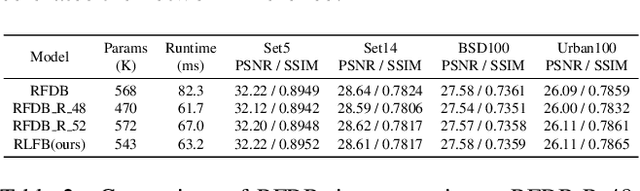
Deep learning based approaches has achieved great performance in single image super-resolution (SISR). However, recent advances in efficient super-resolution focus on reducing the number of parameters and FLOPs, and they aggregate more powerful features by improving feature utilization through complex layer connection strategies. These structures may not be necessary to achieve higher running speed, which makes them difficult to be deployed to resource-constrained devices. In this work, we propose a novel Residual Local Feature Network (RLFN). The main idea is using three convolutional layers for residual local feature learning to simplify feature aggregation, which achieves a good trade-off between model performance and inference time. Moreover, we revisit the popular contrastive loss and observe that the selection of intermediate features of its feature extractor has great influence on the performance. Besides, we propose a novel multi-stage warm-start training strategy. In each stage, the pre-trained weights from previous stages are utilized to improve the model performance. Combined with the improved contrastive loss and training strategy, the proposed RLFN outperforms all the state-of-the-art efficient image SR models in terms of runtime while maintaining both PSNR and SSIM for SR. In addition, we won the first place in the runtime track of the NTIRE 2022 efficient super-resolution challenge. Code will be available at https://github.com/fyan111/RLFN.