 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Aug 16, 2024



Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their practical application is constrained by substantial memory and computational demands. Post-training quantization (PTQ) is considered an effective method to accelerate LLM inference. Despite its growing popularity in LLM model compression, PTQ deployment faces two major challenges. First, low-bit quantization leads to performance degradation. Second, restricted by the limited integer computing unit type on GPUs, quantized matrix operations with different precisions cannot be effectively accelerated. To address these issues, we introduce a novel arbitrary-bit quantization algorithm and inference framework, ABQ-LLM. It achieves superior performance across various quantization settings and enables efficient arbitrary-precision quantized inference on the GPU. ABQ-LLM introduces several key innovations: (1) a distribution correction method for transformer blocks to mitigate distribution differences caused by full quantization of weights and activations, improving performance at low bit-widths. (2) the bit balance strategy to counteract performance degradation from asymmetric distribution issues at very low bit-widths (e.g., 2-bit). (3) an innovative quantization acceleration framework that reconstructs the quantization matrix multiplication of arbitrary precision combinations based on BTC (Binary TensorCore) equivalents, gets rid of the limitations of INT4/INT8 computing units. ABQ-LLM can convert each component bit width gain into actual acceleration gain, maximizing performance under mixed precision(e.g., W6A6, W2A8). Based on W2*A8 quantization configuration on LLaMA-7B model, it achieved a WikiText2 perplexity of 7.59 (2.17$\downarrow $ vs 9.76 in AffineQuant). Compared to SmoothQuant, we realized 1.6$\times$ acceleration improvement and 2.7$\times$ memory compression gain.
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Aug 13, 2024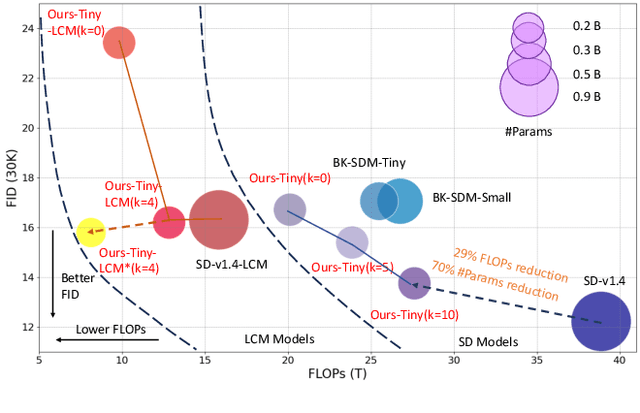
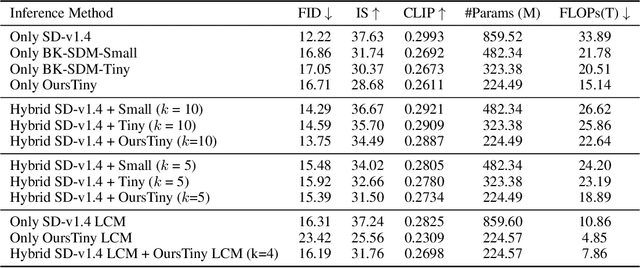
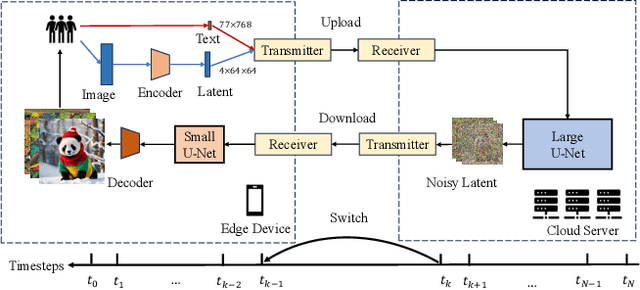
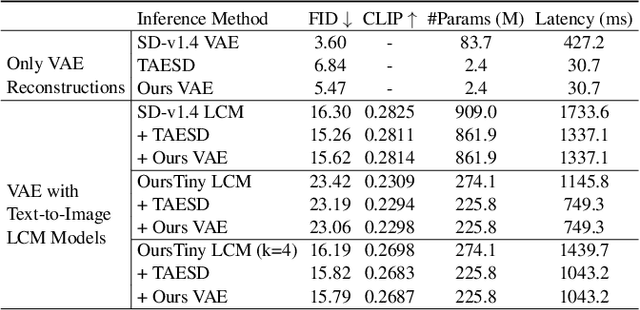
Stable Diffusion Models (SDMs) have shown remarkable proficiency in image synthesis. However, their broad application is impeded by their large model sizes and intensive computational requirements, which typically require expensive cloud servers for deployment. On the flip side, while there are many compact models tailored for edge devices that can reduce these demands, they often compromise on semantic integrity and visual quality when compared to full-sized SDMs. To bridge this gap, we introduce Hybrid SD, an innovative, training-free SDMs inference framework designed for edge-cloud collaborative inference. Hybrid SD distributes the early steps of the diffusion process to the large models deployed on cloud servers, enhancing semantic planning. Furthermore, small efficient models deployed on edge devices can be integrated for refining visual details in the later stages. Acknowledging the diversity of edge devices with differing computational and storage capacities, we employ structural pruning to the SDMs U-Net and train a lightweight VAE. Empirical evaluations demonstrate that our compressed models achieve state-of-the-art parameter efficiency (225.8M) on edge devices with competitive image quality. Additionally, Hybrid SD reduces the cloud cost by 66% with edge-cloud collaborative inference.
Interpreting Deep Learning Model Using Rule-based Method
Oct 15, 2020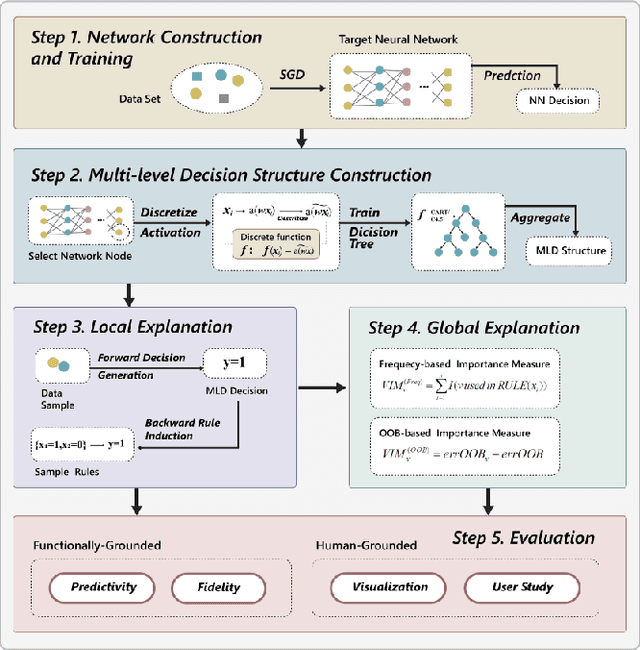
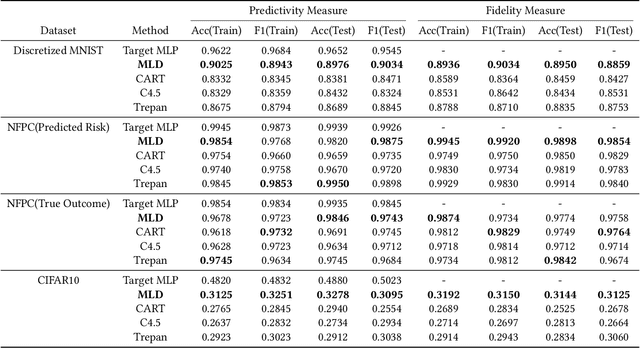
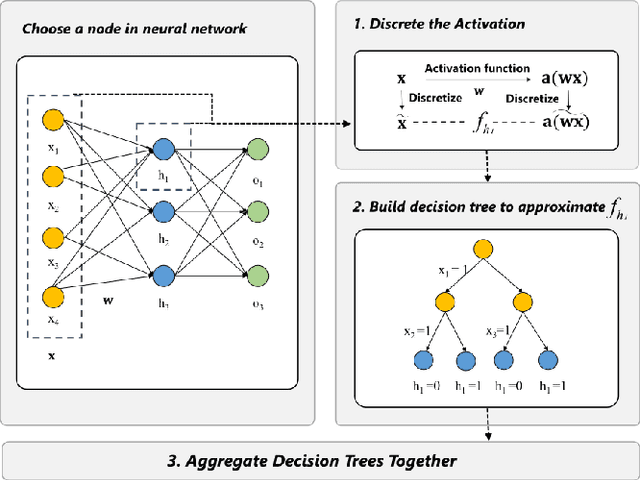
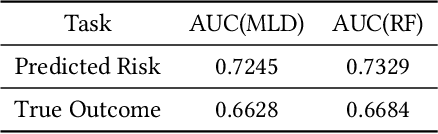
Deep learning models are favored in many research and industry areas and have reached the accuracy of approximating or even surpassing human level. However they've long been considered by researchers as black-box models for their complicated nonlinear property. In this paper, we propose a multi-level decision framework to provide comprehensive interpretation for the deep neural network model. In this multi-level decision framework, by fitting decision trees for each neuron and aggregate them together, a multi-level decision structure (MLD) is constructed at first, which can approximate the performance of the target neural network model with high efficiency and high fidelity. In terms of local explanation for sample, two algorithms are proposed based on MLD structure: forward decision generation algorithm for providing sample decisions, and backward rule induction algorithm for extracting sample rule-mapping recursively. For global explanation, frequency-based and out-of-bag based methods are proposed to extract important features in the neural network decision. Furthermore, experiments on the MNIST and National Free Pre-Pregnancy Check-up (NFPC) dataset are carried out to demonstrate the effectiveness and interpretability of MLD framework. In the evaluation process, both functionally-grounded and human-grounded methods are used to ensure credibility.