 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSVideo: Fast Speed Video Diffusion Model in a Highly-Compressed Latent Space
Feb 02, 2026We introduce FSVideo, a fast speed transformer-based image-to-video (I2V) diffusion framework. We build our framework on the following key components: 1.) a new video autoencoder with highly-compressed latent space ($64\times64\times4$ spatial-temporal downsampling ratio), achieving competitive reconstruction quality; 2.) a diffusion transformer (DIT) architecture with a new layer memory design to enhance inter-layer information flow and context reuse within DIT, and 3.) a multi-resolution generation strategy via a few-step DIT upsampler to increase video fidelity. Our final model, which contains a 14B DIT base model and a 14B DIT upsampler, achieves competitive performance against other popular open-source models, while being an order of magnitude faster. We discuss our model design as well as training strategies in this report.
Vidi: Large Multimodal Models for Video Understanding and Editing
Apr 22, 2025



Humans naturally share information with those they are connected to, and video has become one of the dominant mediums for communication and expression on the Internet. To support the creation of high-quality large-scale video content, a modern pipeline requires a comprehensive understanding of both the raw input materials (e.g., the unedited footage captured by cameras) and the editing components (e.g., visual effects). In video editing scenarios, models must process multiple modalities (e.g., vision, audio, text) with strong background knowledge and handle flexible input lengths (e.g., hour-long raw videos), which poses significant challenges for traditional models. In this report, we introduce Vidi, a family of Large Multimodal Models (LMMs) for a wide range of video understand editing scenarios. The first release focuses on temporal retrieval, i.e., identifying the time ranges within the input videos corresponding to a given text query, which plays a critical role in intelligent editing. The model is capable of processing hour-long videos with strong temporal understanding capability, e.g., retrieve time ranges for certain queries. To support a comprehensive evaluation in real-world scenarios, we also present the VUE-TR benchmark, which introduces five key advancements. 1) Video duration: significantly longer than existing temporal retrival datasets, 2) Audio support: includes audio-based queries, 3) Query format: diverse query lengths/formats, 4) Annotation quality: ground-truth time ranges are manually annotated. 5) Evaluation metric: a refined IoU metric to support evaluation over multiple time ranges. Remarkably, Vidi significantly outperforms leading proprietary models, e.g., GPT-4o and Gemini, on the temporal retrieval task, indicating its superiority in video editing scenarios.
1.58-bit FLUX
Dec 24, 2024We present 1.58-bit FLUX, the first successful approach to quantizing the state-of-the-art text-to-image generation model, FLUX.1-dev, using 1.58-bit weights (i.e., values in {-1, 0, +1}) while maintaining comparable performance for generating 1024 x 1024 images. Notably, our quantization method operates without access to image data, relying solely on self-supervision from the FLUX.1-dev model. Additionally, we develop a custom kernel optimized for 1.58-bit operations, achieving a 7.7x reduction in model storage, a 5.1x reduction in inference memory, and improved inference latency. Extensive evaluations on the GenEval and T2I Compbench benchmarks demonstrate the effectiveness of 1.58-bit FLUX in maintaining generation quality while significantly enhancing computational efficiency.
GQSA: Group Quantization and Sparsity for Accelerating Large Language Model Inference
Dec 23, 2024
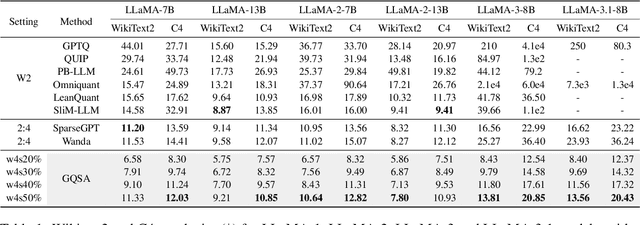
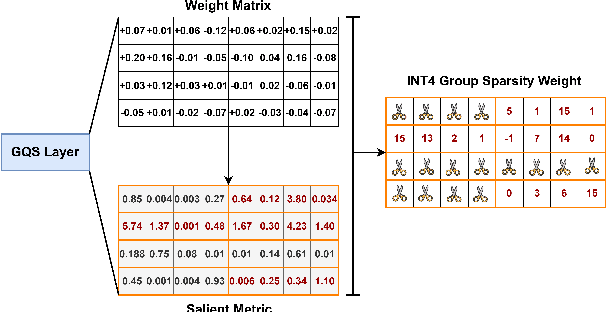
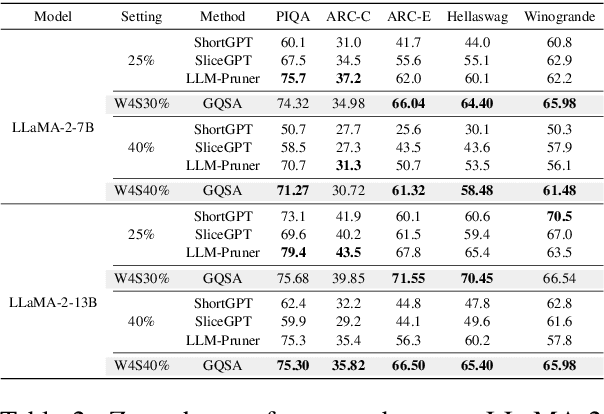
With the rapid growth in the scale and complexity of large language models (LLMs), the costs of training and inference have risen substantially. Model compression has emerged as a mainstream solution to reduce memory usage and computational overhead. This paper presents Group Quantization and Sparse Acceleration (\textbf{GQSA}), a novel compression technique tailored for LLMs. Traditional methods typically focus exclusively on either quantization or sparsification, but relying on a single strategy often results in significant performance loss at high compression rates. In contrast, GQSA integrates quantization and sparsification in a tightly coupled manner, leveraging GPU-friendly structured group sparsity and quantization for efficient acceleration. The proposed method consists of three key steps. First, GQSA applies group structured pruning to adhere to GPU-friendly sparse pattern constraints. Second, a two-stage sparsity-aware training process is employed to maximize performance retention after compression. Finally, the framework adopts the Block Sparse Row (BSR) format to enable practical deployment and efficient execution. Experimental results on the LLaMA model family show that GQSA achieves an excellent balance between model speed and accuracy. Furthermore, on the latest LLaMA-3 and LLaMA-3.1 models, GQSA outperforms existing LLM compression techniques significantly.
ABQ-LLM: Arbitrary-Bit Quantized Inference Acceleration for Large Language Models
Aug 16, 2024



Large Language Models (LLMs) have revolutionized natural language processing tasks. However, their practical application is constrained by substantial memory and computational demands. Post-training quantization (PTQ) is considered an effective method to accelerate LLM inference. Despite its growing popularity in LLM model compression, PTQ deployment faces two major challenges. First, low-bit quantization leads to performance degradation. Second, restricted by the limited integer computing unit type on GPUs, quantized matrix operations with different precisions cannot be effectively accelerated. To address these issues, we introduce a novel arbitrary-bit quantization algorithm and inference framework, ABQ-LLM. It achieves superior performance across various quantization settings and enables efficient arbitrary-precision quantized inference on the GPU. ABQ-LLM introduces several key innovations: (1) a distribution correction method for transformer blocks to mitigate distribution differences caused by full quantization of weights and activations, improving performance at low bit-widths. (2) the bit balance strategy to counteract performance degradation from asymmetric distribution issues at very low bit-widths (e.g., 2-bit). (3) an innovative quantization acceleration framework that reconstructs the quantization matrix multiplication of arbitrary precision combinations based on BTC (Binary TensorCore) equivalents, gets rid of the limitations of INT4/INT8 computing units. ABQ-LLM can convert each component bit width gain into actual acceleration gain, maximizing performance under mixed precision(e.g., W6A6, W2A8). Based on W2*A8 quantization configuration on LLaMA-7B model, it achieved a WikiText2 perplexity of 7.59 (2.17$\downarrow $ vs 9.76 in AffineQuant). Compared to SmoothQuant, we realized 1.6$\times$ acceleration improvement and 2.7$\times$ memory compression gain.
Hybrid SD: Edge-Cloud Collaborative Inference for Stable Diffusion Models
Aug 13, 2024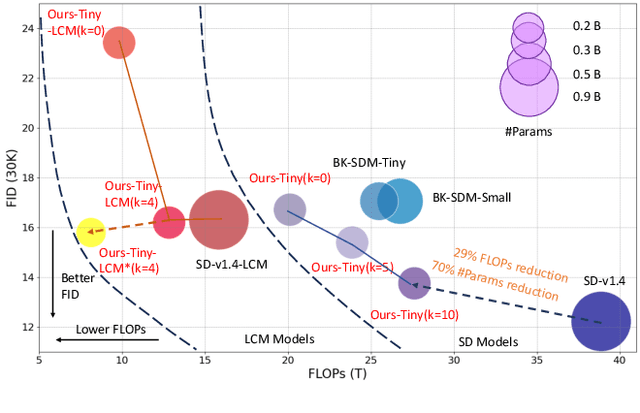
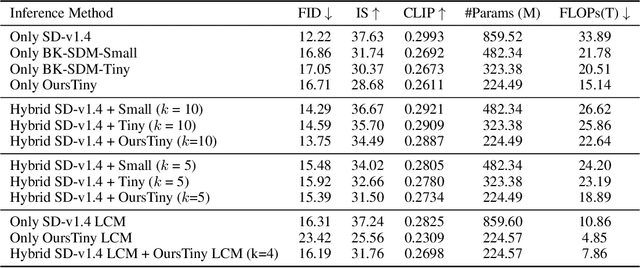
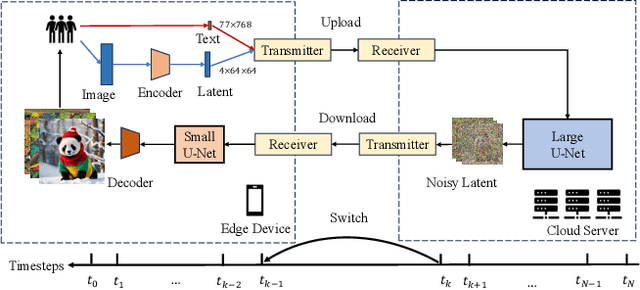
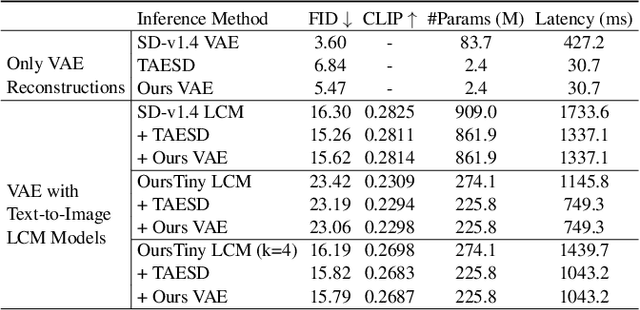
Stable Diffusion Models (SDMs) have shown remarkable proficiency in image synthesis. However, their broad application is impeded by their large model sizes and intensive computational requirements, which typically require expensive cloud servers for deployment. On the flip side, while there are many compact models tailored for edge devices that can reduce these demands, they often compromise on semantic integrity and visual quality when compared to full-sized SDMs. To bridge this gap, we introduce Hybrid SD, an innovative, training-free SDMs inference framework designed for edge-cloud collaborative inference. Hybrid SD distributes the early steps of the diffusion process to the large models deployed on cloud servers, enhancing semantic planning. Furthermore, small efficient models deployed on edge devices can be integrated for refining visual details in the later stages. Acknowledging the diversity of edge devices with differing computational and storage capacities, we employ structural pruning to the SDMs U-Net and train a lightweight VAE. Empirical evaluations demonstrate that our compressed models achieve state-of-the-art parameter efficiency (225.8M) on edge devices with competitive image quality. Additionally, Hybrid SD reduces the cloud cost by 66% with edge-cloud collaborative inference.
FoldGPT: Simple and Effective Large Language Model Compression Scheme
Jul 01, 2024The demand for deploying large language models(LLMs) on mobile devices continues to increase, driven by escalating data security concerns and cloud costs. However, network bandwidth and memory limitations pose challenges for deploying billion-level models on mobile devices. In this study, we investigate the outputs of different layers across various scales of LLMs and found that the outputs of most layers exhibit significant similarity. Moreover, this similarity becomes more pronounced as the model size increases, indicating substantial redundancy in the depth direction of the LLMs. Based on this observation, we propose an efficient model volume compression strategy, termed FoldGPT, which combines block removal and block parameter sharing.This strategy consists of three parts: (1) Based on the learnable gating parameters, we determine the block importance ranking while modeling the coupling effect between blocks. Then we delete some redundant layers based on the given removal rate. (2) For the retained blocks, we apply a specially designed group parameter sharing strategy, where blocks within the same group share identical weights, significantly compressing the number of parameters and slightly reducing latency overhead. (3) After sharing these Blocks, we "cure" the mismatch caused by sparsity with a minor amount of fine-tuning and introduce a tail-layer distillation strategy to improve the performance. Experiments demonstrate that FoldGPT outperforms previous state-of-the-art(SOTA) methods in efficient model compression, demonstrating the feasibility of achieving model lightweighting through straightforward block removal and parameter sharing.
PatchScaler: An Efficient Patch-independent Diffusion Model for Super-Resolution
May 27, 2024



Diffusion models significantly improve the quality of super-resolved images with their impressive content generation capabilities. However, the huge computational costs limit the applications of these methods.Recent efforts have explored reasonable inference acceleration to reduce the number of sampling steps, but the computational cost remains high as each step is performed on the entire image.This paper introduces PatchScaler, a patch-independent diffusion-based single image super-resolution (SR) method, designed to enhance the efficiency of the inference process.The proposed method is motivated by the observation that not all the image patches within an image need the same sampling steps for reconstructing high-resolution images.Based on this observation, we thus develop a Patch-adaptive Group Sampling (PGS) to divide feature patches into different groups according to the patch-level reconstruction difficulty and dynamically assign an appropriate sampling configuration for each group so that the inference speed can be better accelerated.In addition, to improve the denoising ability at each step of the sampling, we develop a texture prompt to guide the estimations of the diffusion model by retrieving high-quality texture priors from a patch-independent reference texture memory.Experiments show that our PatchScaler achieves favorable performance in both quantitative and qualitative evaluations with fast inference speed.Our code and model are available at \url{https://github.com/yongliuy/PatchScaler}.
DynOcc: Learning Single-View Depth from Dynamic Occlusion Cues
Mar 30, 2021
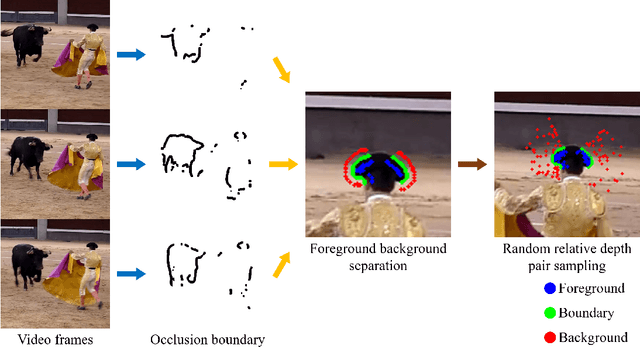
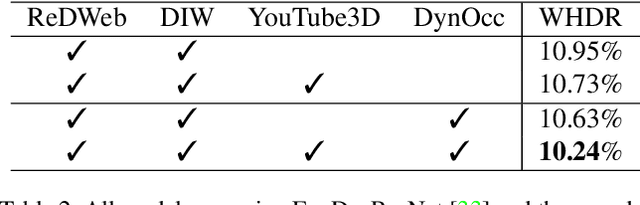
Recently, significant progress has been made in single-view depth estimation thanks to increasingly large and diverse depth datasets. However, these datasets are largely limited to specific application domains (e.g. indoor, autonomous driving) or static in-the-wild scenes due to hardware constraints or technical limitations of 3D reconstruction. In this paper, we introduce the first depth dataset DynOcc consisting of dynamic in-the-wild scenes. Our approach leverages the occlusion cues in these dynamic scenes to infer depth relationships between points of selected video frames. To achieve accurate occlusion detection and depth order estimation, we employ a novel occlusion boundary detection, filtering and thinning scheme followed by a robust foreground/background classification method. In total our DynOcc dataset contains 22M depth pairs out of 91K frames from a diverse set of videos. Using our dataset we achieved state-of-the-art results measured in weighted human disagreement rate (WHDR). We also show that the inferred depth maps trained with DynOcc can preserve sharper depth boundaries.
Effective Label Propagation for Discriminative Semi-Supervised Domain Adaptation
Dec 04, 2020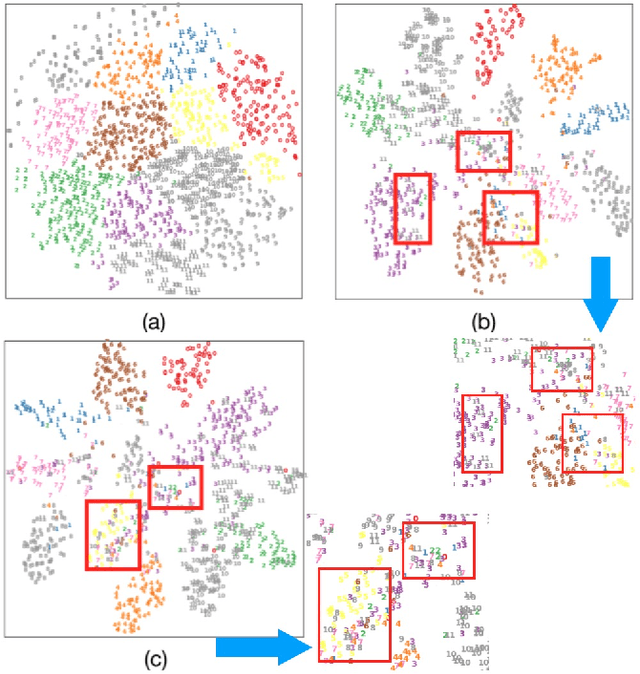
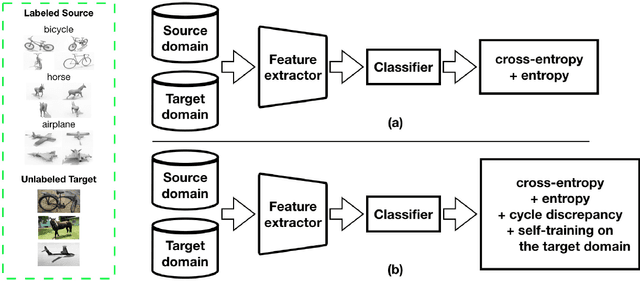
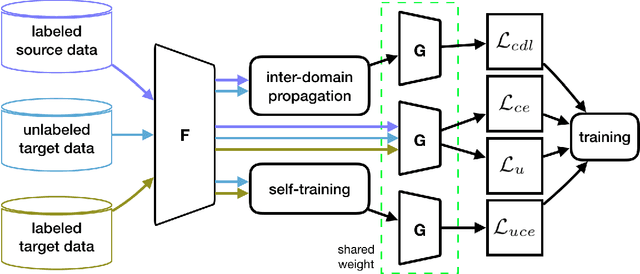
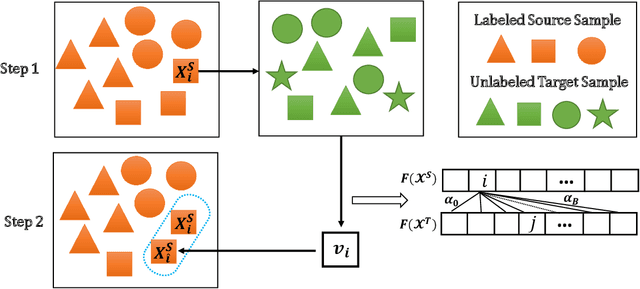
Semi-supervised domain adaptation (SSDA) methods have demonstrated great potential in large-scale image classification tasks when massive labeled data are available in the source domain but very few labeled samples are provided in the target domain. Existing solutions usually focus on feature alignment between the two domains while paying little attention to the discrimination capability of learned representations in the target domain. In this paper, we present a novel and effective method, namely Effective Label Propagation (ELP), to tackle this problem by using effective inter-domain and intra-domain semantic information propagation. For inter-domain propagation, we propose a new cycle discrepancy loss to encourage consistency of semantic information between the two domains. For intra-domain propagation, we propose an effective self-training strategy to mitigate the noises in pseudo-labeled target domain data and improve the feature discriminability in the target domain. As a general method, our ELP can be easily applied to various domain adaptation approaches and can facilitate their feature discrimination in the target domain. Experiments on Office-Home and DomainNet benchmarks show ELP consistently improves the classification accuracy of mainstream SSDA methods by 2%~3%. Additionally, ELP also improves the performance of UDA methods as well (81.5% vs 86.1%), based on UDA experiments on the VisDA-2017 benchmark. Our source code and pre-trained models will be released soon.