 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNTIRE 2022 Challenge on Efficient Super-Resolution: Methods and Results
May 11, 2022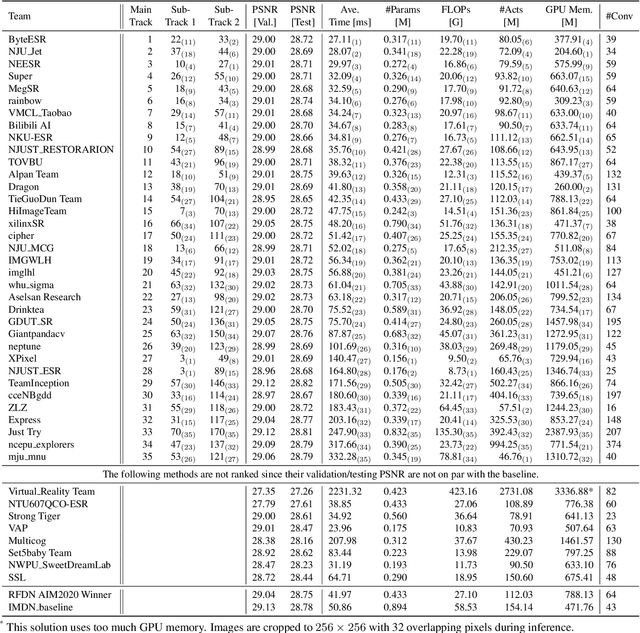
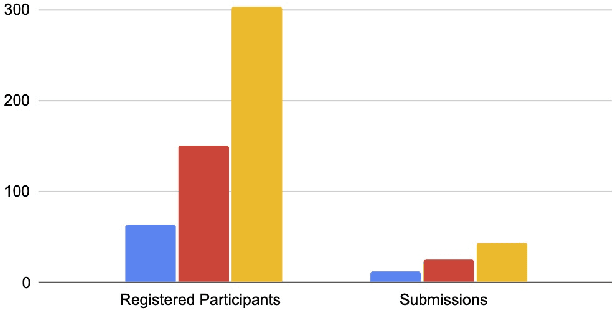
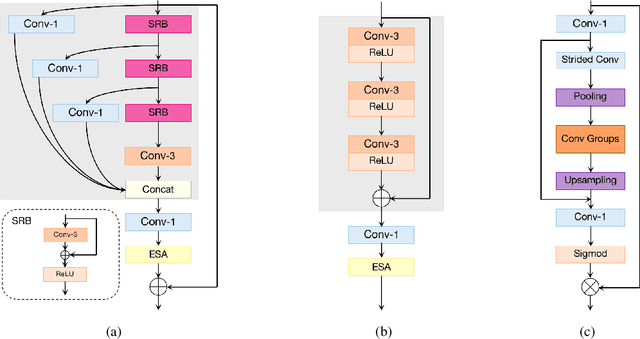
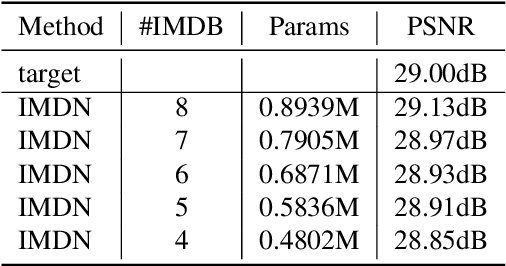
This paper reviews the NTIRE 2022 challenge on efficient single image super-resolution with focus on the proposed solutions and results. The task of the challenge was to super-resolve an input image with a magnification factor of $\times$4 based on pairs of low and corresponding high resolution images. The aim was to design a network for single image super-resolution that achieved improvement of efficiency measured according to several metrics including runtime, parameters, FLOPs, activations, and memory consumption while at least maintaining the PSNR of 29.00dB on DIV2K validation set. IMDN is set as the baseline for efficiency measurement. The challenge had 3 tracks including the main track (runtime), sub-track one (model complexity), and sub-track two (overall performance). In the main track, the practical runtime performance of the submissions was evaluated. The rank of the teams were determined directly by the absolute value of the average runtime on the validation set and test set. In sub-track one, the number of parameters and FLOPs were considered. And the individual rankings of the two metrics were summed up to determine a final ranking in this track. In sub-track two, all of the five metrics mentioned in the description of the challenge including runtime, parameter count, FLOPs, activations, and memory consumption were considered. Similar to sub-track one, the rankings of five metrics were summed up to determine a final ranking. The challenge had 303 registered participants, and 43 teams made valid submissions. They gauge the state-of-the-art in efficient single image super-resolution.
Reciprocal Normalization for Domain Adaptation
Dec 20, 2021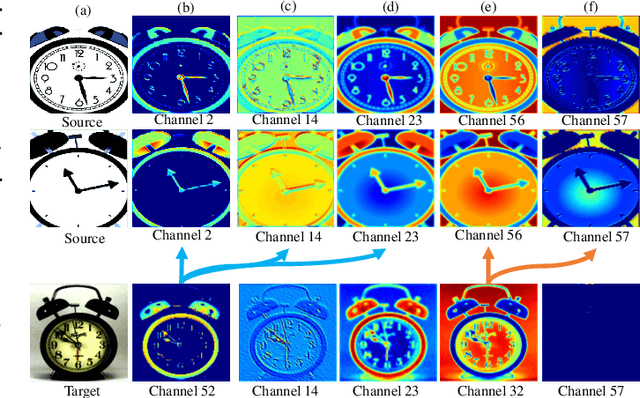
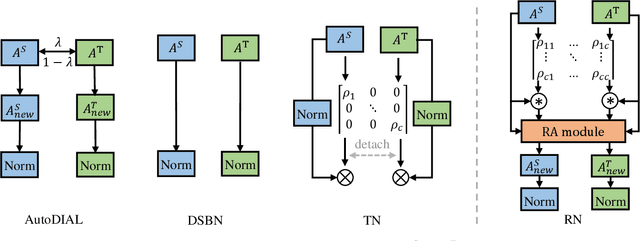
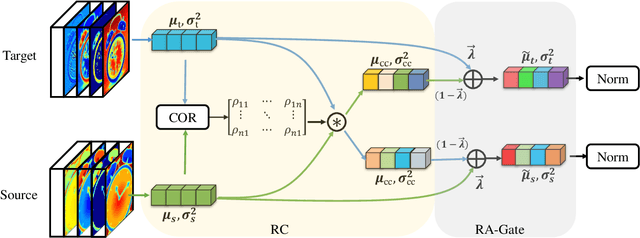
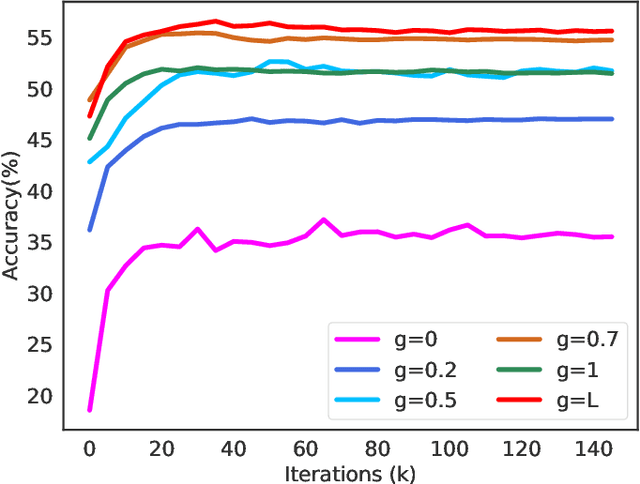
Batch normalization (BN) is widely used in modern deep neural networks, which has been shown to represent the domain-related knowledge, and thus is ineffective for cross-domain tasks like unsupervised domain adaptation (UDA). Existing BN variant methods aggregate source and target domain knowledge in the same channel in normalization module. However, the misalignment between the features of corresponding channels across domains often leads to a sub-optimal transferability. In this paper, we exploit the cross-domain relation and propose a novel normalization method, Reciprocal Normalization (RN). Specifically, RN first presents a Reciprocal Compensation (RC) module to acquire the compensatory for each channel in both domains based on the cross-domain channel-wise correlation. Then RN develops a Reciprocal Aggregation (RA) module to adaptively aggregate the feature with its cross-domain compensatory components. As an alternative to BN, RN is more suitable for UDA problems and can be easily integrated into popular domain adaptation methods. Experiments show that the proposed RN outperforms existing normalization counterparts by a large margin and helps state-of-the-art adaptation approaches achieve better results. The source code is available on https://github.com/Openning07/reciprocal-normalization-for-DA.
Effective Label Propagation for Discriminative Semi-Supervised Domain Adaptation
Dec 04, 2020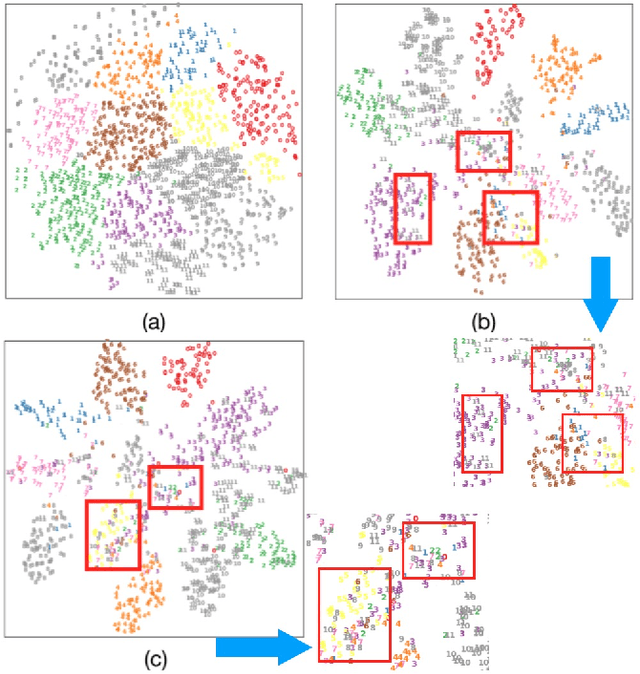
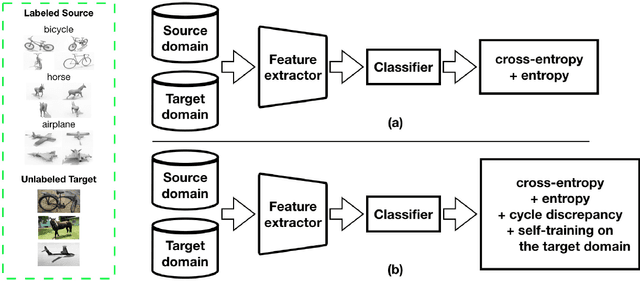
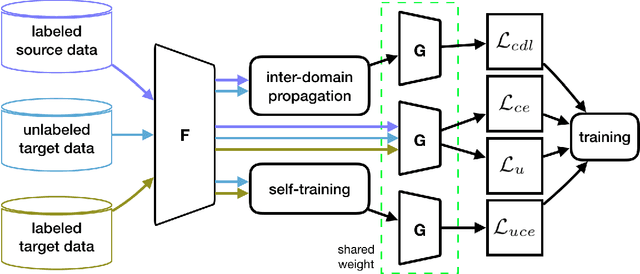
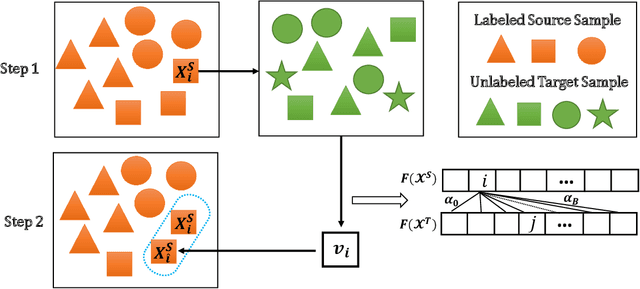
Semi-supervised domain adaptation (SSDA) methods have demonstrated great potential in large-scale image classification tasks when massive labeled data are available in the source domain but very few labeled samples are provided in the target domain. Existing solutions usually focus on feature alignment between the two domains while paying little attention to the discrimination capability of learned representations in the target domain. In this paper, we present a novel and effective method, namely Effective Label Propagation (ELP), to tackle this problem by using effective inter-domain and intra-domain semantic information propagation. For inter-domain propagation, we propose a new cycle discrepancy loss to encourage consistency of semantic information between the two domains. For intra-domain propagation, we propose an effective self-training strategy to mitigate the noises in pseudo-labeled target domain data and improve the feature discriminability in the target domain. As a general method, our ELP can be easily applied to various domain adaptation approaches and can facilitate their feature discrimination in the target domain. Experiments on Office-Home and DomainNet benchmarks show ELP consistently improves the classification accuracy of mainstream SSDA methods by 2%~3%. Additionally, ELP also improves the performance of UDA methods as well (81.5% vs 86.1%), based on UDA experiments on the VisDA-2017 benchmark. Our source code and pre-trained models will be released soon.