 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaming Outlier Tokens in Diffusion Transformers
May 06, 2026We study outlier tokens in Diffusion Transformers (DiTs) for image generation. Prior work has shown that Vision Transformers (ViTs) can produce a small number of high-norm tokens that attract disproportionate attention while carrying limited local information, but their role in generative models remains underexplored. We show that this phenomenon appears in both the encoder and denoiser of modern Representation Autoencoder (RAE)-DiT pipelines: pretrained ViT encoders can produce outlier representations, and DiTs themselves can develop internal outlier tokens, especially in intermediate layers. Moreover, simply masking high-norm tokens does not improve performance, indicating that the problem is not only caused by a few extreme values, but is more closely related to corrupted local patch semantics. To address this issue, we introduce Dual-Stage Registers (DSR), a register-based intervention for both components: trained registers when available, recursive test-time registers otherwise, and diffusion registers for the denoiser. Across ImageNet and large-scale text-to-image generation, these interventions consistently reduce outlier artifacts and improve generation quality. Our results highlight outlier-token control as an important ingredient in building stronger DiTs.
Large Language Models are Universal Reasoners for Visual Generation
May 05, 2026Text-to-image generation has advanced rapidly with diffusion models, progressing from CLIP and T5 conditioning to unified systems where a single LLM backbone handles both visual understanding and generation. Despite the architectural unification, these systems frequently fail to faithfully align complex prompts during synthesis, even though they remain highly accurate at verifying whether an image satisfies those same prompts. We formalize this as the \emph{understanding-generation gap} and propose UniReasoner, a framework that leverages the LLM as a universal reasoner to convert its understanding strength into direct generation guidance. Given a prompt, the LLM first produces a coarse visual draft composed of discrete vision tokens. It then performs a self-critique by evaluating the draft for prompt consistency, producing a grounded textual evaluation that pinpoints what needs to be corrected. Finally, a diffusion model is conditioned jointly on the prompt, the visual draft, and the evaluation, ensuring that generation is guided by explicit corrective signals. Each signal addresses a limitation of the other: the draft provides a concrete, scene-level anchor that reduces under-specification in text-only conditioning, while the evaluation turns verification into grounded, actionable constraints that correct omissions, hallucinations, and relational errors. Experiments show that UniReasoner improves compositional alignment and semantic faithfulness under the same diffusion backbone while maintaining image quality, demonstrating a practical way to exploit LLM reasoning to close the understanding-generation gap.
A Frame is Worth One Token: Efficient Generative World Modeling with Delta Tokens
Apr 06, 2026Anticipating diverse future states is a central challenge in video world modeling. Discriminative world models produce a deterministic prediction that implicitly averages over possible futures, while existing generative world models remain computationally expensive. Recent work demonstrates that predicting the future in the feature space of a vision foundation model (VFM), rather than a latent space optimized for pixel reconstruction, requires significantly fewer world model parameters. However, most such approaches remain discriminative. In this work, we introduce DeltaTok, a tokenizer that encodes the VFM feature difference between consecutive frames into a single continuous "delta" token, and DeltaWorld, a generative world model operating on these tokens to efficiently generate diverse plausible futures. Delta tokens reduce video from a three-dimensional spatio-temporal representation to a one-dimensional temporal sequence, for example yielding a 1,024x token reduction with 512x512 frames. This compact representation enables tractable multi-hypothesis training, where many futures are generated in parallel and only the best is supervised. At inference, this leads to diverse predictions in a single forward pass. Experiments on dense forecasting tasks demonstrate that DeltaWorld forecasts futures that more closely align with real-world outcomes, while having over 35x fewer parameters and using 2,000x fewer FLOPs than existing generative world models. Code and weights: https://deltatok.github.io.
Autoregressive Image Generation with Masked Bit Modeling
Feb 09, 2026This paper challenges the dominance of continuous pipelines in visual generation. We systematically investigate the performance gap between discrete and continuous methods. Contrary to the belief that discrete tokenizers are intrinsically inferior, we demonstrate that the disparity arises primarily from the total number of bits allocated in the latent space (i.e., the compression ratio). We show that scaling up the codebook size effectively bridges this gap, allowing discrete tokenizers to match or surpass their continuous counterparts. However, existing discrete generation methods struggle to capitalize on this insight, suffering from performance degradation or prohibitive training costs with scaled codebook. To address this, we propose masked Bit AutoRegressive modeling (BAR), a scalable framework that supports arbitrary codebook sizes. By equipping an autoregressive transformer with a masked bit modeling head, BAR predicts discrete tokens through progressively generating their constituent bits. BAR achieves a new state-of-the-art gFID of 0.99 on ImageNet-256, outperforming leading methods across both continuous and discrete paradigms, while significantly reducing sampling costs and converging faster than prior continuous approaches. Project page is available at https://bar-gen.github.io/
Grouping First, Attending Smartly: Training-Free Acceleration for Diffusion Transformers
May 20, 2025
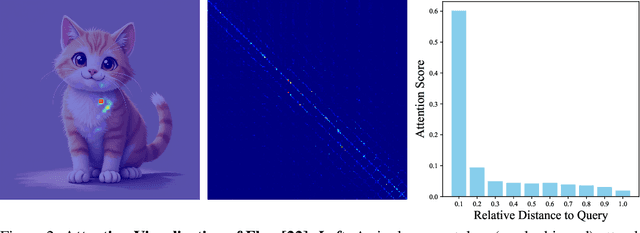
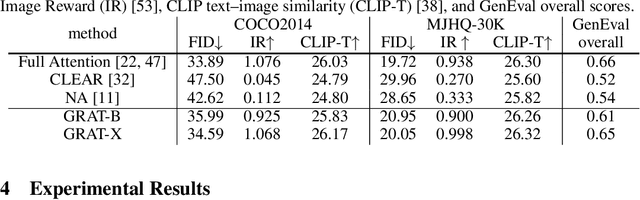
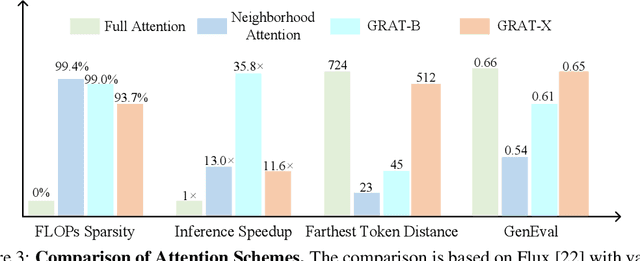
Diffusion-based Transformers have demonstrated impressive generative capabilities, but their high computational costs hinder practical deployment, for example, generating an $8192\times 8192$ image can take over an hour on an A100 GPU. In this work, we propose GRAT (\textbf{GR}ouping first, \textbf{AT}tending smartly), a training-free attention acceleration strategy for fast image and video generation without compromising output quality. The key insight is to exploit the inherent sparsity in learned attention maps (which tend to be locally focused) in pretrained Diffusion Transformers and leverage better GPU parallelism. Specifically, GRAT first partitions contiguous tokens into non-overlapping groups, aligning both with GPU execution patterns and the local attention structures learned in pretrained generative Transformers. It then accelerates attention by having all query tokens within the same group share a common set of attendable key and value tokens. These key and value tokens are further restricted to structured regions, such as surrounding blocks or criss-cross regions, significantly reducing computational overhead (e.g., attaining a \textbf{35.8$\times$} speedup over full attention when generating $8192\times 8192$ images) while preserving essential attention patterns and long-range context. We validate GRAT on pretrained Flux and HunyuanVideo for image and video generation, respectively. In both cases, GRAT achieves substantially faster inference without any fine-tuning, while maintaining the performance of full attention. We hope GRAT will inspire future research on accelerating Diffusion Transformers for scalable visual generation.
ReVision: High-Quality, Low-Cost Video Generation with Explicit 3D Physics Modeling for Complex Motion and Interaction
Apr 30, 2025In recent years, video generation has seen significant advancements. However, challenges still persist in generating complex motions and interactions. To address these challenges, we introduce ReVision, a plug-and-play framework that explicitly integrates parameterized 3D physical knowledge into a pretrained conditional video generation model, significantly enhancing its ability to generate high-quality videos with complex motion and interactions. Specifically, ReVision consists of three stages. First, a video diffusion model is used to generate a coarse video. Next, we extract a set of 2D and 3D features from the coarse video to construct a 3D object-centric representation, which is then refined by our proposed parameterized physical prior model to produce an accurate 3D motion sequence. Finally, this refined motion sequence is fed back into the same video diffusion model as additional conditioning, enabling the generation of motion-consistent videos, even in scenarios involving complex actions and interactions. We validate the effectiveness of our approach on Stable Video Diffusion, where ReVision significantly improves motion fidelity and coherence. Remarkably, with only 1.5B parameters, it even outperforms a state-of-the-art video generation model with over 13B parameters on complex video generation by a substantial margin. Our results suggest that, by incorporating 3D physical knowledge, even a relatively small video diffusion model can generate complex motions and interactions with greater realism and controllability, offering a promising solution for physically plausible video generation.
Deeply Supervised Flow-Based Generative Models
Mar 18, 2025Flow based generative models have charted an impressive path across multiple visual generation tasks by adhering to a simple principle: learning velocity representations of a linear interpolant. However, we observe that training velocity solely from the final layer output underutilizes the rich inter layer representations, potentially impeding model convergence. To address this limitation, we introduce DeepFlow, a novel framework that enhances velocity representation through inter layer communication. DeepFlow partitions transformer layers into balanced branches with deep supervision and inserts a lightweight Velocity Refiner with Acceleration (VeRA) block between adjacent branches, which aligns the intermediate velocity features within transformer blocks. Powered by the improved deep supervision via the internal velocity alignment, DeepFlow converges 8 times faster on ImageNet with equivalent performance and further reduces FID by 2.6 while halving training time compared to previous flow based models without a classifier free guidance. DeepFlow also outperforms baselines in text to image generation tasks, as evidenced by evaluations on MSCOCO and zero shot GenEval.
FlowTok: Flowing Seamlessly Across Text and Image Tokens
Mar 13, 2025Bridging different modalities lies at the heart of cross-modality generation. While conventional approaches treat the text modality as a conditioning signal that gradually guides the denoising process from Gaussian noise to the target image modality, we explore a much simpler paradigm-directly evolving between text and image modalities through flow matching. This requires projecting both modalities into a shared latent space, which poses a significant challenge due to their inherently different representations: text is highly semantic and encoded as 1D tokens, whereas images are spatially redundant and represented as 2D latent embeddings. To address this, we introduce FlowTok, a minimal framework that seamlessly flows across text and images by encoding images into a compact 1D token representation. Compared to prior methods, this design reduces the latent space size by 3.3x at an image resolution of 256, eliminating the need for complex conditioning mechanisms or noise scheduling. Moreover, FlowTok naturally extends to image-to-text generation under the same formulation. With its streamlined architecture centered around compact 1D tokens, FlowTok is highly memory-efficient, requires significantly fewer training resources, and achieves much faster sampling speeds-all while delivering performance comparable to state-of-the-art models. Code will be available at https://github.com/bytedance/1d-tokenizer.
Beyond Next-Token: Next-X Prediction for Autoregressive Visual Generation
Feb 27, 2025Autoregressive (AR) modeling, known for its next-token prediction paradigm, underpins state-of-the-art language and visual generative models. Traditionally, a ``token'' is treated as the smallest prediction unit, often a discrete symbol in language or a quantized patch in vision. However, the optimal token definition for 2D image structures remains an open question. Moreover, AR models suffer from exposure bias, where teacher forcing during training leads to error accumulation at inference. In this paper, we propose xAR, a generalized AR framework that extends the notion of a token to an entity X, which can represent an individual patch token, a cell (a $k\times k$ grouping of neighboring patches), a subsample (a non-local grouping of distant patches), a scale (coarse-to-fine resolution), or even a whole image. Additionally, we reformulate discrete token classification as \textbf{continuous entity regression}, leveraging flow-matching methods at each AR step. This approach conditions training on noisy entities instead of ground truth tokens, leading to Noisy Context Learning, which effectively alleviates exposure bias. As a result, xAR offers two key advantages: (1) it enables flexible prediction units that capture different contextual granularity and spatial structures, and (2) it mitigates exposure bias by avoiding reliance on teacher forcing. On ImageNet-256 generation benchmark, our base model, xAR-B (172M), outperforms DiT-XL/SiT-XL (675M) while achieving 20$\times$ faster inference. Meanwhile, xAR-H sets a new state-of-the-art with an FID of 1.24, running 2.2$\times$ faster than the previous best-performing model without relying on vision foundation modules (\eg, DINOv2) or advanced guidance interval sampling.
COCONut-PanCap: Joint Panoptic Segmentation and Grounded Captions for Fine-Grained Understanding and Generation
Feb 04, 2025This paper introduces the COCONut-PanCap dataset, created to enhance panoptic segmentation and grounded image captioning. Building upon the COCO dataset with advanced COCONut panoptic masks, this dataset aims to overcome limitations in existing image-text datasets that often lack detailed, scene-comprehensive descriptions. The COCONut-PanCap dataset incorporates fine-grained, region-level captions grounded in panoptic segmentation masks, ensuring consistency and improving the detail of generated captions. Through human-edited, densely annotated descriptions, COCONut-PanCap supports improved training of vision-language models (VLMs) for image understanding and generative models for text-to-image tasks. Experimental results demonstrate that COCONut-PanCap significantly boosts performance across understanding and generation tasks, offering complementary benefits to large-scale datasets. This dataset sets a new benchmark for evaluating models on joint panoptic segmentation and grounded captioning tasks, addressing the need for high-quality, detailed image-text annotations in multi-modal learning.