 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoNVS: Geometry Grounded Video Diffusion for Novel View Synthesis
Mar 16, 2026Novel view synthesis requires strong 3D geometric consistency and the ability to generate visually coherent images across diverse viewpoints. While recent camera-controlled video diffusion models show promising results, they often suffer from geometric distortions and limited camera controllability. To overcome these challenges, we introduce GeoNVS, a geometry-grounded novel-view synthesizer that enhances both geometric fidelity and camera controllability through explicit 3D geometric guidance. Our key innovation is the Gaussian Splat Feature Adapter (GS-Adapter), which lifts input-view diffusion features into 3D Gaussian representations, renders geometry-constrained novel-view features, and adaptively fuses them with diffusion features to correct geometrically inconsistent representations. Unlike prior methods that inject geometry at the input level, GS-Adapter operates in feature space, avoiding view-dependent color noise that degrades structural consistency. Its plug-and-play design enables zero-shot compatibility with diverse feed-forward geometry models without additional training, and can be adapted to other video diffusion backbones. Experiments across 9 scenes and 18 settings demonstrate state-of-the-art performance, achieving 11.3% and 14.9% improvements over SEVA and CameraCtrl, with up to 2x reduction in translation error and 7x in Chamfer Distance.
Deeply Supervised Flow-Based Generative Models
Mar 18, 2025Flow based generative models have charted an impressive path across multiple visual generation tasks by adhering to a simple principle: learning velocity representations of a linear interpolant. However, we observe that training velocity solely from the final layer output underutilizes the rich inter layer representations, potentially impeding model convergence. To address this limitation, we introduce DeepFlow, a novel framework that enhances velocity representation through inter layer communication. DeepFlow partitions transformer layers into balanced branches with deep supervision and inserts a lightweight Velocity Refiner with Acceleration (VeRA) block between adjacent branches, which aligns the intermediate velocity features within transformer blocks. Powered by the improved deep supervision via the internal velocity alignment, DeepFlow converges 8 times faster on ImageNet with equivalent performance and further reduces FID by 2.6 while halving training time compared to previous flow based models without a classifier free guidance. DeepFlow also outperforms baselines in text to image generation tasks, as evidenced by evaluations on MSCOCO and zero shot GenEval.
Enhancing Temporal Consistency in Video Editing by Reconstructing Videos with 3D Gaussian Splatting
Jun 04, 2024



Recent advancements in zero-shot video diffusion models have shown promise for text-driven video editing, but challenges remain in achieving high temporal consistency. To address this, we introduce Video-3DGS, a 3D Gaussian Splatting (3DGS)-based video refiner designed to enhance temporal consistency in zero-shot video editors. Our approach utilizes a two-stage 3D Gaussian optimizing process tailored for editing dynamic monocular videos. In the first stage, Video-3DGS employs an improved version of COLMAP, referred to as MC-COLMAP, which processes original videos using a Masked and Clipped approach. For each video clip, MC-COLMAP generates the point clouds for dynamic foreground objects and complex backgrounds. These point clouds are utilized to initialize two sets of 3D Gaussians (Frg-3DGS and Bkg-3DGS) aiming to represent foreground and background views. Both foreground and background views are then merged with a 2D learnable parameter map to reconstruct full views. In the second stage, we leverage the reconstruction ability developed in the first stage to impose the temporal constraints on the video diffusion model. To demonstrate the efficacy of Video-3DGS on both stages, we conduct extensive experiments across two related tasks: Video Reconstruction and Video Editing. Video-3DGS trained with 3k iterations significantly improves video reconstruction quality (+3 PSNR, +7 PSNR increase) and training efficiency (x1.9, x4.5 times faster) over NeRF-based and 3DGS-based state-of-art methods on DAVIS dataset, respectively. Moreover, it enhances video editing by ensuring temporal consistency across 58 dynamic monocular videos.
MTMMC: A Large-Scale Real-World Multi-Modal Camera Tracking Benchmark
Mar 29, 2024Multi-target multi-camera tracking is a crucial task that involves identifying and tracking individuals over time using video streams from multiple cameras. This task has practical applications in various fields, such as visual surveillance, crowd behavior analysis, and anomaly detection. However, due to the difficulty and cost of collecting and labeling data, existing datasets for this task are either synthetically generated or artificially constructed within a controlled camera network setting, which limits their ability to model real-world dynamics and generalize to diverse camera configurations. To address this issue, we present MTMMC, a real-world, large-scale dataset that includes long video sequences captured by 16 multi-modal cameras in two different environments - campus and factory - across various time, weather, and season conditions. This dataset provides a challenging test-bed for studying multi-camera tracking under diverse real-world complexities and includes an additional input modality of spatially aligned and temporally synchronized RGB and thermal cameras, which enhances the accuracy of multi-camera tracking. MTMMC is a super-set of existing datasets, benefiting independent fields such as person detection, re-identification, and multiple object tracking. We provide baselines and new learning setups on this dataset and set the reference scores for future studies. The datasets, models, and test server will be made publicly available.
MaXTron: Mask Transformer with Trajectory Attention for Video Panoptic Segmentation
Nov 30, 2023Video panoptic segmentation requires consistently segmenting (for both `thing' and `stuff' classes) and tracking objects in a video over time. In this work, we present MaXTron, a general framework that exploits Mask XFormer with Trajectory Attention to tackle the task. MaXTron enriches an off-the-shelf mask transformer by leveraging trajectory attention. The deployed mask transformer takes as input a short clip consisting of only a few frames and predicts the clip-level segmentation. To enhance the temporal consistency, MaXTron employs within-clip and cross-clip tracking modules, efficiently utilizing trajectory attention. Originally designed for video classification, trajectory attention learns to model the temporal correspondences between neighboring frames and aggregates information along the estimated motion paths. However, it is nontrivial to directly extend trajectory attention to the per-pixel dense prediction tasks due to its quadratic dependency on input size. To alleviate the issue, we propose to adapt the trajectory attention for both the dense pixel features and object queries, aiming to improve the short-term and long-term tracking results, respectively. Particularly, in our within-clip tracking module, we propose axial-trajectory attention that effectively computes the trajectory attention for tracking dense pixels sequentially along the height- and width-axes. The axial decomposition significantly reduces the computational complexity for dense pixel features. In our cross-clip tracking module, since the object queries in mask transformer are learned to encode the object information, we are able to capture the long-term temporal connections by applying trajectory attention to object queries, which learns to track each object across different clips. Without bells and whistles, MaXTron demonstrates state-of-the-art performances on video segmentation benchmarks.
Video-kMaX: A Simple Unified Approach for Online and Near-Online Video Panoptic Segmentation
Apr 10, 2023Video Panoptic Segmentation (VPS) aims to achieve comprehensive pixel-level scene understanding by segmenting all pixels and associating objects in a video. Current solutions can be categorized into online and near-online approaches. Evolving over the time, each category has its own specialized designs, making it nontrivial to adapt models between different categories. To alleviate the discrepancy, in this work, we propose a unified approach for online and near-online VPS. The meta architecture of the proposed Video-kMaX consists of two components: within clip segmenter (for clip-level segmentation) and cross-clip associater (for association beyond clips). We propose clip-kMaX (clip k-means mask transformer) and HiLA-MB (Hierarchical Location-Aware Memory Buffer) to instantiate the segmenter and associater, respectively. Our general formulation includes the online scenario as a special case by adopting clip length of one. Without bells and whistles, Video-kMaX sets a new state-of-the-art on KITTI-STEP and VIPSeg for video panoptic segmentation, and VSPW for video semantic segmentation. Code will be made publicly available.
TTA-COPE: Test-Time Adaptation for Category-Level Object Pose Estimation
Mar 29, 2023
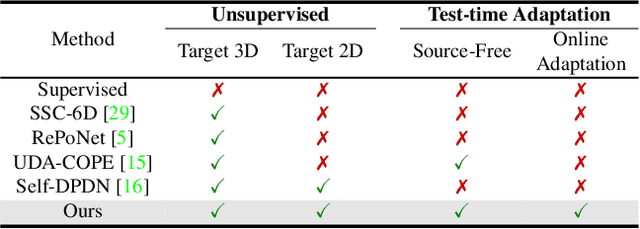
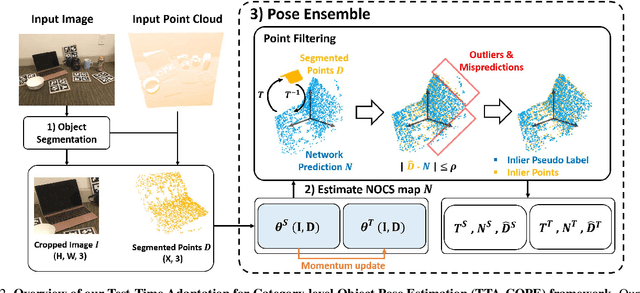
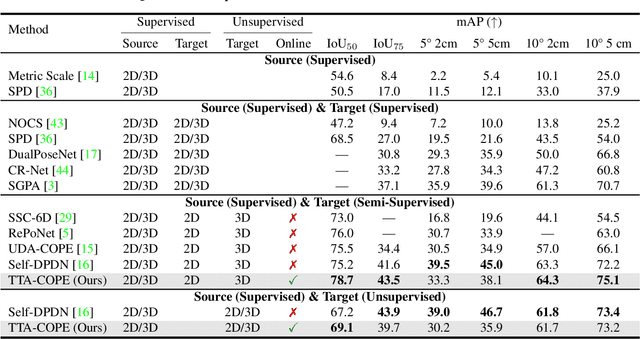
Test-time adaptation methods have been gaining attention recently as a practical solution for addressing source-to-target domain gaps by gradually updating the model without requiring labels on the target data. In this paper, we propose a method of test-time adaptation for category-level object pose estimation called TTA-COPE. We design a pose ensemble approach with a self-training loss using pose-aware confidence. Unlike previous unsupervised domain adaptation methods for category-level object pose estimation, our approach processes the test data in a sequential, online manner, and it does not require access to the source domain at runtime. Extensive experimental results demonstrate that the proposed pose ensemble and the self-training loss improve category-level object pose performance during test time under both semi-supervised and unsupervised settings. Project page: https://taeyeop.com/ttacope
Bidirectional Domain Mixup for Domain Adaptive Semantic Segmentation
Mar 17, 2023



Mixup provides interpolated training samples and allows the model to obtain smoother decision boundaries for better generalization. The idea can be naturally applied to the domain adaptation task, where we can mix the source and target samples to obtain domain-mixed samples for better adaptation. However, the extension of the idea from classification to segmentation (i.e., structured output) is nontrivial. This paper systematically studies the impact of mixup under the domain adaptaive semantic segmentation task and presents a simple yet effective mixup strategy called Bidirectional Domain Mixup (BDM). In specific, we achieve domain mixup in two-step: cut and paste. Given the warm-up model trained from any adaptation techniques, we forward the source and target samples and perform a simple threshold-based cut out of the unconfident regions (cut). After then, we fill-in the dropped regions with the other domain region patches (paste). In doing so, we jointly consider class distribution, spatial structure, and pseudo label confidence. Based on our analysis, we found that BDM leaves domain transferable regions by cutting, balances the dataset-level class distribution while preserving natural scene context by pasting. We coupled our proposal with various state-of-the-art adaptation models and observe significant improvement consistently. We also provide extensive ablation experiments to empirically verify our main components of the framework. Visit our project page with the code at https://sites.google.com/view/bidirectional-domain-mixup
Learning Classifiers of Prototypes and Reciprocal Points for Universal Domain Adaptation
Dec 16, 2022



Universal Domain Adaptation aims to transfer the knowledge between the datasets by handling two shifts: domain-shift and category-shift. The main challenge is correctly distinguishing the unknown target samples while adapting the distribution of known class knowledge from source to target. Most existing methods approach this problem by first training the target adapted known classifier and then relying on the single threshold to distinguish unknown target samples. However, this simple threshold-based approach prevents the model from considering the underlying complexities existing between the known and unknown samples in the high-dimensional feature space. In this paper, we propose a new approach in which we use two sets of feature points, namely dual Classifiers for Prototypes and Reciprocals (CPR). Our key idea is to associate each prototype with corresponding known class features while pushing the reciprocals apart from these prototypes to locate them in the potential unknown feature space. The target samples are then classified as unknown if they fall near any reciprocals at test time. To successfully train our framework, we collect the partial, confident target samples that are classified as known or unknown through on our proposed multi-criteria selection. We then additionally apply the entropy loss regularization to them. For further adaptation, we also apply standard consistency regularization that matches the predictions of two different views of the input to make more compact target feature space. We evaluate our proposal, CPR, on three standard benchmarks and achieve comparable or new state-of-the-art results. We also provide extensive ablation experiments to verify our main design choices in our framework.
CD-TTA: Compound Domain Test-time Adaptation for Semantic Segmentation
Dec 16, 2022



Test-time adaptation (TTA) has attracted significant attention due to its practical properties which enable the adaptation of a pre-trained model to a new domain with only target dataset during the inference stage. Prior works on TTA assume that the target dataset comes from the same distribution and thus constitutes a single homogeneous domain. In practice, however, the target domain can contain multiple homogeneous domains which are sufficiently distinctive from each other and those multiple domains might occur cyclically. Our preliminary investigation shows that domain-specific TTA outperforms vanilla TTA treating compound domain (CD) as a single one. However, domain labels are not available for CD, which makes domain-specific TTA not practicable. To this end, we propose an online clustering algorithm for finding pseudo-domain labels to obtain similar benefits as domain-specific configuration and accumulating knowledge of cyclic domains effectively. Moreover, we observe that there is a significant discrepancy in terms of prediction quality among samples, especially in the CD context. This further motivates us to boost its performance with gradient denoising by considering the image-wise similarity with the source distribution. Overall, the key contribution of our work lies in proposing a highly significant new task compound domain test-time adaptation (CD-TTA) on semantic segmentation as well as providing a strong baseline to facilitate future works to benchmark.